Google база данных: Гугл таблицы как база данных
Google BigQuery — зачем нужна облачная база данных
Ранее я публиковал цикл материалов о работе с Google BigQuery. В этой статье расскажу о преимуществах и особенностях сервиса, а также о дополнительных инструментах для BigQuery.
Google BigQuery — это облачная база данных с высочайшей скоростью обработки огромных массивов данных.
Как начать работу в Google BigQuery
Войдите в Google Cloud Platform. При первом запуске система предложит активировать бесплатный пробный период и получить кредит $300 на 12 месяцев. Честно говоря, чтобы потратить за год в BigQuery эту сумму, вам придется очень сильно постараться.

Для дальнейшей работы введите платежные данные.

Нажмите «Выбрать проект».

Затем — «Создать проект».
Примите условия использования платформы.
Наконец, назовите проект, задайте настройки уведомлений и еще раз согласитесь с условиями использования платформы.
После подтверждения подождите несколько минут.
Вскоре вы получите оповещение, что проект создан.

Перейдите в раздел оплаты и привяжите платежный аккаунт.
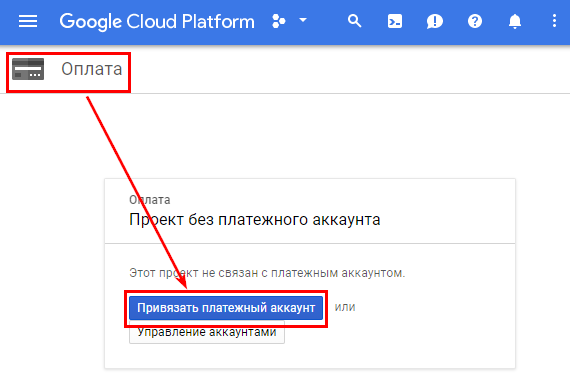
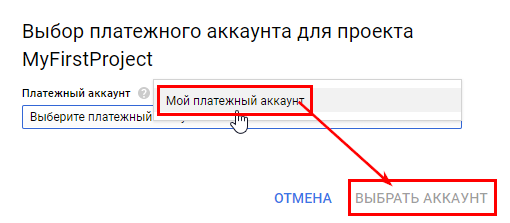
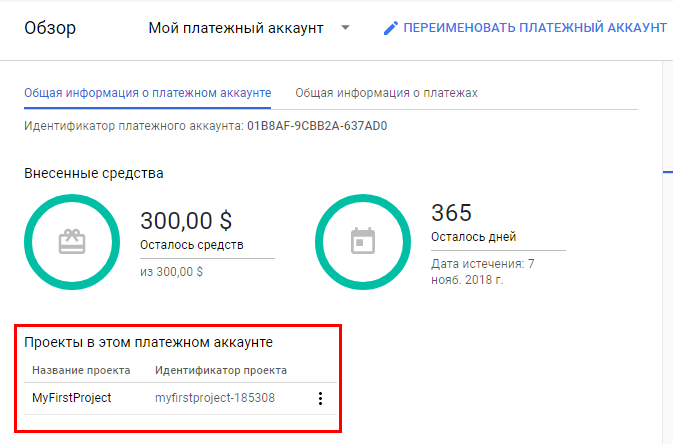
Теперь проект привязан к только что созданному платежному аккаунту.
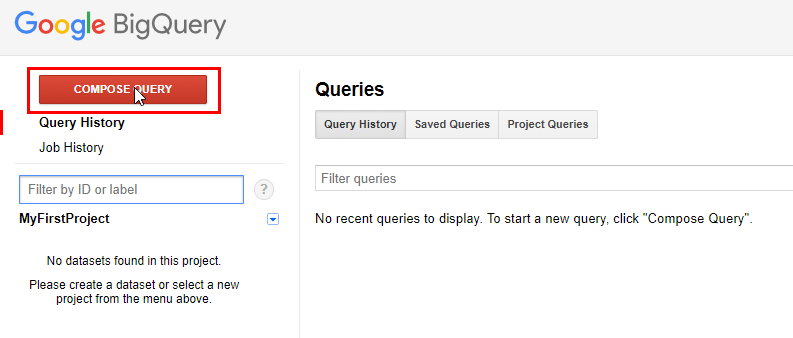
Перейдите в интерфейс Google BigQuery и напишите свой первый запрос.
Чтобы открыть редактор запросов, нажмите «Compose query» или сочетание клавиш «Ctrl + Space».
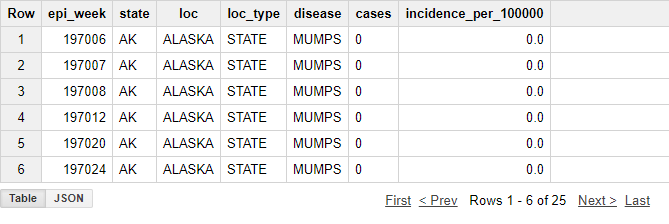
Рассмотрим, как написать первый запрос на примере публичных данных в BigQuery. Возьмите первые 15 строк из таблицы project_tycho_reports, которая находится в наборе публичных данных lookerdata.
SELECT *
FROM [lookerdata:cdc.project_tycho_reports]
LIMIT 25Запрос вернет результат:
Ранее я описывал самые простые способы загрузки собственных данных в Google BigQuery, а в этой статье расскажу, как загрузить данные с помощью языка R. Но перед этим разберем важный вопрос.
{«0»:{«lid»:»1573230077755″,»ls»:»10″,»loff»:»»,»li_type»:»em»,»li_name»:»email»,»li_ph»:»Email»,»li_req»:»y»,»li_nm»:»email»},»1″:{«lid»:»1596820612019″,»ls»:»20″,»loff»:»»,»li_type»:»hd»,»li_name»:»country_code»,»li_nm»:»country_code»}}
Истории бизнеса и полезные фишки
Почему стоит выбрать именно Google BigQuery
Скорость — это основное преимущество BigQuery, но не единственное. BigQuery — облачный сервис. При его использовании не понадобится арендовать сервер и оплачивать поддержку.
