Голосовые данные для синтеза речи женский русский как убрать: Как остановить скачивание пакета (Русский) на Андроид
Как остановить скачивание пакета (Русский) на Андроид

В некоторых случаях на Android-смартфонах появляется уведомление «Скачивание пакета “Русский”». Сегодня мы хотим рассказать вам, что это такое и как убрать это сообщение.
Почему уведомление появляется и как его убрать
«Пакет “Русский”» — компонент голосового управления телефоном от Google. Данный файл представляет собой словарь, который используется приложением «корпорации добра» для распознавания запросов пользователя. Зависшее уведомление о скачивании этого пакета сообщает о сбое либо в самом приложении Гугл, либо в менеджере загрузок Андроид. Справится с с этой проблемой можно двумя путями – дозагрузить проблемный файл и отключить автообновления языковых пакетов или очистить данные приложения.
Способ 1: Отключение автообновления языковых пакетов
На некоторых прошивках, особенно сильно модифицированных, возможна нестабильная работа программы-поисковика Google. Из-за внесенных в систему модификаций или сбоя неясной природы приложение не может обновить голосовой модуль для выбранного языка. Следовательно, стоит сделать это вручную.
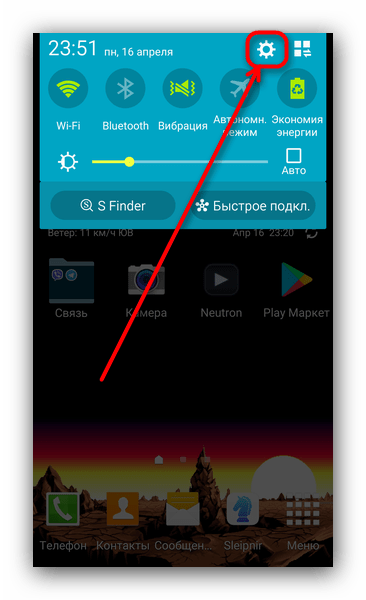
- Откройте «Настройки». Сделать это можно, например, из шторки.
- Ищем блоки «Управление» или «Дополнительно», в нем – пункт «Язык и ввод».
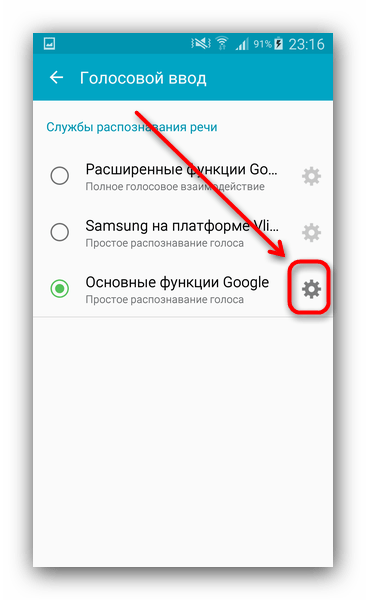
- В меню «Язык и ввод» ищем «Голосовой ввод Google».
- Внутри этого меню найдите «Основные функции Google».

Нажмите на иконку с изображением шестерни. - Тапните по «Распознавание речи офлайн».
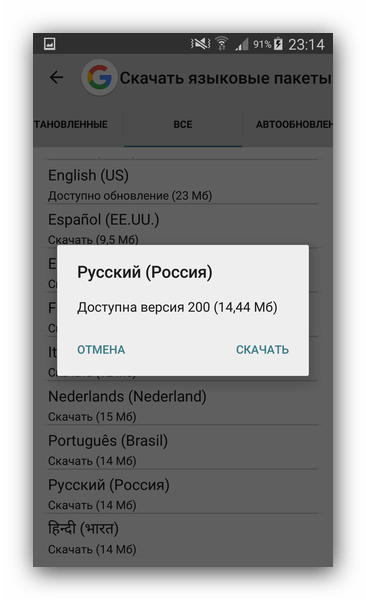
- Откроются настройки голосового ввода. Перейдите на вкладку «Все».
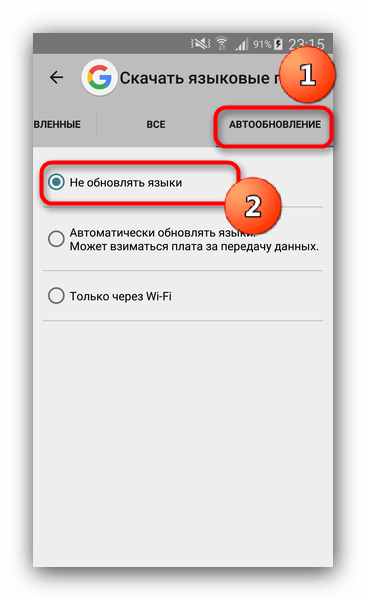
Пролистайте список вниз. Найдите «Русский (Россия)» и скачайте его. - Теперь перейдите на вкладку «Автообновления».
Отметьте пункт «Не обновлять языки».




Проблема будет решена – уведомление должно пропасть и больше вас не беспокоить. Однако на некоторых вариантах прошивок этих действий может быть недостаточно. Столкнувшись с таким, переходите к следующему методу.
Способ 2: Очистка данных приложений Google и «Диспетчера загрузки»
Из-за несоответствия компонентов прошивки и сервисов Гугл возможно зависание обновления языкового пакета. Перезагрузка аппарата в этом случае бесполезна – нужно очищать данные как самого поискового приложения, так и «Диспетчера загрузок».
- Заходите в «Настройки» и ищите пункт «Приложения» (иначе «Диспетчер приложений»).
- В «Приложениях» найдите «Google».
Будьте внимательны! Не перепутайте его с Google Play Services!
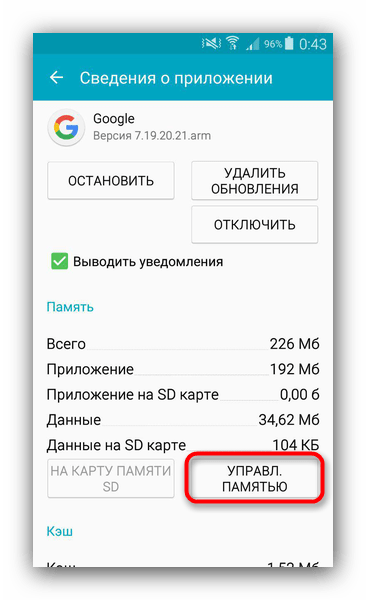
- Тапните по приложению. Откроется меню свойств и управления данными. Нажмите «Управление памятью».
В открывшемся окне тапните «Удалить все данные».
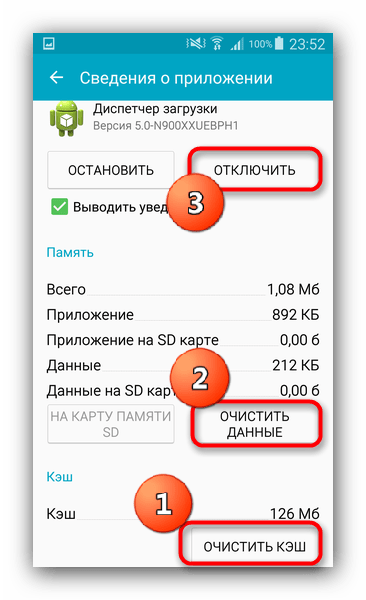
Подтвердите удаление. - Переходите обратно в «Приложения». На этот раз найдите «Диспетчер загрузок».
Если вы не можете его обнаружить, нажмите на три точки справа вверху и выберите «Показать системные приложения». - Нажмите последовательно «Очистить кэш», «Очистить данные» и «Остановить».
- Перезагружайте ваш девайс.





Комплекс описанных действий поможет решить проблему раз и навсегда.
Подводя итог, отметим, что наиболее часто подобная ошибка встречается на аппаратах Xiaomi с русифицированной китайской прошивкой.
 Мы рады, что смогли помочь Вам в решении проблемы.
Мы рады, что смогли помочь Вам в решении проблемы.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТ
Женский, русский (Россия) и Скачивание пакета (Русский(Россия)) — Xiaomi Redmi Note 3 Pro
Всем привет! Несколько дней назад, в шторке моего Xiaomi Redmi Note 3 Pro появился значек загрузки. Открыв ее, мы видим 2 сообщения:
- Женский, русский (Россия) либо female for english
- Скачивание пакета (Русский(Россия))
Судя по иконкам, можно понять, что первая относится к «Синтезатору речи Google», а вторая — к «Голосовому вводу Google».
И вроде бы ничего особенного, обычные обновления. Но проблема в том, что эти обновления не происходят и загрузка из шторки не исчезает. И это начинает раздражать. Давайте попробуем с этим самостоятельно разобраться, так как решения в Интернет я не нашел. Начнем с первой.
1. Женский, русский (Россия). Либо Female for english
Способ первый, временный.
Почему временный? Потому, что работает он до первой перезагрузки смартфона. Но, если вы перезагружаете его не часто, то он вам подойдет.
- Заходим в «Настройки»—>«Дополнительно»—>«Язык и ввод»—>«Синтез речи».
- Нажимаем на иконку шестеренки правом верхнем углу
- Выбираем «Установка голосовых данных». Здесь ищем язык «русский (Россия)»
- Открываем и жмем на крестик, для отмены загрузки.
Все, теперь загрузка исчезнет.
Способ второй — полное решение проблемы.
Единственное решение, которое я смог найти для полного избавления от проблемы — это загрузка языка. Если у вас есть Wi-Fi, то просто подключаемся к нему и загружаем язык. Если нет, то сначала, нам нужно разрешить обновление через мобильный интернет.
- Смотрим первый способ и выполняем его до попадания в настройки «Синтезатора речи»
- Здесь выбираем «Синтезатор речи Google» и выключаем режим «Только Wi-Fi» (не забудьте включить его после обновления.
- Нажимаем назад, переходим в Установку голосовых данных и загружаем язык «русский (Россия)».
Можно сказать, что первая проблема решена.
2. Скачивание пакета (Русский(Россия))
Судя по всему, этот пакет относится к «Голосовому вводу», т.е. распознаванию вашей речи офлайн. Задействуется он в тот момент, когда вы говорите «Ok google». Честно сказать, я перепробовал массу решений и настроек, и на моем смартфоне, так и не смог отключить это уведомление в шторке (UPD от 1.07.2017 — третий способ решает проблему). Но возможно, здесь дело в прошивке. Поэтому, вот несколько вариантов, которые возможно помогут вам.
Способ первый. Это опять таки загрузка языкового пакета.
