Синтезатор речи что такое: Топ-17 синтезаторов речи | Озвучка текста онлайн, на телефоне и ПК
5 лучших синтезаторов речи с русскими голосами
Все чаще в повседневной жизни стали использовать синтезаторы речи. Синтезаторы речи, как становится видно уже по одному названию, осуществляют синтез речи, то есть форматируют письменный текст в устный.
Благодаря этому можно учить новые иностранные слова с правильным произношением, читать книги не отвлекаясь от своих дел или, например, находясь в транспорте. Изначально разработкой таких программ занимались организации, специализирующиеся на технике для людей с проблемами зрения.
Сейчас же, любой пользователь может скачать одну из программ, установить ее на свой компьютер или телефон и синтезировать речь, в том числе и русскую.
Для этого было разработано множество различных программ, приложенный и даже целых систем. К сожалению, не все из них предназначены для русскоязычной аудитории.
Содержание статьи:
Список синтезаторов речи:
1. Acapela
Acapela — один из самых распространенных речевых синтезаторов во всем мире. Программа распознает и озвучивает тексты более, чем на тридцати языках. Русский язык поддерживается двумя голосами: мужской голос — Николай, женский — Алена.
Женский голос появился значительно позднее мужского и является более усовершенствованным.
Прослушать, как звучат голоса, можно на официальном сайте программы. Достаточно лишь выбрать язык и голос, и набрать свой небольшой текст.
Кстати, для мужского голоса был разработан отдельный словарь ударений, что позволяет достичь еще большей четкости произношения.
Установка программы проходит без проблем. Разработаны версии для операционных систем Windows, Linux, Mac, а также для мобильных ОС Android u IOS.
Программа платная, скачать ее можно с официального сайта Acapela.
2. Vokalizer
Вторым в нашем списке, но не по популярности является движок Милена от разработчика программы Vocalizer компании Nuance.
Голос звучит очень естественно, речь чистая. Есть возможность установить различные словари, а также подкорректировать громкость, скорость и ударение, что не маловажно.
Как и в случае с Акапелой, программа имеет различные версии для мобильных, автомобильных и компьютерных приложений. Прекрасно подходит для чтения книг.
Скачать все версии Vokalizer и русскоязычный движок Милена можно на официальном сайте производителя программы.
3. RHVoice
Синтезатор речи RHVoice был разработан Ольгой Яковлевой. Программа озвучивает русские тексты тремя голосами: Елена, Ирина и Александр. Подробнее об установке и применении, а также прослушать голоса Вы сможете в прошлой статье
Код синтезатора открыт для всех, программы же абсолютно бесплатны.
RHVoice выпущена в двух вариантах: как отдельная программа, так и как приложение к NVDA.
Все версии можно скачать с официального сайта разработчика.
4. ESpeak
Первая версия бесплатного синтезатора речи eSpeak была выпущена в 2006 году. С тех пор компания-разработчик постоянно выпускает все более усовершенствованные версии. Последняя версия была представлена в конце весны две тысячи тринадцатого года.
eSpeak можно установить под следующие операционные системы:
- Microsoft Windows,
- Mac OS X,
- Linux,
- RISC OS
Возможна также компиляция кода для Windows Mobile, но делать ее придется самостоятельно.
А вот с мобильной ОС Android программа работает без проблем, хотя русские словари еще не до конца разработаны. Русскоязычных голосов много, можно выбрать на свой вкус.
Для разработчиков будет интересно узнать, что C++ код программы доступен в сети. Скачать программу, а также посмотреть ее код можно на официальном сайте.
5. Festival
Festival — это целая система распознавания и синтеза речи, которая была разработана в эдинбургском университете.
Программы и все модули абсолютно бесплатно и распространяются по системе open source. Скачать их и ознакомиться с демо-версиями можно на официальном сайте университета Эдинбурга.
Русский голос представлен в одном варианте, но звучание довольно хорошее и ясное, без акцента и с правильной расстановкой ударений.
К сожалению, программа пока может быть установлена только в среде API, Linux. Также есть модуль для работы в Mac OS, но русский язык пока поддерживается не очень хорошо.
Вместо послесловия
Стоит отметить, что любой из вышеприведённых синтезаторов отлично исполнен, но выбор программы индивидуален. Всё объясняется различным произношением голосов. Смею посоветовать второй вариант с голосом Милена. ОЧень выразительный голос, насыщенное звучание и приятная во всех смыслах интонация голоса!
поделитесь с друзьями:
ВКонтакте
OK
Выбираем голосовой синтезатор речи с русским голосом

Недавно передо мной встала проблема выбора голосового синтезатора речи. Основные требования — это поддержка русского языка и более-менее нормальное произношение.
Для тех, кто не в курсе того, что такое синтезатор речи, расскажу — это специальная программа, смысл работы которой заключается в преобразовании письменного текста в устную речь. Это и есть так называемый синтез.
Зачем это надо? Ну, например, когда надо записать голосовое сообщение чужим голосом. Иностранцам оно может быть полезно для того, чтобы услышать произношение того или иного слова. Синтезатор речи удобен для чтения, когда надо включить ребенку сказку, которой нет в аудиокнигах. Да и вообще, ситуации всякие бывают.
Так вот, в процессе выбора я нашел несколько очень полезных инструментов, среди которых работающих в режиме онлайн с поддержкой русского языка и сейчас я Вам о них и расскажу.
Переводчик Google
Вот поистине многоцелевой продукт, которых можно использовать совершенно по-разному. Главные преимущества:
— это совершенно бесплатный сервис;
— работа в режиме Онлайн без установки. Нужен только доступ в Интернет;
— на мой взгляд этот синтезатор речи имеет лучший голосовой модуль, самое близкое к натуральному;
— наверное самая лучшая команда разработчиков и техподдержка в мире;
— самое большое количество поддерживаемых языков.
К сожалению, вариант голоса только один — женский. Выбора я не нашел.
RHVoice

Отличный многоязычный синтезатор речи от российского разработчика — Ольги Яковлевой. Есть версии, как для операционных систем семейства Windows, так и для Linux. Разработчик синтезатора — Ольга Яковлева. Программа распространяется совершенно бесплатно и доступна на официальном сайте в двух вариантах: как SAPI5-совместимая самостоятельная версия и как модуль для бесплатной программы экранного доступа NVDA. Этот синтезатор голосовой речи умеет озвучивать русские тексты тремя голосами — Елена, Ирина и Александр.
Acapela

Acapela — это, пожалуй, один из самых популярных и распространенных голосовых синтезаторов в мире. Главная особенность — это озвучка текстов более чем на тридцати языках мира. Если рассматривать русский язык, то тут доступны два голоса — Николай и Алена. Причем последний более совершенен и естественен в плане произношения. В демонстрационном режиме на сайте доступен только голос Алена.
Программа доступна для скачивания на официальном сайте и поддерживает все популярные современные операционные системы — Windows, Linux, Mac. Есть даже версии для Android u iOS.
Vokalizer