Стоимость BigQuery значительно ниже стоимости аренды самого примитивного сервера: даже если вы очень постараетесь и будете ежедневно записывать в эту базу данных миллионы строк, все равно вряд ли сможете потратить более $5.
Следующее преимущество — простота использования. В любой другой системе управления базами данных (СУБД) помимо знания SQL придется долго разбираться с тонкостями администрирования и настройками базы.
И если сам по себе SQL-диалект во всех базах данных очень похожий, то административная часть, как правило, везде устроена по-разному.
У BigQuery всю административную часть на себя взял Google. В этом сервисе нет никаких настроек, индексов, движков таблиц, тайм-аутов или внешних ключей. Реализована поддержка только одной кодировки UTF-8.
Для работы с BigQuery достаточно знать, как загрузить данные в BigQuery, и иметь базовые знания в SQL.
Несмотря на простоту, в BigQuery реализована поддержка практически всех функций СУБД:
Правда, на момент публикации статьи сервис не поддерживает:
- рекурсивные запросы;
- создание хранимых процедур и функций;
- транзакции.
Особенности SQL для Google BigQuery
BigQuery умеет переключаться между стандартным SQL и диалектами.
DML-операции INSERT, UPDATE и DELETE на данный момент поддерживаются только при использовании стандартного SQL.
Еще одно отличие между этими диалектами — способ вертикального объединения таблиц. В стандартном SQL для этого служит оператор UNION и ключевое слов ALL или DISTINCT:
SELECT 12 AS A, 32 AS B
UNION ALL
SELECT 2 AS A, 29 AS BВ собственном SQL-диалекте функционал для вертикального объединения таблиц значительно шире. Существует специальный набор функций подстановки таблиц (Table Wildcard Functions).
Этот способ объединения таблиц я уже подробно описывал ранее.
Для простого объединения достаточно просто перечислить названия нужных таблиц или подзапросы через запятую. Объединение запросов из примера выше на внутреннем диалекте SQL в BigQuery будет выглядеть так:
SELECT *
FROM (SELECT 12 AS A, 32 AS B), (SELECT 2 AS A, 29 AS B)Переключатель между SQL-диалектами в BigQuery находится в интерфейсе в блоке опций: нажмите кнопку Show options под редактором запросов.
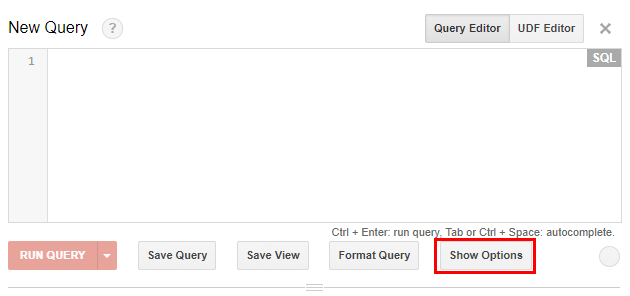
С помощью галочки «SQL Dialect» переключитесь на нужный диалект.
Инструменты для работы с BigQuery
Мы уже разобрались, как загружать данные в базу и как обращаться к данным SQL запросами. Но вряд ли вы хотите взаимодействовать с данными, ограничившись этими возможностями. Скорее всего, вы загружаете данные для построения дашбордов или чего-то подобного.
Как получить данные в различных BI платформах, я писал в статьях об интеграции с электронными таблицами и Microsoft Power BI.
Microsoft Power BI, как и большинство популярных BI-систем и электронных таблиц, с июля 2017 года поддерживает интеграцию с Google BigQuery из коробки. У коннектора довольно скудные возможности: он не умеет обращаться к сохраненным представлениям или отправлять в BigQuery запросы. Пока что с помощью встроенного коннектора можно вытягивать только плоские таблицы.
Simba Drivers
Если вам необходимо получить данные из Google BigQuery в электронной таблице или BI-системе, которая из коробки не поддерживает интеграцию, воспользуйтесь бесплатным Simba Drivers.
Этот драйвер поддерживает все необходимые возможности, включая переключения SQL-диалектов. Подробности настройки ищите в моей статье о связке Microsoft Power BI и Google BigQuery.
Язык R
Язык R — один из самых мощных инструментов для работы с данными. Он умеет как получать данные из Google BigQuery, так и записывать их. Для этого удобнее всего пакет bigrquery.
Для начала установите язык R. Также для удобства работы с R я рекомендую установить интегрированную среду разработки RStudio.
Запустите RStudio и с помощью сочетания клавиш «Ctrl+Alt+Shift+0» откройте все доступные в ней панели. Чаще всего понадобятся панели Source и Console.