- Идем в «Настройки»—>«Дополнительно»—>«Язык и ввод»—>«Голосовой ввод»
- Нажимаем на «шестеренку»
- Выбираем пункт «Распознавание речи офлайн»
- Переходим на вкладку «Все», выбираем язык «Русский (Россия)» и загружаем его
- Затем, переходим на вкладку «Автообновление» и выключаем его.
Если после этих действий, уведомление из шторки пропало, то вы большой счастливчик. Если нет, то рассмотрим еще один способ.
Способ второй — очистка данных приложений.
Имейте ввиду, что все их данные будут удалены.
- Открываем «Настройки»—>«Все приложения»
- Выбираем приложение «Загрузки» и жмем «Стереть данные»
- Выбираем приложение «Google», нажимаем «Управление местом»—>«Удалить все данные»
- Перезагружаемся и выполняем первый способ.
Если у вас получилось справится с этой проблемой, пожалуйста, напишите нам и мы добавим решение в этот Faq.
Способ третий — удаление назойливой загрузки.
Не знаю, где были мои глаза все это время. Но я просто не заметил еще одно приложение — Диспетчер загрузки. Именно его данные нам и нужно очистить, а не приложения «Загрузки».
Итак, действия пошагово:
- Сначала выполняем первый способ
- Теперь способ 2. Только в нем мы выбираем приложение «Диспетчер загрузки»
- Очищаем его данные и закрываем
- Перезагружаемся.
Если нет Диспетчера загрузок, смотрим этот комментарий.
На этом все. Надеюсь, кому-то это будет полезно.
Нейросетевой синтез речи своими руками
Синтез речи на сегодняшний день применяется в самых разных областях. Это и голосовые ассистенты, и IVR-системы, и умные дома, и еще много чего. Сама по себе задача, на мой вкус, очень наглядная и понятная: написанный текст должен произноситься так, как это бы сделал человек.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Синтез речи
Чтобы построить систему синтеза речи, нужна целая команда специалистов из разных областей. По каждой из них существует целая масса алгоритмов и подходов. Написаны докторские диссертации и толстые книжки с описанием фундаментальных подходов. Давайте для начала поверхностно разберемся с каждой их них.
Лингвистика
- Нормализация текста. Для начала нам нужно развернуть все сокращения, числа и даты в текст. 50е годы XX века должно превратиться в пятидесятые годы двадцатого века, а г. Санкт-Петербург, Большой пр. П.С. в город Санкт-Петербург, Большой проспект Петроградской Стороны. Это должно происходить так естественно, как если бы человека попросили прочитать написанное.
- Подготовка словаря ударений. Расстановка ударений может производиться по правилам языка. В английском ударение часто ставится на первый слог, а в испанском — на предпоследний. При этом из этих правил существует целая масса исключений, не поддающихся какому-то общему правилу. Их обязательно нужно учитывать. Для русского языка в общем смысле правил расстановки ударения вообще не существует, так что без словаря с расставленными ударениями совсем никуда не деться.
- Снятие омографии. Омографы — это слова, которые совпадают в написании, но различаются в произношении. Носитель языка легко расставит ударения: дверной замок и замок на горе. А вот ключ от замка — задача посложнее. Полностью снять омографию без учета контекста невозможно.
Просодика
- Выделение синтагм и расстановка пауз. Синтагма представляет относительно законченный по смыслу отрезок речи. Когда человек говорит, он обычно вставляет паузы между фразами. Нам нужно научиться разделять текст на такие синтагмы.
- Определение типа интонации. Выражение завершенности, вопроса и восклицания — самые простые интонации. А вот выразить иронию, сомнение или воодушевление задача куда сложнее.
Фонетика
- Получение транскрипции. Так как в конечном итоге мы работаем с произнесением, а не с написанием, то очевидно вместо букв (графем), логично использовать звуки (фонемы). Преобразование графемной записи в фонемную — отдельная задача, состоящая из множества правил и исключений.
- Вычисление параметров интонации. В этот момент нужно решить как будет меняться высота основного тона и скорость произнесения в зависимости от расставленных пауз, подобранной последовательности фонем и типа выражаемой интонации. Помимо основного тона и скорости есть и другие параметры, с которыми можно долго экспериментировать.
Акустика
- Подбор звуковых элементов. Системы синтеза оперируют так называемыми аллофонами — реализациями фонемы, зависящими от окружения. Записи из обучающих данных нарезаются на кусочки по фонемной разметке, которые образуют аллофонную базу. Каждый аллофон характеризуется набором параметров, таких как контекст (фонемы соседи), высота основного тона, длительность и прочие. Сам процесс синтеза представляет собой подбор правильной последовательности аллофонов, наиболее подходящих в текущих условиях.
- Модификация и звуковые эффекты. Для получившихся записей иногда нужна постобработка, какие-то специальные фильтры, делающие синтезируемую речь чуть ближе к человеческой или исправляющие какие-то дефекты.
Если вдруг вам показалось, что все это можно упростить, прикинуть в голове или быстро подобрать какие-то эвристики для отдельных модулей, то просто представьте, что вам нужно сделать синтез на хинди. Если вы не владеете языком, то вам даже не удастся оценить качество вашего синтеза, не привлекая кого-то, кто владел бы языком на нужном уровне. Мой родной язык русский, и я слышу, когда синтез ошибается в ударениях или говорит не с той интонацией. Но в тоже время, весь синтезированный английский для меня звучит примерно одинаково, не говоря уже о более экзотических языках.
Реализации
Мы попытаемся найти End-2-End (E2E) реализацию синтеза, которая бы взяла на себя все сложности, связанные с тонкостями языка. Другими словами, мы хотим построить систему, основанную на нейронных сетях, которая бы на вход принимала текст, а на выходе давала бы синтезированную речь. Можно ли обучить такую сеть, которая позволила бы заменить целую команду специалистов из узких областей на команду (возможно даже из одного человека), специализирующуюся на машинном обучении?
На запрос end2end tts Google выдает целую массу результатов. Во главе — реализация Tacotron от самого Google. Самым простым мне показалось идти от конкретных людей на Github, которые занимаются исследованиям в этой области и выкладывают свои реализации различных архитектур.
Я бы выделил троих:
- Kyubyong Park
- Keith Ito
- Ryuichi Yamamoto
Загляните к ним в репозитории, там целый кладезь информации. Архитектур и подходов к задаче E2E-синтеза довольно много. Среди основных:
- Tacotron (версии 1, 2).
- DeepVoice (версии 1, 2, 3).
- Char2Wav.
- DCTTS.
- WaveNet.
Нам нужно выбрать одну. Я выбрал Deep Convolutional Text-To-Speech (DCTTS) от Kyubyong Park в качестве основы для будущих экспериментов. Оригинальную статью можно посмотреть по ссылке. Давайте поподробнее рассмотрим реализацию.
Автор выложил результаты работы синтеза по трем различным базам и на разных стадиях обучения. На мой вкус, как не носителя языка, они звучат весьма прилично. Последняя из баз на английском языке (Kate Winslet’s Audiobook) содержит всего 5 часов речи, что для меня тоже является большим преимуществом, так как моя база содержит примерно сопоставимое количество данных.
Через некоторое время после того, как я обучил свою систему, в репозитории появилась информация о том, что автор успешно обучил модель для корейского языка. Это тоже довольно важно, так как языки могут сильно разниться и робастность по отношению к языку — это приятное дополнение. Можно ожидать, что в процессе обучения не потребуется особого подхода к каждому набору обучающих данных: языку, голосу или еще каким-то характеристикам.
Еще один важный момент для такого рода систем — это время обучения. Tacotron на том железе, которое у меня есть, по моим оценкам учился бы порядка 2 недель. Для прототипирования на начальном уровне мне показалось это слишком ресурсоемким. Педали, конечно, крутить не пришлось бы, но на создание какого-то базового прототипа потребовалось бы очень много календарного времени. DCTTS в финальном варианте учится за пару дней.
У каждого исследователя есть набор инструментов, которыми он пользуется в своей работе. Каждый подбирает их себе по вкусу. Я очень люблю PyTorch. К сожалению, на нем реализации DCTTS я не нашел, и пришлось использовать TensorFlow. Возможно в какой-то момент выложу свою реализацию на PyTorch.
Данные для обучения
Хорошая база для реализации синтеза — это основной залог успеха. К подготовке нового голоса подходят очень основательно. Профессиональный диктор произносит заранее подготовленные фразы в течение многих часов. Для каждого произнесения нужно выдержать все паузы, говорить без рывков и замедлений, воспроизвести правильный контур основного тона и все это в купе с правильной интонацией. Кроме всего прочего, не все голоса одинаково приятно звучат.
У меня на руках была база порядка 8 часов, записанная профессиональным диктором. Сейчас мы с коллегами обсуждаем возможность выложить этот голос в свободный доступ для некоммерческого использования. Если все получится, то дистрибутив с голосом помимо самих записей будет включать в себя точные текстовки для каждой из них.
Начнем
Мы хотим создать сеть, которая на вход принимала бы текст, а на выходе давала бы синтезированный звук. Обилие реализаций показывает, что это возможно, но есть конечно и ряд оговорок.
Основные параметры системы обычно называют гиперпараметрами и выносят в отдельный файл, который называется соответствующим образом: hparams.py или hyperparams.py, как в нашем случае. В гиперпараметры выносится все, что можно покрутить, не трогая основной код. Начиная от директорий для логов, заканчивая размерами скрытых слоев. После этого гиперпараметры в коде используются примерно вот так:
from hyperparams import Hyperparams as hp
batch_size = hp.B # размер батча берем из гиперпараметровДалее по тексту все переменные имеющие префикс hp. берутся именно из файла гиперпараметров. Подразумевается, что эти параметры не меняются в процессе обучения, поэтому будьте осторожны перезапуская что-то с новыми параметрами.
Текст
Для обработки текста обычно используются так называемый embedding-слой, который ставится самым первым. Суть его простая — это просто табличка, которая каждому символу из алфавита ставит в соответствие некий вектор признаков. В процессе обучения мы подбираем оптимальные значения для этих векторов, а когда синтезируем по готовой модели, просто берем значения из этой самой таблички. Такой подход применяется в уже довольно широко известных Word2Vec, где строится векторное представление для слов.
Для примера возьмем простой алфавит:
['a', 'b', 'c']В процессе обучения мы выяснили, что оптимальные значения каждого их символов вот такие:
{
'a': [0, 1],
'b': [2, 3],
'c': [4, 5]
}Тогда для строчки aabbcc после прохождения embedding-слоя мы получим следующую матрицу:
[[0, 1], [0, 1], [2, 3], [2, 3], [4, 5], [4, 5]]Эта матрица дальше подается на другие слои, которые уже не оперируют понятием символ.