Женских голос Milena — это ещё один очень популярный движок голосового синтезатора речи от компании Nuance — он очень высококачественный и естественно звучащий. Его Вы можете услышать в call-центрах и в различных сетевых речевых системах, а также в различных приложениях приложениях — таких как Moon+ Reader Pro, Full Screen Caller ID , Cool Reader, в навигационной программах TomTom, iGo Primo.
Среди плюсов можно отметить возможность установки различных словарей, регулировки громкости, ударения и скорости чтения.
Код программы открытый, скачать его бесплатно можно на официальном сайте, собственно как и инсталлятор самой программы.
Festival

Festival — это не просто очередной голосовой речевой синтезатор, а уже целая система распознавания и синтеза речи с различными API. Разработчик — Исследовательский Центр Речевых Технологий университета Эдинбурга.
Festival предназначен для поддержки нескольких языков. По умолчанию поддерживает английский, валлийский и испанский языки. Но есть возможность подключить голосовые пакеты других языков: чешский, финский, хинди, итальянский, маратхи, польский, русский и телугу.
Код программы открытый, сам голосовой синтезатор распространяется по лицензии open source и доступна только для операционных систем Linux. Правда есть портированная версия по Макинтош.
ESpeak

Последняя в моём обзоре система синтеза речи — программа ESpeak — разрабатывается уже около 8 лет. Последняя версия — 1.48.04 от 6 апреля 2014. Данный голосовой синтезатор речи кроссплатформенный — есть версии под Windows, Linux, Mac OS X, и даже под RISC OS, хотя последние две уже давно не поддерживаются.
Отдельно отмечу, что eSpeak используется в мобильных операционных системах Android, правда имеет при этом ряд существенных ошибок.
Программа поддерживает пятидесяти различных языков, поддержка которых указывается при установке программы.
Один из главных минусов это голосового синтезатора — генерирование голоса только в файл формата WAV. Скачать программу бесплатно можно на официальном сайте.
От себя добавлю лишь, что мне понравились RHVoice и Vokalizer, хотя тут во много дело индивидуальное и во многом зависит от того, что Вы хотите получить. Так что пробуйте, ставьте и смотрите. Я думаю, что один из представленных вариантов Вам обязательно должен подойти.
эпоха электрических решений / Блог компании Аудиомания / Хабр
В прошлый раз мы рассказывали о механических устройствах для синтеза речи — голосовом тракте Кемпелена и «говорящей голове» Иосифа Фабера. На очереди электрические синтезаторы XX века.
Фото Rock’n Roll Monkey / Unsplash
Первые электрические установки
В 1850 году немецкий физик и врач-физиолог Герман фон Гельмгольц представил свою резонаторную теорию. Он заметил, что у гласных звуков разные резонансные частоты (форманты). Эти форманты образуются при прохождении звуковой волны от голосовых связок к губам. Некоторые волны отражаются от губ говорящего и идут к реципиенту, а часть — возвращается к источнику. Ученый предположил, что голосовой тракт человека можно представить как последовательность резонаторов.
В начале XX века начались попытки реализовать такую модель на основе электрических компонентов. Первый синтезатор такого типа разработал физик Джон Стюарт. Его схема (опубликованная в журнале Nature), включала в себя электрический зуммер для моделирования связок и пару индуктивно-емкостных резонаторов. Они эмулировали физические процессы, происходящие со звуком в горле.
Схема синтезатора, разработанного Джоном Стюартом
Устройство Стюарта могло издавать звуки, состоящие из двух формант. Это — несколько простых гласных, а также дифтонги. Но на этом его возможности заканчивались.
Первый электрический синтезатор, способный воспроизводить речь появился позже — в 1930 годах. Его разработал Гомер Дадли (Homer Dudley) из Bell Laboratories. В то время компания работала над вокодером — инструментом для сжатия речи и экономии частотных ресурсов радиолинии в телефонных сетях. Идея заключалась в том, чтобы вместо голоса абонента передавать его ключевые параметры. На принимающей стороне устанавливался специальный декодер, который по этим параметрам реконструировал и воспроизводил звук. Дадли понял, что с небольшими модификациями вокодер можно превратить в полноценный синтезатор. Так появилась система VODER — Voice Operating Demonstrator.
Устройство представили широкой публике на нью-йоркской всемирной выставке в 1939 году. В конструкцию VODER входили два источника звука: ламповый генератор шума для «глухих» фонем, и осциллятор — для «звонких». Также имелись десять параллельно соединенных полосовых фильтров — они составляли блок управления резонансами. Оператор руководил системой с помощью ручной клавиатуры, браслета на запястье и ножной педали.
Во время демонстраций аппарат говорил на разных языках, пел и отвечал на вопросы с различными интонациями. Но чтобы раскрыть потенциал системы, её оператору требовались годы тренировок.
Вскоре после премьеры VODER началась Вторая мировая война, и Bell Labs пришлось свернуть дальнейшую разработку синтезатора. Однако знания, полученные во время работы над проектом, Гомер Дадли использовал для создания технологии шифрования телефонных разговоров.
Синтезаторы речи на спектрограммах
В 1946 году был изобретен акустический спектрограф. И возникла идея — использовать спектрограммы для управления речевыми синтезаторами. Одним из первых такое устройство представил Л. Шотт (L. Schott), американский инженер из Bell Labs. Он использовал линейный источник света, просвечивающий спектрографические шаблоны с разной степенью прозрачности. Специальные фотоэлементы, установленные напротив лампы, регистрировали изменения уровня освещенности и генерировали управляющие сигналы для полосовых фильтров. Точно такие же фильтры использовал Гомер Дадли для своего VODER.
Фото 120years.net
Другую разработку в этой области представила группа американских ученых во главе с физиком Франклином Купером (Franklin Cooper). Их оптическая система — Pattern Playback — модулировала гармоники основного тона 120 Гц, считывая изображения на движущейся прозрачной ленте. Визуальная информация передавалась осциллятору, превращавшему её в звук.
В каком-то смысле система напоминала советские оптические синтезаторы — «Нивотон» и «Вариофон» — на которых писали музыку для мультфильмов. Однако Pattern Playback был изначально «заточен» под генерацию человеческой речи и умел воспроизводить целые предложения.
Устройства, подобные Pattern Playback и VODER, построили теоретический фундамент для проектирования формантных и артикуляционных синтезаторов. Они стали прототипом современного компьютерного синтеза. О них мы расскажем в следующий раз.
Материалы по теме из нашего «Мира Hi-Fi»:
История аудиотехнологий: синтезаторы и сэмплеры
Траутониум: немецкая волна в истории синтезаторов
Музыка из бумаги и картона: краткая история вариофона и «рисованного звука»
«Машинный звук»: синтезаторы на базе нейросетей
Звук на проволоке: история телеграфона
Что такое синтезатор речи?
- Дата
- Категория: it
Компьютеры, оборудованные синтезаторами речи, могут имитировать человеческую речь, хотя производимые ими звуки подчас звучат неестественно для человеческого уха. Ранние синтезаторы голоса были основаны на гармошках, язычках (вибрирующие пластинки) и трубках, но теперь звуки производят компьютеры, работающие на электронных схемах.
Чтобы компьютер заговорил, ему нужно задать фразу и «научить», как ее произносить. Синтезаторы речи снабжены двумя источниками звука, один для гласных, другой для согласных. Они производят звуковые волны, которые различаются по музыкальному тону, громкости и интонации. Затем волны проходят через фильтр, соответствующий речевому аппарату человека, после чего звуки компьютера становятся похожими на слова.
Волшебство человеческой речи
Слова, берущие начало в мыслях, произносятся только после сложной последовательности действий, в которую вовлечены многие органы человеческого тела. К тому же, прежде чем произвести мысль, мозг должен обработать большое количество информации. Звуки получаются, когда воздух из легких проходит через голосовую щель в верхней части гортани, заставляя вибрировать голосовые связки. Качество звука зависит от формы полости рта, положения языка, движения губ и способа дыхания.
Первый синтезатор речи
Этот прибор, построенный более двухсот лет назад, имитировал человеческий голос. Он мог производить 29 согласных и 5 гласных звуков. Поскольку резонатором было трудно управлять, то хорошее качество тона оставалось недоступным.
Гармошки соответствуют легким человека, язычки — голосовым связкам, а кожаный резонатор — гортани. Специальные язычки предназначались для извлечения звуков «с» и «ш».
Компьютерный голос
На диаграмме показано, как говорит компьютер. Компьютер идентифицирует каждую звуковую единицу в слове, запоминает ее и транскрибирует (записывает) как фонетический символ. Выделенные курсивом гласные обозначают ударение.
Образование звуков речи
Фильтр смягчает форму волны, чтобы произвести более правдоподобный звук. Импульсный сигнал генерирует гласный звук (внизу). Статический сигнал производит согласный звук (сверху).
ТОП синтезаторов речи с русскими голосами онлайн/оффлайн
Синтезированная речь уже давно окружает нас, она звучит их телефона, из телевизора, из ютуба и инстаграмма. А что удивительно многим людям синтезированная речь действительно нравится или по крайней мере не вызывает негативных эмоций. В данной статье мы подробно расскажем при помощи каких инструментов можно синтезировать речь на русском языке.
Содержание:
Кстати, авто данной статьи чаще всего использует синтезаторы речи для прослушивания книг и для поиска по интернету, да-да, это то-самое «Ok, google!»
Благодаря этому можно учить новые иностранные слова с правильным произношением, читать книги не отвлекаясь от своих дел или, например, находясь в транспорте. Изначально разработкой таких программ занимались организации, специализирующиеся на технике для людей с проблемами зрения.
Сейчас же, любой пользователь может скачать одну из программ, установить ее на свой компьютер или телефон и синтезировать речь, в том числе и русскую.