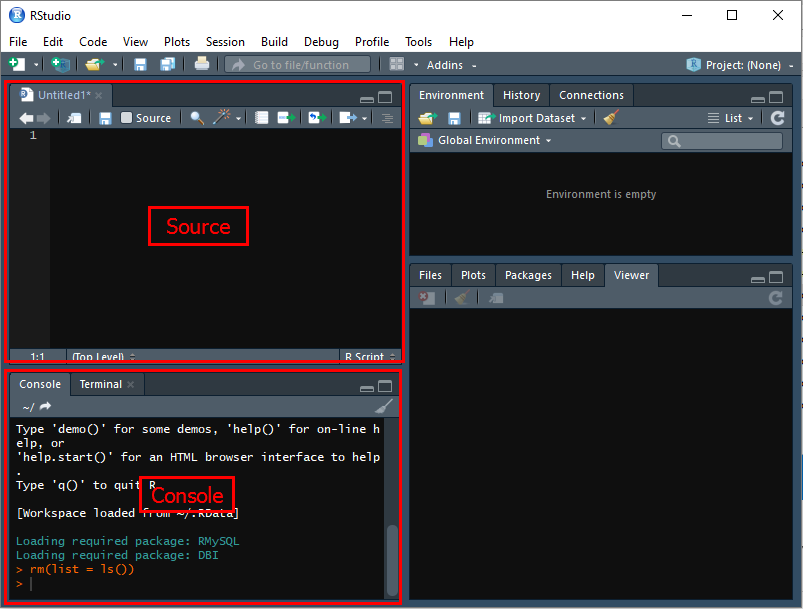
Для установки develop-версии пакета bigrquery из репозитория на GitHub предварительно установите пакет devtools. Введите в окно Source код, затем выделите его (зажмите левой кнопки мыши) и нажмите «Ctrl+Enter» для выполнения команды:
install.packages("devtools")Теперь установите пакет bigrquery:
devtools::install_github("rstats-db/bigrquery")Чтобы в R были доступны функции пакета, после установки подключите их с помощью команды library или require. Например, подключим пакет bigrquery с помощью кода:
library(bigrquery)Структура данных в Google BigQuery состоит из проекта с набором данных, содержащим таблицы. Проект вы уже создали, а теперь для передачи информации создайте набор данных. Выберите в интерфейсе из выпадающего меню «Create new dataset».
Чтобы создать набор данных с помощью языка R, воспользуйтесь командой insert_dataset. Команда требует всего 2 аргумента:
project — ID проекта (возьмите из URL в BigQuery).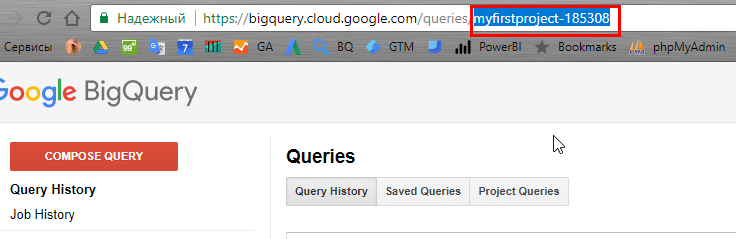
dataset — название нового набора данных.
Давайте создадим первый набор данных с названием myFirstDataSet. Введите в область Source приведенный ниже код, выделите команду с помощью мыши и нажмите «Ctrl+Enter» для выполнения.
insert_dataset(project = "myfirstproject-185308", dataset = "myFirstDataSet")В окне Console в RStudio появится запрос о создании учетных данных, чтобы в дальнейшем не требовалась повторная аутентификация.
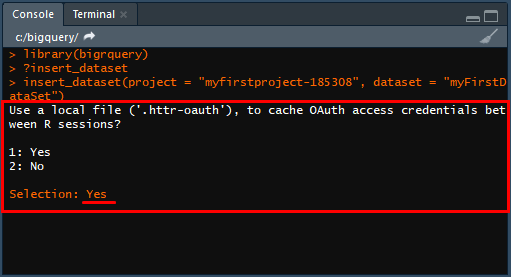
Введите на запрос Selection в Console ответ Yes и нажмите Enter. Откроется браузер — разрешите доступ к данным и получите авторизационный код.
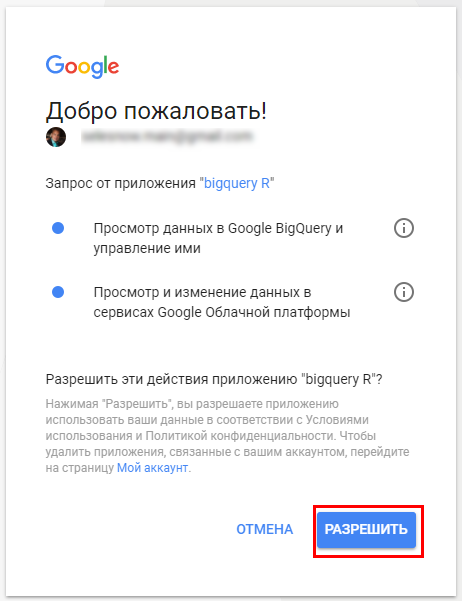
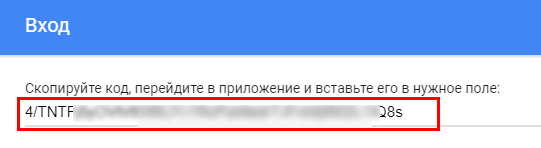
Скопируйте сгенерированный код. Затем вставьте его в Console RStudio в ответ на запрос авторизационного кода и нажмите Enter.
Отлично, вы создали набор данных.
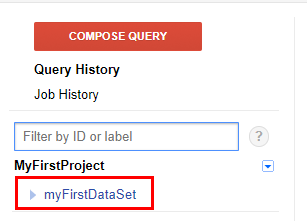
Теперь запишите встроенную в R таблицу mtcars в набор данных myFirstDataSet. Для передачи данных из R в BigQuery в пакете bigrquery есть функция insert_upload_job. Она принимает такие аргументы:
project — ID проекта (смотрите либо в URL проекта, либо в режиме переключения проектов).
dataset — название набора данных, куда вы планируете отправить данные. В нашем случае myFirstDataSet.
table — название таблицы с записанными данными.
values — data frame (таблица данных) в R с данными для передачи в BigQuery.
billing = project аккаунта для оплаты операции. По умолчанию — платежный аккаунт, который привязан к проекту.
create_disposition — опция для определения необходимых действий.
Если в BigQuery нет таблицы с заданным в аргументе table названием, укажите «CREATE_IF_NEEDED» — система создаст новую таблицу.