В этот момент мы видим первое ограничение, которое у нас появляется: набор символов, который мы можем отправлять на синтез, ограничен. Для каждого символа должно быть какое-то ненулевое количество примеров в обучающих данных, лучше с разным контекстом. Это значит, что нам нужно быть осторожными в выборе алфавита.
В своих экспериментах я остановился на варианте:
# Алфавит задается в файле с гиперпараметрами
vocab = "E абвгдеёжзийклмнопрстуфхцчшщъыьэюя-" Это алфавит русского языка, дефис, пробел и обозначение конца строки. Тут есть несколько важных моментов и допущений:
- Я не добавлял в алфавит знаки препинания. С одной стороны, мы действительно их не произносим. С другой, по знакам препинания мы делим фразу на части (синтагмы), разделяя их паузами. Как система произнесет казнить нельзя помиловать?
- В алфавите нет цифр. Мы ожидаем, что они будут развернуты в числительные перед подачей на синтез, то есть нормализованы. Вообще все E2E-архитектуры, которые я видел, требуют именно нормализованный текст.
- В алфавите нет латинских символов. Английский система уметь произносить не будет. Можно попробовать транслитерацию и получить сильный русский акцент — пресловутый лет ми спик фром май харт.
- В алфавите есть буква ё. В данных, на который я обучал систему, она стояла там, где нужно, и я решил этот расклад не менять. Однако, в тот момент, когда я оценивал получившиеся результаты, выяснилось, что теперь перед подачей на синтез эту букву тоже нужно ставить правильно, иначе система произносит именно е, а не ё.
В будущих версиях можно уделить каждому из пунктов более пристальное внимание, а пока оставим в таком немного упрощенном виде.
Звук
Почти все системы оперируют не самим сигналом, а разного рода спектрами полученными на окнах с определенным шагом. Я не буду вдаваться в подробности, по этой теме довольно много разного рода литературы. Сосредоточимся на реализации и использованию. В реализации DCTTS используются два вида спектров: амплитудный спектр и мел-спектр.
Считаются они следующим образом (код из этого листинга и всех последующих взят из реализации DCTTS, но видоизменен для наглядности):
# Получаем сигнал фиксированной частоты дискретизации
y, sr = librosa.load(wavename, sr=hp.sr)
# Обрезаем тишину по краям
y, _ = librosa.effects.trim(y)
# Pre-emphasis фильтр
y = np.append(y[0], y[1:] - hp.preemphasis * y[:-1])
# Оконное преобразование Фурье
linear = librosa.stft(y=y,
n_fft=hp.n_fft,
hop_length=hp.hop_length,
win_length=hp.win_length)
# Амплитудный спектр
mag = np.abs(linear)
# Мел-спектр
mel_basis = librosa.filters.mel(hp.sr, hp.n_fft, hp.n_mels)
mel = np.dot(mel_basis, mag)
# Переводим в децибелы
mel = 20 * np.log10(np.maximum(1e-5, mel))
mag = 20 * np.log10(np.maximum(1e-5, mag))
# Нормализуем
mel = np.clip((mel - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1)
mag = np.clip((mag - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1)
# Транспонируем и приводим к нужным типам
mel = mel.T.astype(np.float32)
mag = mag.T.astype(np.float32)
# Добиваем нулями до правильных размерностей
t = mel.shape[0]
num_paddings = hp.r - (t % hp.r) if t % hp.r != 0 else 0
mel = np.pad(mel, [[0, num_paddings], [0, 0]], mode="constant")
mag = np.pad(mag, [[0, num_paddings], [0, 0]], mode="constant")
# Понижаем частоту дискретизации для мел-спектра
mel = mel[::hp.r, :]
Для вычислений почти во всех проектах E2E-синтеза используется библиотека LibROSA (https://librosa.github.io/librosa/). Она содержит много полезного, рекомендую заглянуть в документацию и посмотреть, что в ней есть.
Теперь давайте посмотрим как амплитудный спектр (magnitude spectrum) выглядит на одном из файлов из базы, которую я использовал:
Такой вариант представления оконных спекторов называется спектрограммой. На оси абсцисс располагается время в секундах, на оси ординат — частота в герцах. Цветом выделяется амплитуда спектра. Чем точка ярче, тем значение амплитуды больше.
Мел-спектр — это амплитудный спектр, но взятый на мел-шкале с определенным шагом и окном. Количество шагов мы задаем заранее, в большинстве реализаций для синтеза используется значение 80 (задается параметром hp.n_mels). Переход к мел-спектру позволяет сильно сократить количество данных, но этом сохранить важные для речевого сигнала характеристики. Мел-спектрограмма для того же файла выглядит следующим образом:
Обратите внимание на прореживание мел-спектров во времени на последней строке листинга. Мы берем только каждый 4 вектор (hp.r == 4), соответственно уменьшая тем самым частоту дискретизации. Синтез речи сводится к предсказанию мел-спектров по последовательности символов. Идея простая: чем меньше сети приходится предсказывать, тем лучше она будет справляться.
Хорошо, мы можем получить спектрограмму по звуку, но послушать мы ее не можем. Соответственно нам нужно уметь восстанавливать сигнал обратно. Для этих целей в системах часто используется алгоритм Гриффина-Лима и его более современные интерпретации (к примеру, RTISILA, ссылка). Алгоритм позволяет восстановить сигнал по его амплитудным спектрам. Реализация, которую использовал я:
def griffin_lim(spectrogram, n_iter=hp.n_iter):
x_best = copy.deepcopy(spectrogram)
for i in range(n_iter):
x_t = librosa.istft(x_best,
hp.hop_length,
win_length=hp.win_length,
window="hann")
est = librosa.stft(x_t,
hp.n_fft,
hp.hop_length,
win_length=hp.win_length)
phase = est / np.maximum(1e-8, np.abs(est))
x_best = spectrogram * phase
x_t = librosa.istft(x_best,
hp.hop_length,
win_length=hp.win_length,
window="hann")
y = np.real(x_t)
return yА сигнал по амплитудной спектрограмме можно восстановить вот так (шаги, обратные получению спектра):
# Транспонируем
mag = mag.T
# Денормализуем
mag = (np.clip(mag, 0, 1) * hp.max_db) - hp.max_db + hp.ref_db
# Возвращаемся от децибел к аплитудам
mag = np.power(10.0, mag * 0.05)
# Восстанавливаем сигнал
wav = griffin_lim(mag**hp.power)
# De-pre-emphasis фильтр
wav = signal.lfilter([1], [1, -hp.preemphasis], wav)Давайте попробуем получить амплитудный спектр, восстановить его обратно, а затем послушать.
Оригинал:
Восстановленный сигнал:
На мой вкус, результат стал хуже. Авторы Tacotron (первая версия также использует этот алгоритм) отмечали, что использовали алгоритм Гриффина-Лима как временное решение для демонстрации возможностей архитектуры. WaveNet и ему подобные архитектуры позволяют синтезировать речь лучшего качества. Но они более тяжеловесные и требуют определенных усилий для обучения.
Обучение
DCTTS, который мы выбрали, состоит из двух практически независимых нейронных сетей: Text2Mel и Spectrogram Super-resolution Network (SSRN).
Text2Mel предсказывает мел-спектр по тексту, используя механизм внимания (Attention), который увязывает два энкодера (TextEnc, AudioEnc) и один декодер (AudioDec). Обратите внимание, что Text2Mel восстанавливает именно разреженный мел-спектр.
SSRN восстанавливает из мел-спектра полноценный амплитудный спектр, учитывая пропуски кадров и восстанавливая частоту дискретизации.
Последовательность вычислений довольно подробно описана в оригинальной статье. К тому же есть исходный код реализации, так что всегда можно отладиться и вникнуть в тонкости. Обратите внимание, что автор реализации отошел в некоторых местах от статьи. Я бы выделил два момента:
- Появились дополнительные слои для нормализации (normalization layers), без которых, по словам автора, ничего не работало.
- В реализации используется механизм исключения (dropout) для лучшей регуляризации. В статье этого нет.
Я взял голос, включающий в себя 8 часов записей (несколько тысяч файлов). Оставил только записи, которые:
- В текстовках содержат только буквы, пробелы и дефисы.
- Длина текстовок не превышает hp.max_N.
- Длина мел-спектров после разреживания не превышает hp.max_T.
У меня получилось чуть больше 5 часов. Посчитал для всех записей нужные спекты и поочередно запустил обучение Text2Mel и SSRN. Все это делается довольно безхитростно:
$ python prepro.py
$ python train.py 1
$ python train.py 2Обратите внимание, что в оригинальном репозитории prepro.py именуется как prepo.py. Мой внутренний перфекционист не смог этого терпеть, так что я его переименовал.
DCTTS содержит только сверточные слои, и в отличие от RNN реализаций, вроде Tacotron, учится значительно быстрее.
На моей машине с Intel Core i5-4670, 16 Gb RAM и GeForce 1080 на борту 50 тыс. шагов для Text2Mel учится за 15 часов, а 75 тыс. шагов для SSRN — за 5 часов. Время требуемое на тысячу шагов в процессе обучения у меня почти не менялось, так что можно легко прикинуть, сколько потребуется времени на обучение с большим количеством шагов.
Размер батча можно регулировать параметром hp.B. Периодически процесс обучения у меня валился с out-of-memory, так что я просто делил на 2 размер батча и перезапускал обучение с нуля. Полагаю, что проблема кроется где-то в недрах TensorFlow (я использовал не самый свежий) и тонкостях реализации батчинга. Я с этим разбираться не стал, так как на значении 8 все падать перестало.
Результат
После того, как модели обучились, можно наконец запустить и синтез. Для этого заполняем файлик с фразами и запускаем:
$ python synthesize.pyЯ немного поправил реализацию, чтобы генерировать фразы из нужного файла.
Результаты в виде WAV-файлов будут сохранены в директорию samples. Вот примеры синтеза системой, которая получилась у меня:
Выводы и ремарки
Результат превзошел мои личные ожидания по качеству. Система расставляет ударения, речь получается разборчивой, а голос узнаваем. В целом получилось неплохо для первой версии, особенно с учетом того, что для обучения использовалось всего 5 часов обучающих данных.
Остаются вопросы по управляемости таким синтезом. Пока невозможно даже исправить ударение в слове, если оно неверное. Мы жестко завязаны на максимальную длину фразы и размер мел-спектрограммы. Нет возможности управлять интонацией и скоростью воспроизведения.