Для чего чаще всего применяют синтезатор речи
Программный синтез речи – это создание звука на основе написанного текста. Современные разработчики выполняют эту задачу в своих продуктах двумя известными способами:
- Монтируют фрагменты аудиозаписи. Это конкатенативный подход, применяемый в начальных версиях синтезатора Siri.
- Создают вероятностную модель, которая может предсказать акустические свойства того или иного записанного текста. Данный подход именуется параметрическим синтезом речи.
Параметрические модели обладают более развитым искусственным интеллектом, используют сравнительно небольшое количество информации и способны генерировать различные интонации. Сегодня синтезированная речь практически не отличается от естественного человеческого произношения.
Эти программы успешно применяются для изучения новых иностранных слов, чтения книг без отвлечения от повседневных дел, полноценной работы пользователей с серьезными нарушениями зрения.

ТОП лучших синтезаторов речи на ПК
Лучшие программы поддерживают огромное количество распространенных языков, в том числе они подойдут и русскоязычным пользователям.
Voice Reader 15
Этот синтезатор речи Android использует встроенную систему TTS мобильной платформы для чтения электронных писем, текста из буфера обмена, сохраняет статьи для будущего прослушивания, создает списки статей для непрерывного воспроизведения. Возможность синхронизации с Dropbox дает возможность пользователю прослушивать документы, сохраненные в облачном сервисе. Слушатель может регулировать громкость, скорость и тембр чтения, останавливать и возобновлять его механическими кнопками гарнитуры.
Ivona Эта программа читает текст вслух прямо с экрана мобильного устройства с разной скоростью и несколькими голосами. Чтение текста возможно из любых текстовых файлов, программ и браузеров. Программа может преобразовывать текстовый файл в формат mp3, читать письма и Rss-ленты, поддерживает SAPI5-голоса, синтезирует речь для множества языков. Доступны настройки громкости и скорости чтения.
Эта программа читает текст вслух прямо с экрана мобильного устройства с разной скоростью и несколькими голосами. Чтение текста возможно из любых текстовых файлов, программ и браузеров. Программа может преобразовывать текстовый файл в формат mp3, читать письма и Rss-ленты, поддерживает SAPI5-голоса, синтезирует речь для множества языков. Доступны настройки громкости и скорости чтения.
ГОЛОС
Голос – это синтезатор речи, работающий с текстами на русском украинском языках. В программе можно настраивать частоту, тембр и скорость голоса. Приложение может читать текст из буфера обмена, создавать аудиокниги в форматах mp3 и wav, менять размер шрифта, хранить в памяти несколько десятков текстов и последние настройки. Программа Voice оснащена дополнительными опциями для незрячих и слабовидящих пользователей. Текст для синтеза загружается в окно редактора. «Голос» способен распознать до семи текстовых форматов.
Vocalizer
Этот синтезатор не встраивается в системную TTS Android и может использоваться исключительно русскоязычной локализацией Code factory. Программа быстро откликается, обладает достойным качеством звучания. Но движок синтезатора встроен в конкретное приложение, что сужает возможности пользователя и заставляет его работать в ограниченной среде. Но данная особенность имеет и положительные стороны. Например, программу можно более тонко настроить, отрегулировать чтение пунктуационных знаков или фонетическое произношение символов. Латинский текст читается с редкими ошибками в произношении, но всегда грамматически верно.
ESpeak Синтезатор от разработчиков специального ПО для Android оказался довольно мощны некоммерческим продуктом с широким набором функций, но русскоязычных пользователей он может разочаровать. Приложение не может прочитать слова на русском в верхнем регистре, а длинные строки из кириллических символов разбивает на маленькие фрагменты. Некоторые из таких фрагментов состоят всего из одной буквы. В итоге речь рассыпается и с трудом воспринимается. Среди преимуществ стоит отметить сравнительно высокую скорость отклика, четкость и правильность произношения слов на английском языке.
Синтезатор от разработчиков специального ПО для Android оказался довольно мощны некоммерческим продуктом с широким набором функций, но русскоязычных пользователей он может разочаровать. Приложение не может прочитать слова на русском в верхнем регистре, а длинные строки из кириллических символов разбивает на маленькие фрагменты. Некоторые из таких фрагментов состоят всего из одной буквы. В итоге речь рассыпается и с трудом воспринимается. Среди преимуществ стоит отметить сравнительно высокую скорость отклика, четкость и правильность произношения слов на английском языке.
Онлайн синтезаторы речи на русском языке
Количество русскоязычных пользователей мобильных устройств Android и IOS постоянно растет. Разработчики давно уловили эту тенденцию: русский язык есть фактически в каждом синтезаторе речи. Но Google Переводчик, Text-to-speech и Яндекс.Алиса занимают особое место в данной категории за счет богатого набора слов и широкого набора функций.
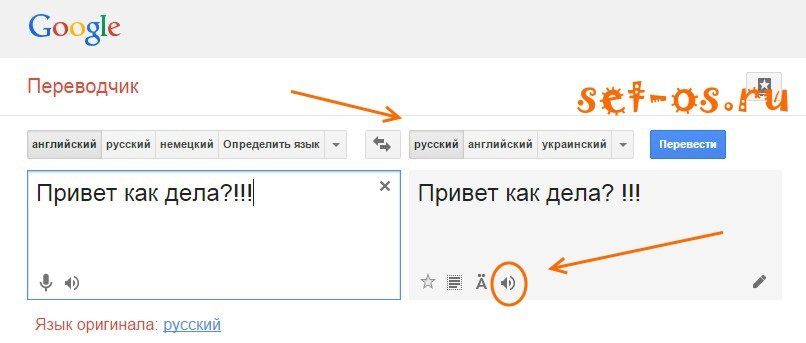