Если указать «CREATE_NEVER» и таблица с заданным именем не найдется в наборе данных, будет возвращена соответствующая ошибка.
write_disposition — опция для выбора добавления данных в существующую таблицу.
«WRITE_APPEND» — дописать данные в таблицу.
«WRITE_TRUNCATE» — перезаписать данные в таблице.
«WRITE_EMPTY» — записать данные для пустой таблицы.
Код для передачи в BigQuery встроенной в R таблицы mtcars:
insert_upload_job(project = "myfirstproject-185308",
dataset = "myFirstDataSet",
table = "mtcars_bigquery",
values = mtcars,
create_disposition = "CREATE_IF_NEEDED",
write_disposition = "WRITE_APPEND")
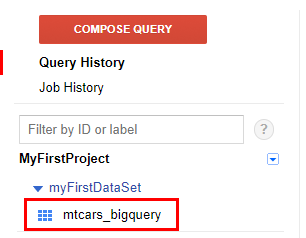
При успешном выполнении операции в консоли R появится дополнительная информация, а в интерфейсе BigQuery — созданная таблица mtcars_bigquery.
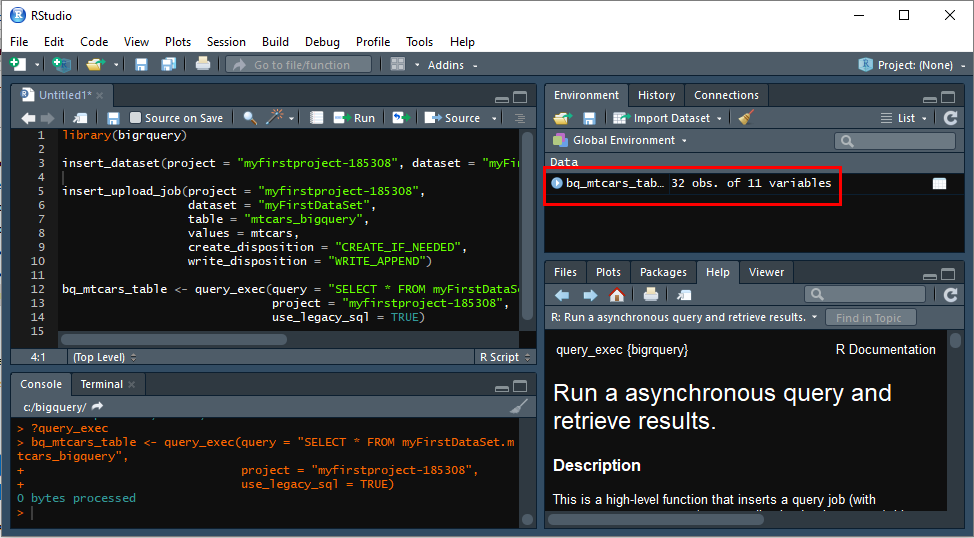
Для запроса данных из BigQuery в R в пакете bigrquery предназначена функция query_exec. Основные аргументы:
query — текст SQL-запроса, результат которого вы хотите загрузить в R.
project — ID проекта для запроса данных.
page_size — максимальный размер возвращаемого результата в строках (по умолчанию 10 000).
max_pages — максимальное количество страниц возврата запросом (по умолчанию 10).
use_legacy_sql — выбор SQL-диалекта для обработки запроса.
По умолчанию задано значение TRUE с внутренним диалектом BigQuery.
Для стандартного диалекта SQL задайте в этом аргументе значение FALSE.
Для обратного запроса данных, которые вы отправили в BigQuery на прошлом шаге, задайте команду:
bq_mtcars_table <- query_exec(query = "SELECT * FROM myFirstDataSet.mtcars_bigquery",
project = "myfirstproject-185308",
use_legacy_sql = TRUE)В рабочем окружении (описание которого вы видите в окне Environment) появится новый объект bq_mtcars_table.
Выводы
Google BigQuery — простой и в то же время мощнейший инструмент для хранения и обработки данных. Это облачная база данных с поддержкой большинства функций СУБД.
Сервис обходится значительно дешевле содержания, поддержки и администрирования сервера для бесплатных баз данных (MySQL или PostgreSQL).
Надеюсь, мой цикл инструкций для начала работы с Google BigQuery упростит ваши будни.
Успехов в работе с большими данными!
распределенная база данных, созданная Google / Хабр
Как сообщается в опубликованном описании Bigtable (PDF), распределенная система спроектирована для хранения и управления огромным массивом структурированных данных. Главным требованием к распределенной базе является ее масштабируемость. Система содержит сотни терайбайт информации на тысячах взаимозаменяемых серверов Google.
Распределенная база данных Bigtable используется во множестве фирменных сервисов, в том числе в Google Analytics, Google Finance, Orkut, Personalized Search, Writely, Google Earth и, разумеется, в главной системе веб-индексации. Каждое из этих приложений выдвигает свои собственные требования к базе данных. Значительно разнятся и объемы хранимой информации. Например, спутниковые фотографии Google Earth занимают примерно столько же места, сколько и поисковый индекс всего интернета.
В описании Bigtable приводится объем информации, который хранится в распределенной базе данных и уровень сжатия. Вся информация приводится по состоянию на август 2006 г.
Поисковая база веб-документов состоит из двух частей: 800 и 50 терабайт с уровнем компрессии 11% и 33%, соответственно. База Google Analytics тоже хранится в двух таблицах на 200 ТБ (14%) и 20 ТБ (29%).
Google Earth занимает 70,5 ТБ, из них 70 ТБ исходных изображений и 500 ГБ индекса.
Персональный поиск занимает очень мало места по сравнению с самыми ресурсоемкими приложениями: всего 4 ТБ (уровень компрессии 47%). Каждому пользователю в системе присваивается уникальный идентификатор, а все его действия на поисковом сайте заносятся в базу данных.