Я не выкладывал мои изменения в коде оригинальной реализации. Они коснулись только загрузки обучающих данных и фраз для синтеза уже по готовой системе, а также значений гиперпараметров: алфавит (hp.vocab) и размер батча (hp.B). В остальном реализация осталась оригинальная.
В рамках рассказа я совсем не коснулся темы продакшн реализации таких систем, до этого полностью E2E-системам синтеза речи пока очень далеко. Я использовал GPU c CUDA, но даже в этом случае все работает медленнее реального времени. На CPU все работает просто неприлично медленно.
Все эти вопросы будут решаться в ближайшие годы крупными компаниями и научными сообществами. Уверен, что это будет очень интересно.
Компания Яндекс — Технологии — SpeechKit — речевые технологии Яндекса
Ещё недавно общение с роботами было чем-то из области фантастики. Только капитан космического корабля мог голосом, не нажимая никаких кнопок, отдать команду бортовому компьютеру проложить маршрут к нужной точке. Сегодня это может сделать любой пользователь Яндекс.Навигатора. Возможно, вам и самим случалось говорить с роботами: во многих больших компаниях на звонки клиентов сейчас отвечают виртуальные операторы, которые самостоятельно решают типовые несложные задачи.
Чтобы говорить с человеком, компьютер должен уметь превращать звуковой сигнал в слова, улавливать смысл сказанного и произносить ответ. Другими словами, при каждом обмене репликами с человеком робот распознаёт речь, выделяет смысловые объекты и, приняв решения на основе полученных данных, синтезирует голосовой ответ.
В Яндексе эти задачи решаются с помощью комплекса речевых технологий, который называется SpeechKit. В этой статье мы вкратце расскажем об основных принципах его работы.
Распознавание речи
Если сказать голосовому поиску «Лев Толстой», смартфон услышит не имя и фамилию и даже не два слова, а просто последовательность плавно сменяющих друг друга звуков. Задача системы распознавания речи — «расслышать» в этих звуках буквы (вернее, соответствующие им фонемы) и сложить их в слова. Ситуацию осложняет то, что одна и та же фраза, произнесённая разными людьми в разной обстановке, будет звучать по-разному и давать непохожие друг на друга сигналы. Правильно интерпретировать их помогают акустическая и языковая модели.
Акустическая модель
Акустическая модель умеет определять, какой набор фонем соответствует звуковому сигналу. Этому она учится на большом корпусе начитанных дикторами текстов и их транскрипций — компьютер как бы следит за чтением по подстрочнику. Со временем, прослушав и прочитав определённое количество материалов и накопив достаточную статистику совпадений, он делает вывод: звуку с такими характеристиками, как правило, соответствует такая-то фонема, другому звуку — другая, и так далее.
Акустическая модель работает не с самим звуком, а с его характеристиками — то есть признаками, выраженными в цифрах. Когда вы произносите голосовой запрос, например в Яндекс.Навигаторе, смартфон записывает его и отправляет на сервер Яндекса. Там запись разделяется на много маленьких фрагментов — фреймов. На каждую секунду речи приходится сто фреймов. Они длятся по 25 миллисекунд и идут внахлёст, как черепица, чтобы информация на стыках не терялась. Каждый фрейм подвергается ряду преобразований, в результате которых получается около 40 коэффициентов, описывающих его частотные характеристики. На основании этих данных акустическая модель может предположить, частью какой фонемы является фрейм.
Фонемой называется элементарная единица речи — в русском языке их около 40 (около — потому что лингвисты разных школ пользуются разными системами классификации и единого мнения насчёт числа фонем у них нет). На самом деле звуки, которые мы произносим, гораздо разнообразнее, ведь звучание фонемы зависит от того, в какой части слова — в начале, середине или конце — она находится и что у неё за соседи. Например, [а] между двумя гласными в сочетании «на аудиозаписи» отличается от [а] между согласными в слове «бак». Поэтому для хорошего распознавания фонема — слишком грубая единица.
Чтобы точнее смоделировать произношение фонемы, мы, во-первых, делим каждую из них на три части: условные начало, середину и конец. Во-вторых, используем собственный фонетический алфавит, который учитывает позицию и контекст фонем. Он состоит из 4000 элементарных единиц (вообще-то сочетаний получается больше, но многие из них просто не встречаются в реальной речи, поэтому мы не принимаем их в расчёт). С этим набором и работает наша технология распознавания речи.
Языковая модель
В идеальном мире программа безошибочно определяет, какая фонема соответствует каждому фрагменту голосового запроса. Но даже человек иногда может не понять или не расслышать все звуки и достраивает слово исходя из контекста. Для этого люди опираются на собственный речевой опыт: если ваш собеседник жалуется на заложенный нос, вы поймёте, что у него «насморк», а не «дасморк». Примерно так же работает система распознавания, только вместо речевого опыта она использует языковую модель.
Как и акустическая модель, языковая тоже обучается на большом корпусе текстов. Но в процессе учёбы она обращает внимание не на соответствие звуков и фонем, а на то в какие последовательности — то есть слова и фразы — обычно складываются фонемы.
Языковая модель работает уже не с признаками звука, а с цепочкой фонем — вернее с цепочкой вероятных фонем. Дело в том, что акустическая модель, обработав частотные признаки фрейма, выдаёт не одну конкретную фонему, а несколько — и у каждой из них свой коэффициент вероятности. Несколько упрощая, допустим, что в случае «насморка» акустическая модель выдаст две примерно равно вероятных фонемы в начале слова — [н] и [д]. Теперь в дело вступает языковая модель. Во время обучения «дасморки» встречались ей нечасто, а вот «насморков» — сколько угодно. Поэтому система сделает вывод, что в начале слова, вероятнее всего, была фонема [н].
Примерно так же, исходя из контекста, языковая модель определяет последовательности слов. Например, выбирая между «мама мыла раму» и «мама мыло рама», она предпочтёт первое словосочетание, потому что оно знакомо ей по тренировочному корпусу текстов.
Понимание естественного языка
На этапе понимания естественного языка компьютер имеет дело уже не с самой речью, а с текстом, в который она была преобразована. На самом деле ему совершенно не важно, получен ли этот текст в результате распознавания. Поэтому SpeechKit можно использовать не только в голосовых интерфейсах, но и для создания ботов, способных общаться в мессенжерах, отвечать на письма или смс.
Конечно, сами по себе слова для компьютера ничего не значат. Так же и мы, глядя в текст, написанный на неизвестном нам языке, не можем представить, о чём идёт речь, если только нам не встречаются какие-нибудь знакомые слова. Примерно такая же задача — по знакомым словам и формулировкам понять говорящего — стоит и перед компьютером.
Представьте приложение, которое выполняет функции личного помощника: добавляет встречи в ежедневник, помогает купить билеты в театр, записывает за пользователем умные мысли — всё в таком духе. Этому приложению нужен голосовой интерфейс, чтобы пользователь мог сказать ему: «Устал я что-то, домой пора — вызови такси», а потом просто назвать нужный адрес и не вводить никакие данные вручную.
Чтобы понять, чего хочет пользователь, и активировать нужную функцию, роботу нужно заметить в распознанной речи ключевые слова. В нашем случае — «вызови такси». Этим словам его научил разработчик: они занесены в программу в числе других формулировок вызова такси: «закажи такси», «вызови машину», […] «хочу поехать домой». Естественно, всех вариантов разработчик учесть не может. Поэтому, собрав тестовую версию приложения, он предлагает попользоваться ею друзьям и коллегам — так выясняется, как ещё люди могут заказывать такси.
Все новые формулировки записываются в конфигурационный файл программы, а затем размечаются: в них выделяются слова-маркеры и характерные синтаксические схемы. Анализируя разметку, программа сама учится понимать даже такие формулировки, которых нет в списке, но которые похожи на известные ей конструкции. Например, если в списке есть варианты «вызови машину» и «закажи такси», то и формулировку «закажи машину» программа тоже поймёт.
Синтез речи
Чтобы работать с голосовым интерфейсом компьютера было удобно, он должен уметь не только слышать, но и говорить. Конечно, если сервис не предполагает сложной коммуникации с пользователем, его реплики можно просто заранее записать и проигрывать в нужный момент. Но что если компьютеру придётся использовать в своём вопросе информацию, которую он только что получил от человека? Скажем, для подтверждения даты и адреса доставки? Чтобы он мог с таким справиться, его нужно научить произносить произвольный текст.
Подготовка текста
Задача синтеза речи тоже решается в несколько этапов. Сначала специальный алгоритм подготавливает текст для того, чтобы роботу было удобно его читать: записывает все числа словами, разворачивает сокращения и так далее. Затем текст делится на фразы, то есть на словосочетания с непрерывной интонацией — для этого компьютер ориентируется на знаки препинания и устойчивые конструкции. Для всех слов составляется их фонетическая транскрипция. Например, «какого» поменяется на «какова», ведь иначе робот так и прочитал бы это слово — окая и через «г».
Чтобы понять, как читать слово и где поставить в нём ударение, робот сначала обращается к классическим, составленным вручную словарям, которые встроены в систему. Если нужного слова в словаре нет, компьютер строит транскрипцию самостоятельно — опираясь на правила, заимствованные из академических справочников. Наконец, если обычных правил оказывается недостаточно — а такое случается, ведь любой живой язык постоянно меняется, — он использует статистические правила. Последние формулируются примерно таким же способом, как и правила акустической и языковой моделей: если слово встречалось в корпусе тренировочных текстов, система запомнит, на какой слог в нём обычно делали ударение дикторы.
Произношение и интонирование
Когда транскрипция готова, компьютер рассчитывает, как долго будет звучать каждая фонема, то есть сколько в ней фреймов. Затем каждый фрейм описывается по множеству параметров: частью какой фонемы он является и какое место в ней занимает; в какой слог входит эта фонема; если это гласная, то ударная ли она; какое место она занимает в слоге; слог — в слове; слово — в фразе; какие знаки препинания есть до и после этой фразы; какое место фраза занимает в предложении; наконец, какой знак стоит в конце предложения и какова его главная интонация.
Другими словами, для синтеза каждых 25 миллисекунд речи используется множество данных. Информация о ближайшем окружении обеспечивает плавный переход от фрейма к фрейму и от слога к слогу, а данные о фразе и предложении в целом нужны для создания правильной интонации синтезированной речи.