Google Переводчик
Бесплатное приложение от Google переводит текст на несколько десятков языков после ввода символов в электронную форму или фокусировки камеры мобильного устройства на конкретном слове и предложении. Несмотря на то, что программа предназначена для перевода, она может синтезировать речь. Чтобы услышать слова робота на русском языке, нужно ввести текст в электронную форму. Робот прочитает текст на русском после активации клавиши «прослушать». Качество синтеза относительно хорошее, но иногда речь получается рваной.
 Text-to-speech
Text-to-speech
Text-to-speech – приложение, предназначенное для простого преобразования печатного текста в устную речь. Программа читает разные тексты и электронные документы, даже если в них перемешаны слова из разных языков. Преобразованный текст можно сохранить для дальнейшего применения в формате wav. Здесь, по аналогии с подобными программами, настраивается скорость речи, размер шрифта, есть опции для пользователей с ограниченными возможностями.
Яндекс Алиса
Яндекс.Алиса – многофункциональный синтезатор речи на русском языке, способный поддержать разговор с пользователем на множество тем, выполнять голосовые команды, запускать некоторые приложения, Используемые здесь технологии нельзя назвать инновационными, они уже были ранее применены Google. Пользователь отправляет «Алисе» свое сообщение, записанное голосом или текстом. Сообщение распознается, выбирается один из нескольких тысяч шаблонных ответов и отправляется в виде ответа пользователю. По уровню развития искусственного интеллекта этот бот немного впереди предшественников – голосовой движок работает хорошо, разрывов в речи фактически нет. Но периодически бот выдает ответы, не имеющие связи с заданным вопросом. Разработчикам еще предстоит много работы над оптимизацией данного приложения, но уже сейчас ясно, что у него отличные перспективы.
Синтезатор речи онлайн
Программы-синтезаторы речи с каждым годом всё больше входят в нашу жизнь. Они позволяют нам более досконально учить иностранные языки, переводят тексты в удобный аудиоформат, используются в функционале различных служебных программ и многое другое. И когда у некоторых из нас возникает потребность воспроизвести онлайн какой-либо текст в аудиформате, тогда многие из нас обращаются к различным сервисам и программам по синтезу речи, способным помочь нам в трансформации нужного там текста. В этой статье я расскажу о сетевых версиях подобных продуктов, опишу, что такое синтезатор речи онлайн, какие сервисы синтеза речи online существуют, и как их использовать.

Используем синтезаторы речи
Лучшие онлайн синтезаторы речи
Изначально, синтезаторы речи разрабатывались для людей с дефектами зрения для воспроизведения текста с помощью компьютерного голоса. Но постепенно их преимущества оценила массовая аудитория, и ныне практически любой желающий может скачать себе синтезатор речи на ПК, или воспользоваться альтернативами, которые присутствуют в некоторых версиях операционных систем.
Так какой же синтезатор речи онлайн можно выбрать? Ниже я перечислю ряд сервисов, которые позволяют воспроизвести текст в речь онлайн.
Ivona — отличный синтезатор
Голосовые движки данного онлайн сервиса отличаются очень высоким качеством, хорошей фонетической основой, звучат достаточно естественно и «металлический» компьютерный голос здесь чувствуется гораздо реже, нежели у сервисов-конкурентов.
Сервис Ivona имеет поддержку множества языков, в русском варианте присутствуют мужской голос (Maxim) и женский (Tatyana).

Синтезатор Ивона на русском языке
- Чтобы использовать синтезатор речи выполните вход на данный ресурс, слева будет окно, в который необходимо будет вставить текст для прочтения.
- Вставьте текст, кликните на кнопочку с обозначением человека, выберите язык (Russian) и вариант произношения (женский или мужской) и нажмите на кнопку «Play».
К сожалению, бесплатный функционал сайта ограничен предложением с 250 символами, и предназначен скорее для демонстрации возможностей сервиса, нежели для серьёзной работы с текстом. Большие возможности можно получить лишь платно.
https://youtu.be/TIbx4pxX6Gk
Acapela — сервис распознавания речи
Компания, торгующая своими голосовыми движками для различных технических решений, предлагает вам использовать синтезатор речи Acapela в режиме онлайн. Хотя просодия этого сервиса не на такой высоте, как у Ivona, тем не менее, качество произношения здесь тоже весьма добротное. Ресурс Acapela поддерживает около 100 голосов на 34 языках.

Сервис Акапела
- Чтобы воспользоваться функционалом ресурса откройте указанный сервис, слева в окне выберите русский язык (Select a language – Russian).
- Вставьте внизу нужный текст и нажмите на кнопку «Listen» (слушать).
Максимальный размер текста для аудиопрочтения — 300 символов.
Fromtexttospeech — онлайн сервис
Чтобы перевести текст в речь онлайн можно также воспользоваться сервисом fromtexttospeech. Он работает по принципу конвертации текста в аудиофайл формата mp3, который затем можно скачать себе на компьютер. Сервис поддерживает конвертацию текста величиной в 50 тыс. символов, что является достаточно значительным объёмом.