Система Google Base использует 2 ТБ, а социальная сеть Orkut — всего 9 ТБ места в базе данных.
Если посчитать, сколько реального дискового пространства занимают все сервисы Google с учетом компрессии, то получится около 220 ТБ.
К сожалению, в опубликованном документе отсутствует всякое упоминание о почтовой системе Gmail, а ведь миллионы почтовых ящиков объемом несколько гигабайтов каждый требуют немалых ресурсов.
Впрочем, даже с учетом аккаунтов Gmail все дисковые массивы компании Google кто-то может назвать совсем небольшими. Например, нефтедобывающие компании или другие корпорации, которые имеют дело с геоинформационными системами, могут хранить у себя на серверах даже большие объемы данных, чем Google. У них счет может идти не на сотни терабайт, а на петабайты. В этом смысле лозунг Google об «организации всей информации мира» выглядит немного смешным.
Google запустила бета-версию Cloud Spanner — СУБД поколения NewSQL / Хабр
Google открыла для всех бета-версию сервиса Cloud Spanner, глобально распределённой высокомасштабируемой мультиверсионной NewSQL БД с поддержкой распределённых транзакций.
Несколько лет Google использовала этот сервис исключительно для внутренних нужд. На нём работают ключевые системы Google, в том числе AdWords и Google Play. Spanner — эволюционное развитие NoSQL-предшественника Google Bigtable. Сам же c Spanner относят к семейству NewSQL-решений, то есть оно сочетает в себе преимущества реляционных и нереляционных СУБД. Это ACID-транзакции и SQL-синтаксис традиционных СУБД без ущерба для горизонтального масштабирования и высокой доступности, присущих NoSQL.
Исходя из опыта работы системы внутри компании, Google предлагает клиентам аптайм 99,9999% (шесть девяток, то есть максимум 31,5 секунды простоя в год), клиентские библиотеки с поддержкой Java, Go, Python, Node.js и др.
Принцип работы Spanner описан в научной работе James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, et al. Spanner: Google’s Globally-Distributed Database. Proceedings of OSDI, 2012. См. также описание Spanner на Хабре (2013).
Спустя несколько лет внутреннего использования Google приняла решение выкатить этот инфраструктурный сервис во всеобщее пользование. Оформить подписку предлагают корпоративным клиентам, которым нужно развернуть высоконадёжное отказоустойчивое облачное приложение. Раньше им приходилось выбирать между традиционными БД с гарантированной согласованностью транзакций и базами NoSQL с простым управлением, горизонтальным масштабированием и распределённым хранением данных. Сервис Cloud Spanner призван устранить эти противоречия, объединив все преимущества обеих технологий.
Cloud Spanner завершает линейку сервисов БД в облаке Google Cloud Platform (GCP), дополняя Cloud SQL, Cloud Datastore и Cloud Bigtable.
В Cloud Spanner нет теоретического предела на максимальный размер базы. В то же время этот сервис можно использовать и для маленьких проектов. Основное преимущество здесь — не только масштабируемость, но и возможность осуществлять глобальные транзакции одновременно во всех дата-центрах по всему миру.
Стоимость использования сервиса Cloud Spanner установлена в размере $0,90 за узел в час и $0,30 за один гигабайт занятого дискового пространства в месяц. Оплата за трафик внутри региона не взимается, между регионами США — $0,01 за гигабайт, между странами — от $0,08 до $0,12 за гигабайт, в Китай — от $0,20 до $0,23 за гигабайт, в Австралию — от $0,15 до $0,19 за гигабайт.
На Хабре публиковалась статья, почему Google пришлось отказаться от NTP (Network Time Protocol) и внедрить собственную систему проверки времени с GPS и атомными часами, более точную и надёжную. Её назвали TrueTime API. Внедрение такой системы необходимо было для обеспечения целостности базы данных Google Spanner.
Обеспечение цельности данных за счёт новой системы кодирования информации о времени транзакций — одна из ключевых инноваций Spanner (так указано в вышеупомянутой научной работе). Инженеры Google разработали многоуровневую систему проверки времени, записи временных интервалов транзакций и оценки уровня надёжности меток о времени. Это ключевой фактор, от которого зависит надёжность системы.
Вместо приёма данных с внешних часов, компания Google оборудовала дата-центры собственными атомными часами и ресиверами GPS. Это оборудование подключено к некоторым серверам, которые раздают метки времени всем остальным серверам в дата-центре. По факту, на каждой машине в дата-центре работает в фоновом режиме демон, который постоянно опрашивает сервер времени в своём дата-центре и аналогичные серверы времени в других дата-центрах. Таким образом, серверы Google во всём мире гарантированно работают на одном времени.
Через Google TrueTime API обеспечивается синхронизация данных, когда разные дата-центры пытаются одновременно записать в одну и ту же ячейку в БД. Интерфейс TrueTime API выдаёт значение интервала времени TTinterval: это время с заложенной погрешностью измерения и неопределённостью. Если интервалы TTinterval двух конкурентных транзакций не пересекаются, то можно с уверенностью сказать, какая из них произошла раньше. Если они пересекаются, это означает некоторую долю неопределённости.
Spanner совмещает свойства реляционных и нереляционных СУБД, не нарушая при этом CAP-теорему. как такое стало возможным — объясняет автор CAP-теоремы Эрик Брюер, ранее профессор Калифорнийского университета, а ныне вице-президент Google по инфраструктуре.
Бета-версию Cloud Spanner уже некоторое время используют избранные партнёры. Например, о своём опыте рассказал инженер компании Quizlet. Это интересный взгляд изнутри на интерфейс и протоколы Spanner, ведь кроме официальной документации у нас пока нет информации об этом уникальном сервисе.