Чтобы прочитать подготовленный текст, снова используется акустическая модель — но уже не та, что применялась при распознавании. Тогда нужно было установить соответствие между звуками с определёнными характеристиками и фонемами. Вторая акустическая модель, используемая при синтезе, должна, наоборот, по описаниям фреймов составить описания звуков.
Откуда она знает, как правильно произнести фонему или придать верную интонацию вопросительному предложению? Как и две другие модели, о которых мы уже говорили, она учится на текстах и звуковых файлах. Например, в неё можно загрузить аудиокнигу и соответствующий ей текст. Чем больше данных, на которых учится модель, тем лучше её произношение и интонирование.
Голоса
Наконец, о самом голосе. Узнаваемыми наши голоса, в первую очередь, делает тембр, который зависит от особенностей строения органов речевого аппарата у каждого человека. Тембр вашего голоса можно смоделировать, то есть описать его характеристики — для этого достаточно начитать в студии небольшой корпус текстов. После этого данные о вашем тембре можно использовать при синтезе речи на любом языке, даже таком, которого вы не знаете. Когда роботу нужно что-то сказать вам, он использует генератор звуковых волн — вокодер. В него загружаются информация о частотных характеристиках фразы, полученная от акустической модели, а также данные о тембре, который придаёт голосу узнаваемую окраску. Подробнее о возможностях и способах применения Yandex SpeechKit вы можете прочитать на специальном сайте. Если вы разработчик и хотите протестировать облачную или мобильную версию SpeechKit, поищите информацию на странице технологии.
Самый реалистичный синтез русскоязычной речи
Новое поколение синтеза
Мы 20 лет развиваем и совершенствуем технологии работы
со звуком: синтез и распознавание речи, голосовая аутентификация, детектирование акустических событий
Новая технология обеспечивает плавность и выразительность прочтения любого текста. Используются сложные нейросетевые модели, генерирующие высококачественный аудиосигнал, автоматическое исправление ошибок и модуль предсказания ударений в словах не из словаря.
Почему мы самые реалистичные?
Упростилась технология создания собственного уникального голоса на одном из поддерживаемых нами языков. Теперь это возможно сделать за 2 месяца и использовать голос в нашем облаке и в on-premise SDK.
Для on-premise решения можно воспользоваться нашим SDK, который легкого масштабируется для поддержания сотен одновременных запросов на синтез.
Синтезируемая речь соответствует нормам русского языка на сложных текстах. Тем не менее, мы предоставляем возможность работы с SSML-тегами, включая emphasis и prosody, поддерживаем пользовательские словари ударений и сокращений для расширения возможностей управления синтезом и точной настройки на желаемый результат.
Использование оригинальной нейросетевой архитектуры обеспечивает более естественную и выразительную речь.
При этом обеспечиваются возможности управления интонацией и стилем речевой подачи.
Тщательная оптимизация алгоритмов синтеза позволила достичь высокой производительности. Теперь для высококачественного синтеза не требуются дорогостоящие сервера с GPU.
Управление синтезом
Создание собственных голосов
Какие технологии в основе?
Промышленный on-premise SDK
Высокая производительность
Где можно использовать?




Классические
IVR-системы
Системы информирования и оповещения
Чат-боты и голосовые помощники
Общение становится индивидуальным с каждым абонентом за счет реализации IVR-меню с моментальным синтезом любого текста в процессе звонка.
Системы на базе автоматического синтеза речи зачитывают каждому абоненту персональные сообщения.
Вариативность ответов с использованием синтеза выходит на новый уровень. Никаких предварительно записанных фраз.
Независимая оценка качества синтеза
Для получения оценки использовались специализированные сервисы опроса людей. Тестирование проводилось в анонимном режиме. В качестве соперников были взяты системы синтеза речи от Яндекс,
АБК, Google
и живой человек.

Многоязычный синтез речи с клонированием / Хабр
Хотя нейронные сети стали использоваться для синтеза речи не так давно (например), они уже успели обогнать классические подходы и с каждым годам испытывают на себе всё новые и новый задачи.
Например, пару месяцев назад появилась реализация синтеза речи с голосовым клонированием Real-Time-Voice-Cloning. Давайте попробуем разобраться из чего она состоит и реализуем свою многоязычную (русско-английскую) фонемную модель.
Строение
Наша модель будет состоять из четырёх нейронных сетей. Первая будет преобразовывать текст в фонемы (g2p), вторая — преобразовывать речь, которую мы хотим клонировать, в вектор признаков (чисел). Третья — будет на основе выходов первых двух синтезировать Mel спектрограммы. И, наконец, четвертая будет из спектрограмм получать звук.
Наборы данных
Для этой модели нужно много речи. Ниже базы, которые в этом помогут.
Обработка текста
Первой задачей будет обработка текста. Представим текст в том виде, в котором он будет в дальнейшем озвучен. Числа представим прописью, а сокращения раскроем. Подробнее можно почитать в статье посвященной синтезу. Это тяжелая задача, поэтому предположим, что к нам поступает уже обработанный текст (в базах выше он обработан).
Следующим вопросом, которым следуют задаться, это использовать ли графемную, или фонемную запись. Для одноголосного и одноязычного голоса подойдет и буквенная модель. Если хотите работать с многоголосой многоязычной моделью, то советую использовать транскрипцию (Гугл тоже).
G2P
Для русского языка существует реализация под названием russian_g2p. Она построена на правилах русского языка и хорошо справляется с задачей, но имеет минусы. Не для всех слов расставляет ударения, а также не подходит для многоязычной модели. Поэтому возьмём созданный ей словарь, добавим словарь для английского языка и скормим нейронной сети (например этим 1, 2)
Прежде чем обучать сеть, стоит подумать, какие звуки из разных языков звучат похоже, и можно им выделить один символ, а для каких нельзя. Чем больше будет звуков, тем сложнее модели учиться, а если их будет слишком мало, то у модели появиться акцент. Не забудьте ударным гласным выделять отдельные символы. Для английского языка вторичное ударение играет малую роль, и я бы его не выделял.
Кодирование спикеров
Сеть схожа с задачей идентификации пользователя по голосу. На выходе у разных пользователей получаются разные вектора с числами. Предлагаю использовать реализацию самого CorentinJ, которая основана на статье. Модель представляет собой трехслойный LSTM с 768 узлами, за которыми следует полносвязный слой из 256 нейронов, дающие вектор из 256 чисел.
Опыт показал, что сеть, обученная на английской речи, хорошо справляется и с русской. Это сильно упрощает жизнь, так как для обучения требуется очень много данных. Рекомендую взять уже обученную модель и дообучить на английской речи из VoxCeleb и LibriSpeech, а также всей русской речи, что найдёте. Для кодера не нужна текстовая аннотация фрагментов речи.
Тренировка
- Запустите
python encoder_preprocess.py <datasets_root>для обработки данных - Запустите «visdom» в отдельном терминале.
- Запустите
python encoder_train.py my_run <datasets_root>для тренировки кодировщика
Синтез
Перейдём к синтезу. Известные мне модели не получают звук напрямую из текста, так как, это сложно (слишком много данных). Сначала из текста получается звук в спектральной форме, а уже потом четвертая сеть будет переводить в привычный голос. Поэтому сначала поймём, как спектральное вид связанна с голосом. Проще разобраться в обратной задаче, как из звука получить спектрограмму.
Звук разбивается на отрезки длинной 25 мс с шагом 10 мс (по умолчанию в большинстве моделей). Далее с помощью преобразования Фурье для каждого кусочка вычисляется спектр (гармонические колебания, сумма которых даёт исходный сигнал) и представляется в виде графика, где вертикальная полоса — это спектр одного отрезка (по частоте), а по горизонтальной — последовательность отрезков (по времени). Этот график называется спектрограммой. Если же частоту закодировать нелинейно (нижние частоты качественнее, чем верхние), то изменится масштаб по вертикали (нужно для уменьшения данных) то такой график называют Mel спектрограммой. Так устроен человеческий слух, что небольшое отклонение на нижних частотах мы слышим лучше, чем на верхних, поэтому качество звука не пострадает
Существует несколько хороших реализаций синтеза спектрограмм, такие как Tacotron 2 и Deepvoice 3. У каждой из этих моделей есть свои реализации, например 1, 2, 3, 4. Будем использовать(как и CorentinJ) модель Tacotron от Rayhane-mamah.
Tacotron основан на сети seq2seq с механизмом внимания. Ознакомитесь с подробностями в статье.
Тренировка
Не забудьте отредактировать utils/symbols.py, если будете синтезировать не только английскую речь, hparams.pу, а так же preprocess.py.
Для синтеза нужно много чистого, хорошо размеченного звука разных спикеров. Здесь чужой язык не поможет.
- Запустите
python synthesizer_preprocess_audio.py <datasets_root>для создания обработанного звука и спектрограмм - Запустите
python synthesizer_preprocess_embeds.py <datasets_root>для кодирования звука (получения признаков голоса) - Запустите
python synthesizer_train.py my_run <datasets_root>для тренировки синтезатора
Вокодер
Теперь осталось только преобразовать спектрограммы в звук. Для этого служит последняя сеть — вокодер. Возникает вопрос, если спектрограммы получаются из звука с помощью преобразования Фурье, нельзя ли с помощью обратного преобразования получить снова звук? Ответ и да, и нет. Гармонические колебания, из которых состоит исходный сигнал, содержат как амплитуду, так и фазу, а наши спектрограммы содержат информацию только об амплитуде (ради сокращения параметров и работаем со спекрограммами), поэтому если мы сделаем обратное преобразование Фурье, то получим плохой звук.
Для решения этой проблемы придумали быстрый алгоритм Гриффина-Лима. Он делает обратное преобразование Фурье спектрограммы, получая «плохой» звук. Далее делает прямое преобразования этого звука и получают спектр, в котором уже содержится немножко информации о фазе, причём амплитуда в процессе не меняется. Далее берётся еще раз обратное преобразование и получается уже более чистый звук. К сожалению, качество сгенерированной таким алгоритмом речи оставляет желать лучшего.
На его смену пришли нейронные вокодеры, такие как WaveNet, WaveRNN, WaveGlow и другие. CorentinJ использовал модель WaveRNN за авторством fatchord
Для предобработки данных используется два подхода. Либо получить спектрограммы из звука (с помощью преобразования Фурье), или из текста (с помощью модели синтеза). Google рекомендует второй подход.
Тренировка
- Запустите
python vocoder_preprocess.py <datasets_root>для синтеза спектрограмм - Запустите
python vocoder_train.py <datasets_root>для вокодера
Итого
Мы получили модель многоязычного синтеза речи, умеющей клонировать голос.