Конвертирование текста в спич
- Для работы с сервисом fromtexttospeech перейдите на него, в опции «Select Language» выберите «Russian» (голос тут только один – Валентина).
- В большом окне введите (вставьте) нужный для озвучки текст, затем нажмите на кнопку «Create Audio File».
- Текст будет обработан, затем вы сможете послушать полученный результат, а потом и скачать его себе на ПК.
- Для этого нажмите правой клавишей мыши на «Download audio file» и выберите в появившемся меню «Сохранить объект как».
Google Переводчик также можно использовать
Всем нам известный Гугл переводчик онлайн имеет встроенную функцию воспроизведение текста в речь, причём количество прочитанного текста тут может быть весьма объёмным.

Гугл переводчик
- Для работы с ним выполните вход на данный сервис (вот здесь).
- Выберите в окне слева русский язык, и нажмите на кнопочку с динамиком снизу «Прослушать».
Качество воспроизведения на довольно сносном уровне, но не более.
Text-to-speech — синтезатор речи онлайн
Ещё один ресурс, осуществляющий синтез речи нормального качества. Бесплатный функционал ограничен набором текста длиной 1000 символов.

Тексттуспич
- Для работы с сервисом перейдите на данный сайт, в окне справа рядом с опцией «Language» (язык) выберите Russian.
- В окне наберите (или скопируйте с внешнего источника) требуемый текст, а затем нажмите на кнопку справа «Say It».
- Линк на произношение указанного текста можно также разместить в вашем е-мейле или веб-странице, кликнув на кнопку «Yes» чуть ниже.
Альтернативные программы для ПК для перевода текста в речь
Также существует программы для синтеза речи, такие как TextSpeechPro AudioBookMaker, ESpeak, Voice Reader 15, ГОЛОС и ряд других, способные конвертируют текст в речь. Их необходимо скачать и установить на свой компьютер, а функционал и возможности данных продуктов обычно чуть превышает возможности рассмотренных онлайн-сервисов. Детальная же их характеристика заслуживает отдельного обширного материала.
Заключение
Так какой же синтезатор речи онлайн выбрать? В большинстве из них бесплатные возможности существенно ограничены, а по качеству звучания сервис Ivona оставит позади своих конкурентов. Если же вас интересует возможность быстрого перевода вашего текста в аудиофайл, тогда воспользуйтесь ресурсом «fromtexttospeech» — он даёт результат хорошего качества и за достаточно короткое время.
Голосовой DeepFake, или Как работает технология клонирования голоса
Проблема синтеза речи из текста (Text-to-Speech, TTS) представляет собой одну из классических задач для искусственного интеллекта. Цель ИИ – автоматизировать процесс чтения текста, основываясь на наборах данных, содержащих пары «текст – аудиофайл».
Одной из важных проблем синтеза речи является задача создания образа голоса со всеми его характерными особенностями. Соответствующие наборы методик называют технологией клонирования голоса (англ. voice changing, voice cloning).
Решение указанной проблемы имеет множество практических приложений:
- адаптация голосов актёров при локализации фильмов
- озвучивание персонажей игр
- голосовые поздравления
- начитка аудиокниг, в том числе клонирование голосов родителей для сказок, прочитанных профессиональными дикторами
- создание аудио- и видеокурсов
- рекламные видеоролики и аудиореклама
- голоса ботов и умных устройств, персонализированных голосовых помощников
- синтез устной речи естественного звучания для немых людей, в том числе для людей, утративших возможность говорить из примеров их собственной речи
- адаптация устной речи под модель местного акцента
Очевидно, что подобные технологии могут применяться с преступными целями: мошенничество, телефонное хулиганство, компрометирование в результате совмещения с технологией DeepFake. Поэтому кроме методов клонирования голоса важно разрабатывать средства для предотвращения незаконного использования технологии.
Для обучения системы необходимо иметь большое количество сопоставленных аудиозаписей и текстов. В случае голосов знаменитостей можно прибегать к помощи записей публичных выступлений, интервью, результатам творческой деятельности и т. п. В качестве текстовых пар могут применяться стенограммы или тексты, полученные в результате коррекции автоматически распознанной речи.
Отличительной особенностью последних разработок является то, что для создания правдоподобного образа «голосовой мишени» достаточно всё меньших интервалов звучащей устной речи.
Современное состояние
В сфере создания инструментов для клонирования голоса работают множество команд, стремящихся к коммерциализации программных продуктов. По приведённым ниже ссылкам вы можете оценить текущее состояние технологии:
- Resemble.AI (предоставляется демоверсия программы).
- iSpeech (есть демо для 27 языков, включая русский).
- Lyrebird AI (можно загрузить демоверсию на 3 часа речи).
- Vera Voice, созданный компанией Screenlife Technologies Тимура Бекмамбетова и командой проекта «Робот Вера». Недавно команда показала пример адаптации голосов русских знаменитостей:
Другие компании стараются обойти стороной этический вопрос за счёт использования вместо клонирования голоса нейросетевых систем синтеза-смешения множества голосов. Таким коммерческим продуктом является, например, Yandex SpeechKit.
В связи с тем, что данная технология представляет конкурентный интерес для множества IT-компаний, проекты с открытым исходным кодом крайне редки. В этой статье мы остановимся на редком свободном проекте Real-Time Voice Cloning. Этот открытый репозиторий является результатом применения технологии переноса обучения SV2TTS, описанной в научной публикации (сэмплы, полученные в результате применения подхода).
Автор библиотеки с июня 2019 участвует в упомянутом выше коммерческом проекте Resemble.AI и уделяет репозиторию меньше времени, но ничто не мешает вам сделать собственный форк проекта.
Алгоритм клонирования голоса
Чтобы компьютер мог читать вслух текст, ему нужно понимать две вещи: что он читает и как это произнести. Поэтому в проекте Real-Time Voice Cloning система клонирования принимает два входных источника: текст, который необходимо озвучить, и образец голоса, которым этот текст должен быть прочитан.
С технической точки зрения система разбита на три компонента:
- Переданный аудиофайл с образцом речи, записанным в виде звуковой дорожки, преобразуется кодером речи (speaker encoder) в векторное представление фиксированной размерности.
- Переданный текст также кодируется в векторное представлении кодером текста (text encoder). Объединение речевого вектора и вектора текста декодируется в спектрограмму. Кодер текста, конкатенатор векторов и декодер (на схеме объединены синим цветом) представляют собой структуру синтезатора речи.