Пошаговая инструкция создания SQL-сервера на Google Cloud Platform
Если кратко, то Google Cloud Platform (сокр. GCP) – это набор облачных служб, которые выполняются на той же самой инфраструктуре, что и продукты Google. Кроме инструментов для управления, также предоставляется ряд модульных облачных служб, таких как облачные вычисления, хранение данных, анализ данных и машинное обучение. В этой структуре крутятся такие гиганты, как PayPal, eBay, Spotify и Twitter.
Для регистрации нужно иметь банковскую карту или банковский счет. В первый год Google позволяет бесплатно пользоваться платформой в пределах суммарной стоимости услуг на 300 долларов. Но для того, чтобы ознакомиться с сервисом, вам достаточно прочитать наше руководство. В самой настройке нет ничего сложного.
Начнем с того, что создадим в GCP сервер PostgreSQL. Перед началом работы залогинимся в своей учетной записи GCP. Чтобы создать сервер баз данных PostgreSQL, выбираем SQL в боковой панели в разделе ХРАНЕНИЕ ДАННЫХ.
Раздел SQL в панели Google Cloud Platform
Для создания SQL-экземпляра щелкаем СОЗДАТЬ ЭКЗЕМПЛЯР.
Страница создания экземпляра
Выбираем нужный тип базу
данных – в нашем случае это PostgreSQL.
Выбор типа базы данных
Запустится инициализация Compute Engine API. Инициализация базы данных занимает некоторое время (у меня прошло две минуты). Заполним детали
конфигурации:
Страница создания экземпляра PostgreSQL
Нужно придумать название для экземпляра, установить пароль, указать регион, выбрать версию базы данных (по умолчанию сейчас PostgreSQL 11, в бете PostgreSQL 12).
Последним пунктом идут Варианты конфигурации – раскрываем пункт.
Кликаем по пункту Подключение. По умолчанию экземпляр не
может получить доступ из внешних сетей. Чтобы это исправить, разрешим вход по конкретному
IP-адресу или даем общий доступ. Нажимаем кнопку + Добавить ресурс: сеть.
Содержание пункта «Подключение» списка настроек конфигурации
Если указать адрес: 0.0.0.0/0, все IP-адреса смогут получить доступ к базе данных.
Настройка общедоступного IP-адреса
Нажимаем Готово. Для связи с
дополнительными функциями и API установим также флажок возле Частный IP-адрес и выберем связанную сеть (VPC-сеть или сеть по
умолчанию). Все эти настройки можно в дальнейшем корректировать.
В раздел Тип машины и хранилище можно настроить необходимые характеристики для тестов. Но для начала оставим все как есть.
Раздел настроек экземпляра «Тип машины и хранилище»
Если вы хотите только протестировать работу в системе, то в разделе Резервное копирование, восстановление и высокая доступность оставляем метку Одна зона.
Для производственных экземпляров логично выбрать флаг Высокая доступность, но это увеличит расходы по подписке.
В разделе флагов баз данных можно выбрать соответствующие параметры PostgreSQL:
Настройка флагов базы данных
GCP будет раз в несколько месяцев проводить техническое обслуживание. На это время работа сервиса будет ненадолго прерываться. В разделе Техническое обслуживание можно установить предпочтительные интервалы времени для перерыва на техническое обслуживание.
Для удобства упорядочения экземпляров в разделе ярлыки укажите Ключ и Значение:
Установка ключа и значения ярлыка
Наконец, для сохранения настроек и создания базы данных нажимаем кнопку Создать.
В результате мы перенесемся на страницу с таблицей экземпляров. Напротив идентификатора экземпляра базы данных некоторое время «покрутится» значок ожидания. Как только база данных будет создана, он сменится зеленым кружком с галочкой. На базу данных можно кликнуть и посмотреть ее описание.
Для получения доступа к
серверу PostgreSQL, требуется юзер. Для этого переходим в раздел Пользователи и создаем его:
Раздел «Пользователи»
Как можно видеть из других пунктов панели, отсюда же можно управлять базами данных, резервными копиями, репликами и следить за журналом операций.
Готово! Теперь у нас есть удаленная база данных, запись пользователя для работы с ней и облачная система управления.
Мы рассмотрели процесс
создания сервера PostgreSQL на площадке Google
Cloud Platform. Библиотека программиста надеется, что статья была полезна, и вы
сможете, опираясь на нее создать свой могучий сервер. Пишите, о чем еще вам было бы интересно прочитать в наших статьях.
Какую базу данных использует Google?
С BigTable
распределенная система хранения структурированных данных
Bigtable-распределенное хранилище
система (построенная Google) для управления структурированными данными
это очень предназначен для масштабирования
большой размер: петабайты данных через
тысячи обычных серверов.многие проекты в Google store данных в
Bigtable, включая веб-индексацию,
Google Планета Земля и Google финансы.
Эти приложения очень
различные требования к Bigtable, оба в
условия размера данных (от url до web
страницы для спутниковых снимков) и
требования к задержке (из бэкэнда
основная обработка данных в реальном времени
сервировочный.)несмотря на эти разнообразные
требования, Bigtable имеет успешно
обеспечено гибкое, высокопроизводительное
решение для всех этих Google
товары.
некоторые функции
- быстрый и весьма широкомасштабный СУБД
- разреженный, распределенной многомерной сортированную карту, обмен характеристики построчным и столбец-ориентированных баз данных.
- предназначен для масштабирования в диапазоне петабайт
- он работает через сотни или тысячи машин
- легко добавить больше машин в систему и автоматически начать использовать эти ресурсы без какой-либо реконфигурации
- каждая таблица имеет несколько измерений (одно из которых это поле для времени, позволяющее управление версиями)
- таблицы оптимизированы для GFS (файловой системы Google) путем разделения на несколько планшетов — сегментов таблицы, как разделить вдоль строки, выбранной таким образом, что планшет будет ~200 мегабайт в размере.