Запустите toolbox: python demo_toolbox.py -d <datasets_root>
Примеры можно послушать тут
Советы и выводы
- Нужно много данных (>1000 голосов, >1000 часов)
- Скорость работы сравнима с реальным временем только при синтезе минимум 4 предложений
- Для кодера используйте предобученную модель для английского языка, немножко дообучив. Она справляется хорошо
- Синтезатор, обученный на «чистых» данных, работает лучше, но хуже клонирует, чем тот, кто обучался на большем объёме, но грязных данных
- Модель хорошо работает только на данных, на которых училась
Можете синтезировать свой голос онлайн с помощью colab, или посмотреть мою реализацию на github и скачать мои веса.
Использование женских голосов в синтезе речи
Международный женский день отмечался в воскресенье, 8 марта. В этом году тема была «Сделай это возможным». Во всем мире проводились различные мероприятия, посвященные масштабам прав женщин…
Международный женский день отмечался в воскресенье, 8 марта. В этом году тема была «Сделай это возможным». По всему миру различные мероприятия отмечали, насколько далеко продвинулись права женщин, и в то же время ясно указывали на необходимость продолжать борьбу за равные права во всем мире.На ReadSpeaker в честь Международного женского дня мы хотели бы обсудить нечто более близкое и более близкое к целям нашей организации: женские голоса в синтезе речи. Если посмотреть на голоса, доступные для преобразования текста в речь, становится очевидной закономерность: женские голоса более распространены, чем мужские, особенно для языков, на которых было сделано меньше усилий. Мы гордимся тем, что ReadSpeaker предлагает более 100 различных голосов на более чем 40 языках. Однако для некоторых из этих языков мужской голос не входит в наше текущее портфолио; женский голос — единственный вариант.
Предпочитаете ли вы слушать мужской или женский голос, это, конечно, индивидуальное предпочтение. Эти предпочтения также могут зависеть от определенных аспектов голоса. Например, можно в подавляющем большинстве случаев предпочесть женский голос, но только если голос будет спокойным, контролируемым и достаточно ровным с точки зрения тона. Однако есть веские причины, по которым женские голоса чаще используются в некоторых языках для преобразования текста в речь. Наша физическая анатомия приводит к существенным различиям в голосах. У мужчин и женщин голосовые складки разного размера, что связано с разницей в размерах гортани у мужчин и женщин.Длина мужских голосовых складок составляет от 17 до 25 мм, а женских — от 12,5 до 17,55 мм (Источник: Thurman et al. 2000). Эта анатомическая разница приводит к разнице в среднем шаге. Средняя высота звука (основная частота или f0) для стандартного мужского голоса составляет примерно 125 Гц, а для стандартного женского голоса — примерно 200 Гц (Источник: Национальный центр голоса и речи). F0 взрослого мужчины будет в диапазоне от 85 до 155 Гц, а взрослой женщины — от 165 до 255 Гц (Источник: Университет штата Мичиган).Поэтому диапазон взрослого женского голоса больше, чем у взрослого мужчины: 90 Гц по сравнению с 70 Гц в среднем. Вообще говоря, этот больший диапазон упрощает создание синтезированного голоса для использования в преобразовании текста в речь. Огромные различия в основной частоте облегчают различение фонем, и, следовательно, синтезатор лучше способен генерировать речь на основе этих идентифицированных фонем и фрагментов текста (синтез выбора единиц). Дополнительные сведения о синтезе речи из текста см. В нашей предыдущей статье «Как преобразование текста в речь».Проще говоря: «женские голоса более интересны с экономической точки зрения в контексте синтеза речи» (Источник: Dutoit 2001). [Speech-enabled_websites lang = ”en”].
Как сделать редактор синтеза речи — Smashing Magazine
Об авторе
Кнут Мелвер — технолог-гуманитарий, в настоящее время работает адвокатом разработчиков в Sanity.io. Ранее он был консультантом по технологиям и разработчиком в…
Больше о
Кнут
Melvær
…
Голосовые помощники направляются в дома, в запястья и карманы людей. Это означает, что часть нашего контента будет озвучена вслух с помощью цифрового синтеза речи. В этом руководстве вы узнаете, как создать редактор WYGIWYH для синтеза речи с использованием Sanity.Редактор io для Portable Text. 

Когда Стив Джобс представил Macintosh в 1984 году, он сказал нам «привет» со сцены. Даже тогда синтез речи не был новой технологией: Bell Labs разработала вокодер еще в конце 30-х годов, а концепция компьютера голосового помощника стала известна людям, когда Стэнли Кубрик сделал вокодер голосом людей. HAL9000 в 2001: Космическая одиссея (1968).
Только после того, как в середине 2015-х были представлены Apple Siri, Amazon Echo и Google Assistant, голосовые интерфейсы фактически нашли свое применение в домах, запястьях и карманах более широких слоев населения.Мы все еще находимся в стадии внедрения, но, похоже, эти голосовые помощники никуда не денутся.
Другими словами, Интернет — это уже не просто пассивный текст на экране . Веб-редакторы и дизайнеры UX должны привыкнуть к созданию контента и услуг, о которых следует говорить вслух.
Мы уже быстро движемся к использованию систем управления контентом, которые позволяют нам работать с нашим контентом без подключения к голове и через API. Последняя часть — это создание редакционных интерфейсов, которые упростят адаптацию контента для голоса.Так что давайте сделаем это!
Что такое SSML
В то время как веб-браузеры используют спецификацию W3C для языка разметки гипертекста (HTML) для визуального отображения документов, большинство голосовых помощников используют язык разметки синтеза речи (SSML) при генерации речи.
Минимальный пример с использованием корневого элемента , а также тегов абзаца (
) и предложения ( ):
<Р>
Это первое предложение абзаца.
Вот еще одно предложение.
Нажмите кнопку воспроизведения, чтобы прослушать фрагмент:
Ваш браузер не поддерживает
аудио элемент.
SSML появляется, когда мы вводим теги для и (pitch):
<Р>
Сделайте эти слова <акцентом на силу = "strong"> лишним весом
И скажите немного выше и быстрее !
Нажмите кнопку воспроизведения, чтобы прослушать фрагмент:
Ваш браузер не поддерживает
аудио элемент.
SSML имеет больше функций, но этого достаточно, чтобы понять основы. Теперь давайте более подробно рассмотрим редактор, который мы будем использовать для создания интерфейса редактирования синтеза речи.
Редактор переносимого текста
Чтобы создать этот редактор, мы будем использовать редактор переносимого текста, который есть в Sanity.io. Portable Text — это спецификация JSON для редактирования форматированного текста, которая может быть сериализована на любой язык разметки, например SSML. Это означает, что вы можете легко использовать один и тот же фрагмент текста в нескольких местах, используя разные языки разметки.
 Стандартный редактор Sanity.io для переносимого текста (большой предварительный просмотр)
Стандартный редактор Sanity.io для переносимого текста (большой предварительный просмотр)
Установка Sanity
Sanity.io — это платформа для структурированного контента, которая поставляется со средой редактирования с открытым исходным кодом, созданной с помощью React.js. На то, чтобы все это запустить, нужно две минуты.
Введите npm i -g @ sanity / cli && sanity init в свой терминал и следуйте инструкциям. Выберите «пустой», когда вам будет предложено ввести шаблон проекта.
Если вы не хотите следовать этому руководству и создавать этот редактор с нуля, вы также можете клонировать код этого руководства и следовать инструкциям в README.мкр .
Когда редактор загружен, вы запускаете sanity start в папке проекта, чтобы запустить его. Он запустит сервер разработки, который использует Hot Module Reloading для обновления изменений при редактировании его файлов.
Как настроить схемы в Sanity Studio
Создание файлов редактора
Мы начнем с создания папки с именем ssml-editor в папке / schemas . В эту папку мы поместим несколько пустых файлов:
/ ssml-tutorial / schemas / ssml-editor.
├── псевдоним.JS
├── focus.js
├── annotations.js
├── preview.js
├── prosody.js
├── sayAs.js
├── blocksToSSML.js
├── Speech.js
├── SSMLeditor.css
└── SSMLeditor.js
Теперь мы можем добавлять схемы содержимого в эти файлы. Схемы содержимого — это то, что определяет структуру данных для форматированного текста и то, что Sanity Studio использует для создания редакционного интерфейса.Это простые объекты JavaScript, для которых обычно требуется только имя и тип .
Мы также можем добавить заголовок и описание , чтобы сделать его немного удобнее для редакторов. Например, это схема простого текстового поля для заголовка :
экспорт по умолчанию {
имя: 'название',
тип: 'строка',
title: 'Заголовок',
description: "Названия должны быть краткими и информативными"
}
 Студия с нашим полем заголовка и редактором по умолчанию (Большой превью)
Студия с нашим полем заголовка и редактором по умолчанию (Большой превью)
Portable Text построена на идее форматированного текста как данных.Это мощный инструмент, поскольку он позволяет запрашивать форматированный текст и преобразовывать его практически в любую разметку, которую вы хотите.
Это массив объектов, называемых «блоками», которые можно рассматривать как «абзацы». В блоке есть множество дочерних промежутков. Каждый блок может иметь стиль и набор определений меток, которые описывают структуры данных, распределенные по дочерним участкам.
Sanity.io поставляется с редактором, который может читать и писать в переносимый текст, и активируется путем размещения блока типа внутри поля массива , например:
// речи.JS
экспорт по умолчанию {
имя: 'речь',
тип: 'массив',
title: 'Редактор SSML',
из: [
{тип: 'блок'}
]
}
Массив может быть нескольких типов. Для SSML-редактора это могут быть блоки для аудиофайлов, но это выходит за рамки данного руководства.
Последнее, что мы хотим сделать, это добавить тип контента, в котором можно использовать этот редактор. Большинство помощников используют простую модель содержания «намерений» и «выполнения»:
- Намерения
Обычно это список строк, используемых моделью ИИ для обозначения того, что пользователь хочет сделать. - Выполнение
Это происходит при выявлении «намерения». Выполнение часто — или, по крайней мере, — сопровождается какой-то реакцией.
Итак, давайте создадим простой тип контента под названием fillment , который использует редактор синтеза речи. Создайте новый файл с именем fillment.js и сохраните его в папке / schema :
// fillment.js.
экспорт по умолчанию {
имя: 'выполнение',
тип: 'документ',
title: 'Выполнение',
из: [
{
имя: 'название',
тип: 'строка',
title: 'Заголовок',
description: "Названия должны быть краткими и информативными"
},
{
имя: 'ответ',
тип: 'речь'
}
]
}
.