- Вокодер (vocoder, виртуальное устройство синтеза речи) преобразует спектрограмму в звуковую форму.
Модели трёх выделенных компонентов обучаются независимо друг от друга.
Где взять данные?
Объёмы информации, необходимой для качественного обучения системы клонирования, составляют десятки и сотни Гб. В рассматриваемой библиотеке для хранения датасетов служит одна общая директория. Все сценарии предварительной обработки данных выводят результаты в новый каталог SV2TTS, создаваемый в корневом каталоге датасетов. Внутри этой директории появится каталог для каждой модели: кодера, синтезатора и вокодера.
Для обучения кодера речи можно обратиться к следующим библиотекам:
- LibriSpeech (зеркало): набор данных
train-other-500(извлеките какLibriSpeech/train-other-500). - VoxCeleb1: наборы данных
Dev A–D,в том числе набор метаданных (извлеките какVoxCeleb1/wavиVoxCeleb1/vox1_meta.csv). - VoxCeleb2: наборы данных
Dev A–H(извлеките какVoxCeleb2/dev).
Для обучения синтезатор и вокодера:
- LibriSpeech: наборы данных train-clean-100 (зеркало) и train-clean-360 (зеркало) – извлеките как
LibriSpeech/train-clean-100andLibriSpeech/train-clean-360 - LibriSpeech alignments (только если у вас уже есть LibriSpeech): объедините структуру каталогов с загруженными вами наборами данных LibriSpeech
Официальным хостингом наиболее популярных наборов данных LibriSpeech служит openslr.org, который из-за популярности темы постоянно находится под существенной нагрузкой. Поэтому выше мы приложили ссылки на «зеркала» архивов.
Если вы решили с головой погрузиться в данную тему, обратите внимание на библиотеку Python для работы с аудиодатасетами audiodatasets:
pip install audiodatasets
Будьте осторожны: при установке библиотека загружает более 100 Гб данных трех наборов:
Перечислим также другие датасеты, которые не проверялись в рассматриваемой библиотеке, но применимы для обучения, в том числе корпуса русскоязычной устной речи:
- Корпус речи англоговорящих людей CSTR VCTK
- Набор данных M-AILABS: имеются примеры речи на русском, украинском, немецком, английском, испанском, итальянском, французском и польском языках
- Корпуса звучащей русской речи
- Мультимедийный корпус русского языка: преимущественно фрагменты кинофильмов с распознанным текстом
- Подборка различных речевых датасетов
Использование предобученных моделей
Имеется инструкция по переносу проекта с помощью Docker, здесь мы рассмотрим установку на локальной машине. Учтите, что наличие GPU является обязательным. Клонируем репозиторий:
git clone https://github.com/CorentinJ/Real-Time-Voice-Cloning.git
В качестве языка программирования используется Python 3, автор рекомендует версию 3.7. В связи с тем, что репозиторий предполагает привлечение вполне конкретных версий библиотек, рекомендуем питонистам пускать в ход виртуальное окружение.
Переходим в папку и устанавливаем необходимые зависимости:
pip3 install -r requirements.txt
Также потребуется фреймворк глубокого обучения PyTorch (версия не ниже 1.0.1).
Далее необходимо загрузить предобученные модели (архив на Google drive, зеркало). Согласно с вышеописанной схеме загруженный архив содержит три директории для трех моделей. Их нужно слить вместе с соответствующими директориями корневого каталога библиотеки.
Проверить правильность конфигурации можно ещё до загрузки датасетов:
python3 demo_cli.py
Если все тесты пройдены (вы увидите строку All tests passed), можно двигаться дальше. Скрипт предложит указать пути к файлам примеров, но для работы удобнее обратиться кграфическому интерфейсу:
python3 demo_toolbox.py
Если у вас уже загружены датасеты, то можно сразу указать путь к директории:
python3 demo_toolbox.py -d <путь_к_директории_датасетов>
Чтобы просто поиграть с программой, достаточно наименьшего по объёму датасета LibriSpeech/train-clean-100 (см. выше).
Пример результата вызова интерфейса:
Для первой пробы вы можете нажать под каждым разделом кнопки Random , чтобы выбрать случайный аудиопример, затем Load, чтобы загрузить голосовой ввод в систему. Выпадающий список Dataset служит для выбора набора данных, Speaker – для выбора персоны, Utterance – для произносимой фразы. Чтобы услышать как звучит отрывок, просто нажмите Play. Для запуска алгоритма нажмите Synthesize and vocode. С помощью кнопки Record one можно записать свой собственный сэмпл.
Пример работы с интерфейсом без обучения нейросетей представлен в следующем видеоролике:
Процесс обучения
Вместо предобученных моделей можно также задействовать модели, обученные на других примерах. Процесс обучения происходит посредством последовательного запуска скриптов той же библиотеки. Для того, чтобы узнать дополнительную информацию о каждом из скриптов, при используйте запуске из командной строки добавляйте аргумент -h.
Начинаем с подготовки данных для обучения кодера:
python3 encoder_preprocess.py <datasets_root>
Для обучения кодер использует окружение visdom. Инструменты окружения выглядят следующим образом:
При необходимости вы можете отключить окружение с помощью аргумента --no_visdom .
Обучаем кодер:
python3 encoder_train.py my_run <datasets_root>
Далее запускаем два скрипта, генерирующих данные для синтезатора. Начинаем с аудиофайлов:
python3 synthesizer_preprocess_audio.py <datasets_root>
Затем вложения:
python3 synthesizer_preprocess_embeds.py <datasets_root>/synthesizer
Теперь вы можете обучить синтезатор:
python3 synthesizer_train.py my_run <datasets_root>/synthesizer
Синтезатор будет выводить сгенерированные аудио и спектрограммы в каталог моделей. Используем синтезатор для генерации обучающих данных вокодера:
python3 vocoder_preprocess.py <datasets_root>
Наконец, обучаем вокодер:
python3 vocoder_train.py <datasets_root>
Вокодер выводит сгенерированные аудиофайлы в директорию модели.
При возникновении вопросов относительно работы библиотеки мы также рекомендуем ознакомиться с диссертацией автора. Там же приведены ссылки на научные работы, посвящённые теме клонирования и изменения голоса.
Интересны ли вам проекты, связанные с дипфейками лиц и голоса? Будем рады вашим ответам в комментариях.
Что такое синтезатор речи? (с изображением)
Синтезатор речи — это устройство, которое используется для преобразования текстовых символов в звуки, приближенные к звуку человеческой речи. В зависимости от уровня сложности отдельного устройства производимые звуки могут быть несколько неестественными и искусственными или очень похожими на голос реального человека. Концепция синтеза речи существовала веками, но только в последние десятилетия процесс стал доступен широкой публике.