архитектура
BigTable не является реляционной базой данных. Он не поддерживает соединения и не поддерживает богатые SQL-подобные запросы. Каждая таблица представляет собой многомерную разреженную карту. Таблицы состоят из строки и столбцы, и каждая ячейка имеет отметку времени. Может быть несколько версий ячейки с различными временными метками. Метка времени позволяет выполнять такие операции, как» выбор «n» версий этой веб-страницы » или » удаление ячеек, которые старше определенной даты/времени.»
чтобы управлять огромными таблицами, Bigtable разбивает таблицы на границах строк и сохраняет их в виде планшетов. Планшет около 200 МБ, и каждая машина сохраняет около 100 планшетов. Эта установка позволяет планшетам от одиночного таблица должна быть распределена между многими серверами. Оно также учитывает мелкозернистую балансировку нагрузки. Если одна таблица получает много запросов, она может пролить другие планшеты или переместить занятую таблицу на другую машину, которая не так занята. Кроме того, если машина выходит из строя, планшет может быть распространен по многим другим серверам, так что влияние производительности на любой машине минимально.
таблицы хранятся как неизменяемые SSTables и хвост журналов (один журнал на машину). Когда машина бежит из системы память, он сжимает некоторые таблетки, используя собственные методы сжатия Google (BMDiff и Zippy). Незначительные уплотнения включают только несколько таблеток, в то время как основные уплотнения включают всю систему таблиц и восстанавливают пространство на жестком диске.
местоположения таблеток Bigtable хранятся в ячейках. Поиск любого конкретного планшета обрабатывается трехуровневой системой. Клиенты получают точку в таблице META0, из которой есть только одна. Таблица META0 отслеживает многие таблетки META1 которые содержат местоположения таблеток, которые ищут. И META0, и META1 активно используют предварительную выборку и кэширование для минимизации узких мест в системе.
реализация
BigTable построен на Файловая Система Google (ГФС), который используется в качестве резервного хранилища для файлов журналов и данных. GFS обеспечивает надежное хранилище для SSTables, проприетарного формата файлов Google, используемого для сохранения табличных данных.
другое служба, которая BigTable интенсивно использует is Чабби, высок-доступное, надежное распределенное обслуживание замка. Chubby позволяет клиентам взять блокировку, возможно, связывая ее с некоторыми метаданными, которые он может обновить, отправив сообщения keep alive обратно Chubby. Блокировки хранятся в иерархической структуре именования, подобной файловой системе.
есть три основных типы серверов интерес к системе Bigtable:
- мастер-сервера: назначение таблетки на планшетных серверах, отслеживает, где таблетки расположены и перераспределяет задачи по мере необходимости.
- планшетные серверы: обрабатывать запросы на чтение / запись для планшетов и сплит — планшетов, когда они превышают пределы размера (обычно 100MB-200MB). Если сервер планшета терпит неудачу, то 100 серверов планшета каждый приемистость 1 новый планшет и система берет.
- серверы блокировки: экземпляры службы распределенной блокировки Chubby. Множество действий в BigTable требуют приобретения блокировок включая открытие планшетов для записи, обеспечение того, чтобы не было более одного активного мастера за раз, и проверку контроля доступа.
пример из исследовательской работы Google:
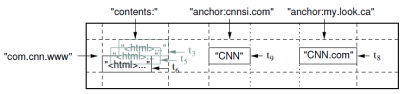
фрагмент таблицы примеров, которая
хранит веб-страницы. Имя строки-a
отменено URL-адресом. Столбец содержание
семья содержит содержание страницы, и
семейство столбцов привязки содержит
текст якоря ссылки
страница. На домашнюю страницу CNN ссылается
и The Sports Illustrated, и the
MY-look home pages, так что строка
содержит столбцы с именем
anchor:cnnsi.comи
anchor:my.look.ca. Каждая Якорная ячейка
имеет одной из версий; столбца содержание
имеет три версии, в метки
t3,t5иt6.
API
типичные операции для BigTable-это создание и удаление таблиц и семейств столбцов, запись данных и удаление столбцов из строки. BigTable предоставляет эти функции разработчикам приложений в API. Транзакции поддерживаются на уровне строк, но не на нескольких ключах строк.
здесь ссылка на PDF исследовательской работы.
и здесь вы можете найти видео, показывающее Джеффа Дина Google в лекции в Университете Вашингтона, обсуждаем Bigtable система хранения контента, используемая в бэкэнде Google.
Синхронизация Google Sheets с базой данных Firebase в реальном времени
Часто при тестировании дизайна полезно создать прототип с реалистичными данными. Пользователи склонны давать лучшие отзывы, когда содержание правдоподобно, а не заполнено текстом «lorem ipsum». В этом коротком руководстве мы покажем, как синхронизировать электронную таблицу Google Sheets с базой данных Firebase Realtime и использовать ее в своем высокоточном прототипе в качестве источника данных.
В целом, использование базы данных в реальном времени проще и быстрее, чем непосредственное использование Sheets API. Уровень Firebase также поддерживает до 100 000 одновременных подключений против 400 с использованием Sheets API. После синхронизации электронной таблицы вы можете легко использовать любой стек для доступа к вашим данным. Это также дает заинтересованным сторонам и исследователям простой способ манипулировать данными, видеть изменения в реальном времени и очень быстро тестировать множество вариантов.
Шаг 1: Создайте свой проект Firebase
Если вы еще этого не сделали, зарегистрируйтесь в Firebase, используя бесплатную подписку, а затем создайте свой проект.