Набор речевых данных M-AILABS — caito
Ниже приводится текст, который сопровождает набор данных речи M-AILABS:
M-AILABS Speech Dataset — это первый большой набор данных, который мы бесплатно предоставляем в качестве обучающих данных для распознавания речи и синтеза речи .
Большая часть данных основана на LibriVox и Project Gutenberg. Данные обучения состоят из почти тысячи часов аудио и текстовых файлов в подготовленном формате.
Для каждого клипа предоставляется транскрипция. Клипы различаются по длине от 1 до 20 секунд, а их общая длина приблизительно указана в списке (и в соответствующих файлах info.txt и ) ниже.
Тексты были опубликованы между 1884 и 1964 годами и находятся в открытом доступе. Аудио записано проектом LibriVox и также находится в открытом доступе — кроме украинского .
Украинский звук был любезно предоставлен Nash Format или Gwara Media только для целей машинного обучения (пожалуйста, проверьте данные info.txt файлов).
Перед загрузкой, пожалуйста, прочтите лицензионное соглашение внизу этой публикации!
Введение
Люди спрашивают нас: «Почему», то есть «почему вы раздаете столь ценные данные».
Быстрый ответ: потому что наша миссия — дать возможность (европейским) компаниям воспользоваться преимуществами искусственного интеллекта и машинного обучения без необходимости отказываться от контроля или ноу-хау.
Полный ответ будет значительно длиннее, но, допустим, мы просто хотим продвинуть использование AI & ML в Европе.
Структура каталога
Каждый язык представлен своим международным кодом ISO для языка + страны (например, de_DE для de = немецкий, DE = Германия) плюс дополнительный каталог by_book .
Ниже вы найдете каталоги с именами:
Данные обучения разделены на женских , мужских и смешанных голосов. В случае смешанного обучения данные обучения содержат смешанные данные мужчин и женщин .
Для каждого голоса есть имя и info.txt , содержащие информацию об обучающих данных. Каждый каталог обучающих данных содержит два файла:
-
metadata.csv -
metadata_mls.json
Полная структура каталогов выглядит так:
Формат
Все аудио-файлы в формате wav, моно и 16000 Гц.
Полные данные обучения находятся в MLS (M-AILABS) — и LJSpeech-Format.Каждая книга содержит свои собственные metadata.csv и metadata_mls.json .
Те из вас, кто знаком с форматом данных LJSpeech, сразу распознают .csv-файл. Файл _mls.json содержит ту же информацию, что и файл .csv , за исключением того, что эта информация находится в формате JSON.
Каждая строка в metadata.csv состоит из имени файла (без расширения) и двух текстов, разделенных « | “-симв.Текст включает символы верхнего и нижнего регистра, специальные символы (например, знаки препинания) и многое другое. Если вам нужен чистый текст, очистите его перед использованием. Для синтеза речи иногда нужны все специальные символы.
Первый текст содержит полностью исходные данные, включая ненормализованных чисел, и т. Д. Вторая версия текста содержит нормализованную версию , что означает, что числа были преобразованы в слова и некоторая очистка от «чужих» символов (транслитерации ) были применены.
Оба файла в формате UTF-8. Не пытайтесь читать в ASCII, это не сработает.
grune_haus_01_f000002 | Ja, es ist ein grünes Haus, in dem ich 1989 wohne ... | ... eintausendneunhundert ... grune_haus_01_f000003 | Es ist nicht etwa grün angestrichen wie ein Gartenzaun ... grune_haus_01_f000004 | die Menschen verstehen noch immer nicht die Farben so ... grune_haus_01_f000005 | Dann wachsen die Haselsträucher und die Kletterrosen so ... grune_haus_01_f000006 | und wenn der Wind kommt, weht er Laub und Blütenblätter... grune_haus_01_f000007 | In diesem grünen Hause wohne ich mit meinen drei Kindern ... grune_haus_01_f000008 | die noch nicht in die Schule geht und ein großer Wildfang ... grune_haus_01_f000009 | Denkt nur, neulich wollte sie durchaus die Blumen von meinem ... ...
Файлы .wav можно найти в каталоге wavs в том же каталоге, что и файл metadata.csv .
Примечание: каждый файл .wav имеет 0,5 секунды тишины в начале и в конце.Если он вам не нужен, вы можете просто удалить его с помощью sox или ffmpeg .
Использование
Если у вас есть обучающая модель, которая поддерживает формат данных LJSpeech для предварительной обработки, вы можете просто запустить этот инструмент предварительной обработки на metadata.csv , и жизнь будет в порядке. В противном случае вам нужно будет выполнить предварительную обработку самостоятельно.
В исходном формате, который мы предоставляем, файлы разделены, как показано в структуре каталогов выше.
Но, поскольку все .wav -файлы на данном языке имеют гарантированных уникальных имен , вы можете скопировать их все в один wavs -каталог и сгенерировать для этого metadata.csv , используя следующую команду оболочки (Linux + macOS) :
cat... >> new_metadata.csv
Некоторые советы по использованию данных
Важно знать, что языки со временем развиваются и вводят слова из других языков.Например, слово «Exposé» существует в немецком языке и было «импортировано» из французского. Но символ «é» не является базовым знаком немецкого алфавита. Он существует только для специальных целей, подобных показанному здесь.
У вас есть два варианта (второй — лучший вариант):
- Оставьте как есть и добавьте символ «é» к немецкому набору символов
- Заменить его на «e», что сделано в транслитерированной версии текста (второй столбец)
В первом случае это может привести к «не очень хорошему» обучению, поскольку этот персонаж не появляется слишком часто, и ваша DNN может плохо учиться.Опять же, вы, , возможно, захотите разделить «e» и «é».
Во втором случае это слово будет выучено так же, как «Expose», что может быть не тем, что вам нужно.
Это действительно для всех текстов, в том числе на других языках. После некоторого обсуждения мы решили, что не удаляет данные , а вместо этого предоставит вам решать, какую информацию использовать, а какую не использовать. Таким образом, мы предоставляем вам обе версии текста: версию, включающую эти символы, и версию, в которой эти символы транслитерированы (e.g. турецкое «ç», если оно встречается в немецком тексте, транслитерируется как «tsch»).
Для распознавания речи мы обычно генерируем несколько версий одних и тех же данных в плоской структуре каталогов. В каждую дополнительную версию добавлен шум, такой как фон кафе, город, многолюдные рынки, центры обработки данных, шум мегаполиса, поезд, говорящие люди и многое другое. Если мы добавим весь наш шум, например, к немецкому языку, мы обычно генерируем около 2800 часов тренировочных данных из существующих чистых 237 часов. Мы рекомендуем вам поэкспериментировать с похожими подходами.
Поскольку данные используются для распознавания речи (STT), а также для синтеза речи, мы предоставляем здесь версии с чистым звуком.
Предупреждение: в некоторых очень, очень редких случаях может отсутствовать файл wav , хотя имя файла отображается в файле metadata.csv . В этих случаях вы можете просто проигнорировать запись. Мы обнаружили около шести (!) Случаев, когда это происходит (en_UK: 2, en_US: 3, es_ES: 1). Потерпите, нужно было обработать сотни тысяч файлов…
Наборы символов
Следующие наборы символов были использованы в данных в транслитерированной, очищенной версии :
ASCII: 'ABCDEFGHIJKLMNOPQRSTUVWYXZabcdefghijklmnopqrstuvwxyz0123456789! \', -.:;? '
Английский: ASCII
Немецкий: ASCII + 'äöüßÄÖÜ'
Итальянский: ASCII + 'àéèìíîòóùúÀÉÈÌÍÎÒÓÙÚ'
Испанский: ASCII + '¡¿ñáéíóúÁÉÍÓÚÑ'
Французский: ASCII + 'àâæçéèêëîïôœùûüÿŸÜÛÙŒÔÏÎËÊÈÉÇÆÂÀ'
Украинский: ASCII +
Русский: ASCII +
Польский: ASCII +
Статистика и ссылки для скачивания
| Язык | Страна | Тег | Длина | Размер | DL Размер | Образец | DL Ссылка |
|---|---|---|---|---|---|---|---|
| Немецкий | Германия | de_DE | 237ч 22м | 27 ГиБ | 20 ГиБ | Ф / М | СКАЧАТЬ |
| Английский | Королевы | ru_UK | 45ч 34м | 4.9 ГиБ | 3,5 ГиБ | Ф / М | СКАЧАТЬ |
| Английский | США | ru_US | 102ч 07м | 11 ГиБ | 7,5 ГиБ | Ф / М | СКАЧАТЬ |
| Испанский * | Испания | es_ES | 108ч 34м | 12 ГиБ | 8,3 ГиБ | Ф / М | СКАЧАТЬ |
| Итальянский | Италия | it_IT | 127ч 40м | 14 ГиБ | 9.5 ГиБ | Ф / М | СКАЧАТЬ |
| Украинский | Украина | uk_UK | 87ч 08м | 9,3 ГиБ | 6,7 ГиБ | Ф / М | СКАЧАТЬ |
| Русский | Россия | ru_RU | 46ч 47м | 5,1 ГиБ | 3,6 ГиБ | Ф / М | СКАЧАТЬ |
| Французский v0.9 ** | Франция | fr_FR | 190ч 30м | 21 ГиБ | 15 ГиБ | Ф / М | СКАЧАТЬ |
| Польский * | Польша | пл_ПЛ | 53ч 50м | 5.8 ГиБ | 4,2 ГиБ | Ф / М | СКАЧАТЬ |
| ИТОГО (можно загрузить) | 999х 32м | ~ 110 ГиБ | ~ 78 ГиБ |
*: Мне сообщили, что говорящий «карен» — мексиканец, а говорящий «победитель» — аргентинский. С одной стороны, я прошу прощения за случившееся. С другой стороны, это добавляет в коллекцию несколько часов латиноамериканского испанского.Обратите внимание на эту разницу.
**: французский — v0.9, т.е. без транслитерации и нормализации чисел.
Лицензия
Авторские права (c) 2017-2019 исходными авторами @ M-AILABS со следующей лицензией:
Распространение и использование в любой форме, включая любое коммерческое использование, с изменениями или без них, разрешается при соблюдении следующих условий:
- При повторном распространении исходных данных должно сохраняться указанное выше уведомление об авторских правах, этот список условий и следующий отказ от ответственности.
- Ни имя правообладателя, ни имена его участников не могут использоваться для поддержки или продвижения продуктов, полученных из этих загруженных данных, исходного кода или двоичного кода без специального предварительного письменного разрешения.