Bell Laboratories произвела синтезатор в 1930-х годах с помощью клавиатуры.
Есть примеры попыток искусственного создания человеческих речевых образов, восходящие к 11 веку. В самых ранних попытках часто использовались материалы для имитации человеческих голосовых связок и применялись различные типы стимуляции для создания звуков.Со временем дизайн позволил воспроизводить звуки, имитирующие произношение гласных. Ко второй половине 18-го века некоторые конструкции также могли издавать звуки, очень похожие на согласные.
Настоящий прогресс в создании современных синтезаторов речи начался в 1930-х годах.Bell Laboratories произвела синтезатор, получивший название вокодер. Данные вводились с помощью клавиатуры, анализировались системой, и соответствующие звуки издавались для формирования слов. Хотя интонация и интонация слов были несколько примитивными, устройство действительно воспроизводило четко понятные слова. Усовершенствованная версия этого устройства, водер, была представлена публике на Всемирной выставке 1939 года.
К 1950-м годам работа над синтезатором речи, который будет использовать как визуальные изображения, так и вводимый текст, дала частично успешные результаты.В то же время достижения в области технологий начали улучшать качество звука. К тому времени, когда автоматическая голосовая связь стала более распространенной в 1970-х годах, существовало несколько синтезаторов речи, способных воспроизводить звуки, очень близкие к образцам речи человека. Вскоре эти устройства стали использоваться для производства таких продуктов, как предварительно записанные сообщения на автоответчики и устройства для чтения для людей с ослабленным зрением.
Появление персонального компьютера также открыло двери для дальнейших усовершенствований синтезатора речи.Включив устройство в домашнюю компьютерную систему, люди с ограниченными возможностями чтения или зрением смогут пользоваться различными компьютерными программами. Сегодня качество голоса на большинстве моделей синтезаторов речи далеко от звуков роботов, издаваемых устройствами, созданными в начале 20 века. Многие современные версии способны воспроизводить голосовые модели, которые почти неотличимы от человеческой речи.
,
SpeechSynthesis | Chrome Полная поддержка 33 | Край Полная поддержка ≤18 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
отменить | Chrome Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3.0 |
get Голоса | Хром Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3,0 |
голоса изменены | Chrome Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Opera Нет поддержки № | Safari Нет поддержки № | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Нет поддержки № | Samsung Internet Android Полная поддержка 3.0 |
пауза | хром Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4,3
| Chrome Android Полная поддержка 33
| Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3.0
|
приостановлено | Chrome Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3.0 |
на рассмотрении | Хром Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3.0 |
резюме | Chrome Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3.0 |
говорить | Chrome Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3,0 |
говорящий | хром Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3.0 |
голосов изменено событие | Chrome Полная поддержка 33 | Край Полная поддержка 14 | Firefox Полная поддержка 49 | IE Нет поддержки № | Опера Полная поддержка 21 | Safari Полная поддержка 7 | WebView Android Полная поддержка 4.4.3 | Chrome Android Полная поддержка 33 | Firefox Android Полная поддержка 62
| Опера Android Нет поддержки № | Safari iOS Полная поддержка 7 | Samsung Интернет Android Полная поддержка 3.0 |
.Синтезатор речи
дает моделям MMD голос!
Как заставить мою модель Vocaloid говорить, а не петь? Где я могу взять синтезатор речи для чтения моего сценария? Как я могу озвучить свою модель MMD?
Программа
Vocaloid — это, по сути, приложение для синтеза речи. Но он разработан специально для пения, а не для разговора… и, кроме того, поскольку почти все программное обеспечение Vocaloid сделано в Японии для пения на японском языке, его не всегда можно использовать в приложениях для речевого общения на английском языке!
Под словом здесь я подразумеваю «говорящий»…
Сделайте так, чтобы ваш
Vocaloid говорил…
Синтезатор речи дает моделям MMD голос!
Так почему вы хотите, чтобы ваш вокалоид мог говорить? Что ж, вы можете сделать с ними массу вещей, если сможете заставить их говорить.Например, они могут рассказывать анекдоты или сниматься в драматических мультфильмах. На YouTube множество подобных анимаций, но все они, как правило, используют отрывки из телепрограмм или фильмов… что хорошо, если вы просто хотите сделать пародию, как многие люди.
А что, если вам нужна «оригинальная» речь; чтобы они сказали именно то, что вы хотите?
Есть два метода:
- Попросите кого-нибудь озвучить вас. Это, вероятно, лучший метод, но проблема в том, чтобы найти кого-то, кому вы можете доверять, чтобы он хорошо выполнял свою работу; и это может быть очень сложно.Помимо всего прочего, актёр озвучивания должен уметь «действовать». Кроме того, может быть сложно организовать логистику использования этого метода.
- Использовать синтезатор речи; и это то, что мы обсудим в этой статье, поскольку это относительно легко и дешево сделать.
Итак, что вам нужно, чтобы сделать говорящую анимацию?
- MMD
- Смелость
- Скрипт
- Синтезатор речи
- Метод записи речи
Для создания движения и синхронизации губ для речевой анимации используется то же программное обеспечение, что и в других проектах анимации MMD, и они рассматриваются в других статьях.Подводя итог, вам понадобится MMD для создания основной анимации и MOGG Face and Lips для синхронизации губ (или вы также можете сделать это вручную в MMD).
Напишите свой сценарий,
«читаемый вслух» синтезатором речи…
Что касается скрипта; лучше всего набрать его в текстовом редакторе или в блокноте. Но вам не обязательно печатать слова так, как они обычно пишутся; вместо этого напишите их так, как они должны произноситься устройством. Большинство синтезаторов речи будут звучать немного механически, а также могут воспроизводить
РЕКЛАМА
забавные вещи с произношением … как будто они не узнают разницы между такими словами, как «читать» (тростник) и «читать» (красный), как в предложении «Я прочитал книгу» … так что вы можете намеренно сделать орфографическую ошибку или неправильно поставить точку во время письма, чтобы заставить синтезатор произносить слова так, как вы намереваетесь.Кроме того, синтезаторы голоса ужасны с таймингом. Просто; они обработают весь сценарий без пауз, даже если в реальной жизни мы не говорим в потоке разговоров; кроме всего прочего, нам нужно дышать! Но я вернусь, чтобы объяснить, как это сделать с помощью синтезатора речи, когда мы найдем тот, который можно использовать.
И мы будем очень дешевыми. Вам не нужно покупать один, так как есть несколько бесплатных…
Синтезаторы свободной речи…
Если ваш сценарий написан на английском языке, синтезатор речи в MS Office — идеальный кандидат.Он называется Лиза и обычно используется в качестве вспомогательного средства для людей, которым необходимо слышать, что было напечатано в текстовом документе. Лиза очень механична, по крайней мере, в той ее версии, которая у меня есть, которая входит в пакет MS Office 2003.
С другой стороны, вам может сойти с рук вокалоид, звучащий несколько механически. В конце концов, их пение тоже не совсем «человеческое».
Но вы также можете использовать синтезатор речи, встроенный в Google Translate, который звучит почти как человеческий.Говоря на японском или других языках этого типа, это звучит очень естественно, да и качество голоса очень приятное. Плюс, конечно, это совершенно бесплатно. Фактически, вы можете напечатать свой сценарий на английском языке, и программа будет говорить на японском переводе. В Google Translate есть функция речи для всех основных языков мира.