НАСТОЯЩИЕ ДАННЫЕ ПРЕДОСТАВЛЯЮТСЯ ВЛАДЕЛЬЦАМИ АВТОРСКИХ ПРАВ И СОСТАВЛЯЮЩИМИ «КАК ЕСТЬ» И ЛЮБЫМИ ЯВНЫМИ ИЛИ ПОДРАЗУМЕВАЕМЫМИ ГАРАНТИЯМИ, ВКЛЮЧАЯ, НО НЕ ОГРАНИЧИВАЯСЬ, ПОДРАЗУМЕВАЕМЫЕ ГАРАНТИИ КОММЕРЧЕСКОЙ ЦЕННОСТИ И ПРИГОДНОСТИ ДЛЯ ОПРЕДЕЛЕННОЙ ЦЕЛИ. ВЛАДЕЛЬЦА АВТОРСКИХ ПРАВ ИЛИ СОСТАВНИКИ НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ НЕСЕТ ОТВЕТСТВЕННОСТИ ЗА ЛЮБЫЕ ПРЯМЫЕ, КОСВЕННЫЕ, СЛУЧАЙНЫЕ, ОСОБЫЕ, ПРИМЕРНЫЕ ИЛИ КОСВЕННЫЕ УБЫТКИ (ВКЛЮЧАЯ, НО НЕ ОГРАНИЧИВАЯСЬ, ЗАКУПКИ ТОВАРОВ ИЛИ УСЛУГ; ПОТЕРЮ ИСПОЛЬЗОВАНИЯ ИЛИ ИСПОЛЬЗОВАНИЯ ДАННЫХ; ИЛИ ПЕРЕРЫВ В ДЕЯТЕЛЬНОСТИ), ОДНАКО ВЫЗВАННЫМИ И ПО ЛЮБОЙ ТЕОРИИ ОТВЕТСТВЕННОСТИ, БЕЗ ПРЕДВАРИТЕЛЬНОЙ ОТВЕТСТВЕННОСТИ ИЛИ ПЕРЕДАЧИ (ВКЛЮЧАЯ НЕБРЕЖНОСТЬ ИЛИ ИНОЕ), ВОЗНИКАЮЩИХ ЛЮБОЙ СПОСОБОМ ИСПОЛЬЗОВАНИЯ ДАННОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ и / или ДАННЫХ, ДАЖЕ, ЕСЛИ РЕКОМЕНДУЕМЫЕ ТАКОГО ПОВРЕЖДЕНИЯ.
Заключительные слова
Надеемся, что вы создадите самые интересные, увлекательные и насыщенные решения для распознавания и синтеза речи. Пожалуйста, свяжитесь с нами, если вы что-то разработали и / или продали на основе этих данных. Мы были бы рады это услышать.
Если у вас возникнут вопросы, свяжитесь со мной.
По состоянию на октябрь 2018 г. эти данные любезно предоставлены Имдатом Солаком.
Любые лицензионные ограничения, которые вы можете найти в загруженных данных, снимаются, выше показана только действующая лицензия (которая еще более бесплатна, чем раньше).
,
API синтеза речи
API синтеза речи — отличный инструмент, предоставляемый современными браузерами.
Представленный в 2014 году, теперь он широко используется и доступен в Chrome, Firefox, Safari и Edge. IE не поддерживается.
Это часть Web Speech API вместе с Speech Recognition API , хотя в настоящее время он поддерживается только в экспериментальном режиме в Chrome.
Недавно я использовал его, чтобы выдать предупреждение на странице, отслеживающей некоторые параметры.Когда один из номеров вырос, меня насторожили динамики компьютера.
Начало работы
Самый простой пример использования Speech Synthesis API остается в одной строке:
SpeechSynthesis.speak (новый SpeechSynthesisUtterance ('Эй'))
Скопируйте и вставьте его в консоль браузера, и ваш компьютер должен говорить!
API
API предоставляет несколько объектов объекту window .
Синтез речи
SpeechSynthesisUtterance представляет речевой запрос.В приведенном выше примере мы передали ему строку. Это сообщение браузер должен прочитать вслух.
После получения объекта высказывания можно выполнить некоторые настройки для редактирования свойств речи:
const utterance = new SpeechSynthesisUtterance ('Привет')
-
utterance.rate: установите скорость, принимает значение от [0,1 — 10], по умолчанию 1 -
utterance.pitch: установите высоту звука, принимает значение от [0 — 2], по умолчанию 1 -
высказывание.volume: устанавливает громкость, принимает от [0 — 1], по умолчанию 1 -
utterance.lang: установите язык (значения используют языковой тег BCP 47, напримерen-USилиit-IT) -
utterance.text: вместо того, чтобы устанавливать его в конструкторе, вы можете передать его как свойство. Текст может содержать максимум 32767 символов -
utterance.voice: устанавливает голос (подробнее об этом ниже)
Пример:
const utterance = new SpeechSynthesisUtterance ('Привет')
произнесение.шаг = 1,5
utterance.volume = 0,5
utterance.rate = 8
speechSynthesis.speak (произнесение)
Установить голос
В браузере доступно другое количество голосов.
Для просмотра списка используйте этот код:
console.log (`Голоса #: $ {speechSynthesis.getVoices (). Length}`)
SpeechSynthesis.getVoices (). forEach (voice => {
console.log (voice.name, voice.lang)
})
Вот одна из проблем кроссбраузерности. Приведенный выше код работает в Firefox, Safari (и, возможно, в Edge, но я его не тестировал), но не работает в Chrome .Chrome требует обработки голосов по-другому и требует обратного вызова, который вызывается при загрузке голосов:
const voiceschanged = () => {
console.log (`Голоса #: $ {speechSynthesis.getVoices (). length}`)
SpeechSynthesis.getVoices (). forEach (voice => {
console.log (voice.name, voice.lang)
})
}
SpeechSynthesis.onvoiceschanged = voiceschanged
После вызова обратного вызова мы можем получить доступ к списку с помощью speechSynthesis.getVoices () .
Я считаю, что это связано с тем, что Chrome — при наличии сетевого подключения — проверяет дополнительные языки с серверов Google:
При отсутствии сетевого подключения количество доступных языков такое же, как в Firefox и Safari. Дополнительные языки доступны там, где сеть включена, но API также работает в автономном режиме.
Кроссбраузерная реализация для получения языка
Поскольку у нас есть это различие, нам нужен способ абстрагироваться от него для использования API.В этом примере выполняется такая абстракция:
const getVoices = () => {
вернуть новое обещание (resolve => {
let voices = speechSynthesis.getVoices ()
if (voices.length) {
Решимость (голос)
возвращение
}
SpeechSynthesis.onvoiceschanged = () => {
голоса = SpeechSynthesis.getVoices ()
Решимость (голос)
}
})
}
const printVoicesList = async () => {
; (ждать getVoices ()). forEach (voice => {
console.log (voice.name, voice.lang)
})
}
printVoicesList ()
Смотрите на глюк
Использовать собственный язык
Голос по умолчанию говорит на английском.
Вы можете использовать любой язык, который хотите, установив свойство utterance lang :
let utterance = new SpeechSynthesisUtterance ('Ciao')
utterance.lang = 'это-ИТ'
speechSynthesis.speak (произнесение)
Использовать другой голос
Если доступно более одного голоса, вы можете выбрать другой. Например, итальянский голос по умолчанию женский, но, возможно, мне нужен мужской голос. Это второй, который мы получаем из списка голосов.
const lang = 'это-ИТ'
const voiceIndex = 1
const Speak = async text => {
if (! SpeechSynthesis) {
возвращение
}
const message = new SpeechSynthesisUtterance (текст)
сообщение.voice = await chooseVoice ()
speechSynthesis.speak (сообщение)
}
const getVoices = () => {
вернуть новое обещание (resolve => {
let voices = speechSynthesis.getVoices ()
if (voices.length) {
Решимость (голос)
возвращение
}
SpeechSynthesis.onvoiceschanged = () => {
голоса = SpeechSynthesis.getVoices ()
Решимость (голос)
}
})
}
const chooseVoice = async () => {
const voices = (ожидание getVoices ()). filter (voice => voice.lang == lang)
вернуть новое обещание (resolve => {
Решимость (голос [voiceIndex])
})
}
говорят ( 'Ciao')
Смотрите на глюк
Значения для языка
Вот несколько примеров языков, которые вы можете использовать:
- Арабский (Саудовская Аравия) ➡️
ar-SA - Китайский (Китай) ➡️
zh-CN - Китайский (САР Гонконг) ➡️
zh-HK - Китайский (Тайвань) ➡️
zh-TW - Чехия (Чехия) ➡️
cs-CZ - Датский (Дания) ➡️
da-DK - Голландский (Бельгия) ➡️
nl-BE - Голландский (Нидерланды) ➡️
nl-NL - Английский (Австралия) ➡️
en-AU - Английский (Ирландия) ➡️
en-IE - Английский (Южная Африка) ➡️
en-ZA - Английский (Великобритания) ➡️
en-GB - Английский (США) ➡️
en-US - Финский (Финляндия) ➡️
fi-FI - Французский (Канада) ➡️
fr-CA - Французский (Франция) ➡️
fr-FR - Немецкий (Германия) ➡️
de-DE - Греческий (Греция) ➡️
el-GR - хинди (Индия) ➡️
привет-IN - Венгерский (Венгрия) ➡️
hu-HU - Индонезийский (Индонезия) ➡️
id-ID - итальянский (Италия) ➡️
it-IT - Японский (Япония) ➡️
ja-JP - Корейский (Южная Корея) ➡️
ko-KR - Норвежский (Норвегия) ➡️
no-NO - Польский (Польша) ➡️
pl-PL - Португальский (Бразилия) ➡️
pt-BR - Португальский (Португалия) ➡️
pt-PT - Румынский (Румыния) ➡️
ro-RO - Русский (Россия) ➡️
ru-RU - Словацкий (Словакия) ➡️
sk-SK - Испанский (Мексика) ➡️
es-MX - Испанский (Испания) ➡️
es-ES - Шведский (Швеция) ➡️
sv-SE - Тайский (Таиланд) ➡️
th-TH - Турецкий (Турция) ➡️
tr-TR
Мобильный
В iOS API работает, но должен запускаться обратным вызовом действия пользователя, например ответом на событие касания, чтобы обеспечить пользователям лучший опыт и избежать неожиданных звуков из телефона.
Вы не можете сделать так, как на рабочем столе, где вы можете заставить свои веб-страницы говорить что-то неожиданное.
,