Использовать действительно просто. Вставляйте в сценарий по одному абзацу за раз. Затем пусть программа произнесет его, щелкнув значок динамика, и запишите его.
Чтобы записать речь, просто используйте микрофон портативного компьютера для записи речи во время ее чтения.Если динамики вашего ноутбука действительно хороши, я предлагаю вам использовать набор хороших внешних динамиков для воспроизведения звука.
Если это неочевидно, во время записи вам нужно будет находиться в действительно тихом месте. Вам также понадобится программа, которая может управлять процессом записи, и Audacity хорошо справляется с этой функцией.
Записывайте по одному абзацу за раз…
… и редактируйте клипы вместе.
Теперь, когда вы записываете по одному абзацу сценария за раз, вы получите целую коллекцию аудиоклипов.Чтобы сделать его единым целым, вам нужно будет соединить его вместе с Audacity — это позволяет вам изменять тайминг, и вот как добавлять паузы в ваш окончательный звук. Вы также хотите разбить свой скрипт, поскольку синтезатор речи Google Translate может вызвать проблемы с огромными объемами текста.
Вы также можете использовать Audacity для изменения качества голоса. Поскольку синтезатор речи Google Translate использует взрослый голос, например, повышение высоты звука сделает его звучание моложе; а добавление большего количества высоких частот сделает звучание ярче.Фактически, вы будете удивлены, насколько сильно вы можете изменить окончательное качество голоса. Так, например, вы можете сделать так, чтобы мужской голос звучал как женский, и наоборот.
После создания финальной речи просто экспортируйте ее как файл WAV, и вы готовы сделать остальную часть анимации. Это действительно так просто.
В любом случае, я приведу несколько примеров видео, которые я сделал, используя некоторые из описанных здесь методов.
В первом примере просто используется аудиозапись с DVD-диска «Властелин колец».
Во втором примере также используется аудиозапись с того же DVD, но исходную речь произнес Арагон, парень; по крайней мере, когда мы в последний раз проверяли. Но в клипе Неру произносит ту же речь. Чтобы речь звучала «по-женски», я переработал клип с помощью Audacity.
Но для создания оригинальной речевой анимации я использовал Lisa из MS Office 2003 и настроил ее так, чтобы она звучала так, как будто ее произносит чиби.Можно утверждать, что синтезатор голоса Google Translate обеспечил бы более естественное звучание голоса, но когда было снято это видео, это было невозможно.
Спасибо за чтение.
КРЕДИТЫ:
Верхнее изображение:
Chibi IA v2.0 — Mqdl / Kiyo / Trackdancer
MMD 9.26
Изображение обработано с помощью Irvanview
— БОЛЬШЕ Учебников по MMD см. Ниже…
,
Синтезаторы текста в речь для электронного обучения
Вам нравятся Пол и Кейт или вам нравятся Майк и Кристал? Лично я считаю, что Чарльз и Одри из Великобритании великолепны. Вот как я начал думать о синтезированных голосовых персонажах, послушав их в последнее время.
Когда TTS полезен
Мы, вероятно, все можем согласиться с тем, что голоса, сгенерированные компьютером, не обладают теплотой и богатством человеческого голоса и не могут отображать диапазон талантов, присущих квалифицированному рассказчику.Но бывают случаи, когда этот вариант стоит изучить.
Одной из причин использования программного обеспечения преобразования текста в речь (TTS) является обеспечение доступности для людей с ослабленным зрением или тех, кто испытывает трудности с чтением. Не все онлайн-курсы озвучиваются, и часто инструкции остаются только в виде текста. TTS — это способ преодолеть эти препятствия.
TTS также может быть эффективным голосом аватара или гида. Это также кажется уместным, когда нет времени или средств на запись и синхронизацию визуальных и аудиофайлов, особенно для фиктивного или скретч-аудио, когда вам нужно показать другим, как элементы мультимедиа будут интегрированы.Наконец, в художественном произведении TTS может быть уместным как звук машины, объекта или компьютера.
Возможности преобразования текста в речь интегрированы в Adobe Captivate, что дает возможность использовать эту функцию без необходимости в дополнительном программном обеспечении. Но если выбранный вами инструмент разработки не поддерживает эту функцию, вам придется полагаться на внешнее программное обеспечение и импортировать аудиофайлы. Ниже приведен список программного обеспечения для преобразования текста в речь, которое вы можете изучить. Внимательно слушайте голоса, так как у некоторых есть демонстрации, которые зачитывают введенный вами текст.Кроме того, у многих теперь есть говорящие на нескольких языках.
ТЕКСТ ДЛЯ СИНТЕЗАТОРОВ РЕЧИ
iSpeech предлагает множество онлайн-сервисов и моделей ценообразования для преобразования TTS и загрузки файлов со своего сайта. Если вы разрабатываете веб-сайт, например учебные порталы, вы также можете подключиться через их API, используя несколько строк кода, и у вас есть устная версия вашего текста.
NaturalSoft выпускает программу NaturalReader в нескольких версиях, включая бесплатную.Версия Professional больше всего подходит для онлайн-обучения, поскольку она конвертирует файлы в форматы wav / .mp3 и поставляется с двумя или четырьмя голосами.
NeoSpeech — это, прежде всего, услуга по запросу, хотя они предоставляют разработчикам лицензии на свой программный механизм. Вы покупаете кредиты, выбираете голос, вводите или копируете / вставляете текст в их редактор и загружаете синтезированные аудиофайлы.
Это онлайн-приложение TTS, которое обеспечивает преобразование текстовых файлов и документов в аудиофайлы с использованием различных голосовых символов.Есть бесплатная версия и платное обновление.
Это программное обеспечение TTS работает с PowerPoint. Он генерирует повествование из текста PowerPoint.
SpokenText — это онлайн-синтезатор речи в текст, который преобразует текстовые файлы, документы (pdf, doc, ppt) и веб-страницы в аудиофайлы. Существует множество структур ценообразования и несколько голосов на выбор.
NextUp продает синтезатор TextAloud 2 для ПК и Ghostreader для Mac. Он также продает голоса различных персонажей на разных языках от основных издателей голосовой связи, включая AT&T Natural Voices, Acapela Group, RealSpeak и Cepstral.
Virtual Speaker — еще один преобразователь текста в речь. У него много возможностей для записи, но потенциальные покупатели должны связаться с издателем, Acapela Group, чтобы узнать цену.
Это онлайн-сервис TTS, использующий голоса Cepstral. Вы получаете доступ ко всем голосам персонажей по одной цене, но эта услуга предназначена только для онлайн-приложений и устройств.
Linguatec издает программное обеспечение VoiceReader, которое может преобразовывать любой текст в аудио. Преобразование текста в речь VoiceReader работает на многих языках.
На всякий случай, если вы разработчик или ваша компания ищет технологию TTS, посетите сайт Wizzard. Они создают речевые приложения для разработчиков и предприятий и используют Natural Voices от AT&T.
ГОЛОСОВЫЕ ИЗДАТЕЛИ
Acapela предоставляет разнообразные аудиоуслуги, одна из которых — создание символьных голосов на разных языках. Посмотрите, как разнообразны их голоса на их сайте.
Cepstral — издатель синтетического голоса.Вы можете встретить Эллисон, Лоуренс, Витторию и многих других персонажей из разных стран на их странице Демоверсии. Голоса работают как с ПК, так и с Mac.
Как вы используете преобразование текста в речь в онлайн-обучении? Расскажите нам о своем опыте и рекомендациях.
Получайте последние статьи, ресурсы и бесплатные подарки один раз в месяц, а также 12 советов по созданию сценариев.
ОТПРАВИТЬ СОВЕТЫ ПО СЦЕНАРИЯМ
,