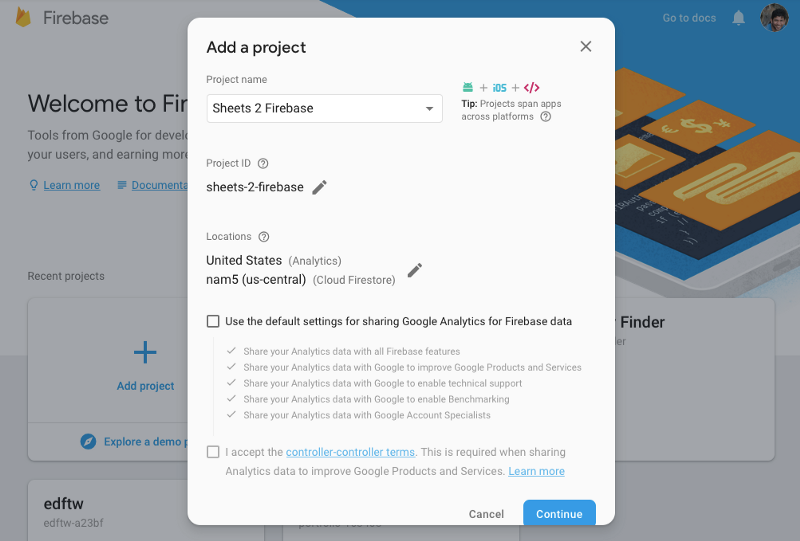
Шаг 2: Создайте Realtime базу данных
Перейдите в Develop -> Database и нажмите кнопку «Create database».

Убедитесь, что вы изменили свои права на чтение и запись на «true» и нажмите «Опубликовать».

Скопируйте URL базы данных. Нам он понадобится позже.

URL вашей базы данных будет уникальным для вашего проекта.
Шаг 3. Создайте электронную таблицу и заполните ее, используя следующий формат
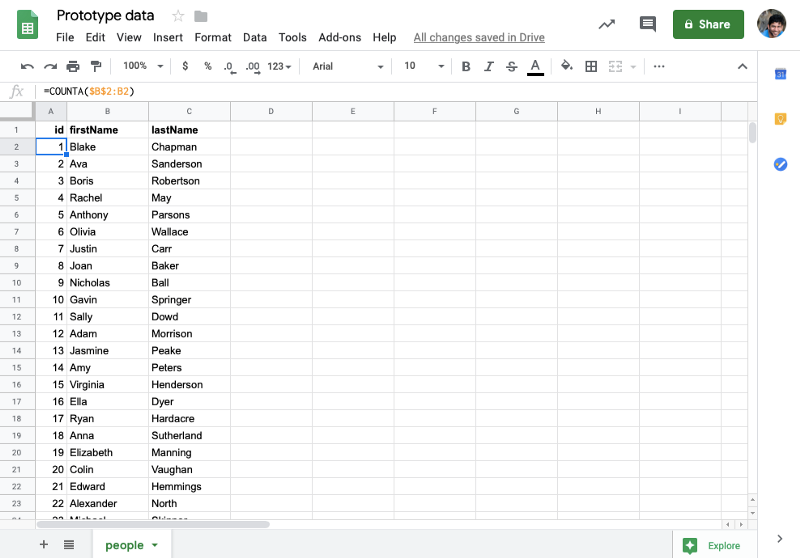
Первый ряд содержит ваши ключи. Первый ключ должен быть установлен в «id», и каждая строка должна быть помечена соответствующим номером, начиная с «1».
Вы можете добавить столько строк или столбцов, сколько вам нужно.
Шаг 4. Создайте свой проект Apps Script
В меню выберите Tools -> Script editor.
Вы попадете в редактор кода со следующим открытым файлом: Code.gs.
Замените содержимое этим фрагментом.
Найдите этот код в верхней части файла:

Замените параметр «spreadsheetID» своим собственным. Идентификатор — это выделенная жирным шрифтом часть полного URL-адреса электронной таблицы например:
https://docs.google.com/spreadsheets/d/spreadsheetID/edit#gid=0)
Замените заполнитель «firebaseUrl» на URL вашей базы данных из шага 2.
В вашем меню выберите View -> Show manifest file, который добавит файл с именем appsscript.json.
Это добавит файл appsscript.json в ваш проект. Замените содержимое следующим фрагментом.
Шаг 5: Запустите синхронизацию
В меню выберите Run -> Run function -> initialize. Вы увидите приглашение просмотреть и принять разрешения. Это позволяет проекту App Script получить доступ к электронной таблице и загрузить данные в Firebase. Нажмите Review Permissions, а затем нажмите Allow.
Превосходно! Ваша база данных Firebase Realtime теперь заполнена данными из вашей электронной таблицы! Любые дальнейшие изменения будут синхронизироваться без проблем, и вы даже сможете поделиться своей таблицей с другими людьми.

Советы и хитрости
Добавить безопасности
Если вы чувствуете себя модно, вы можете добавить немного больше безопасности в базу данных Firebase. Перейдите в Firebase Console -> Database и измените ваши правила на следующие.
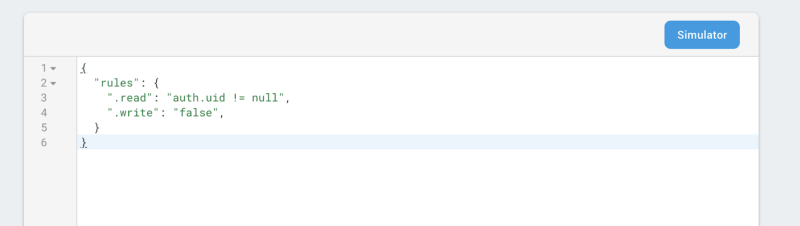
Вы должны будете реализовать Аутентификацию Firebase на своем прототипе, чтобы ваши пользователи могли читать данные. Установка метода записи в false означает, что только ваша электронная таблица может записывать в базу данных.
Генерация массива
В списке, если ваш идентификатор начинается с 0 и увеличивается на 1, сценарий сгенерирует массив вместо пар ключ-значение.
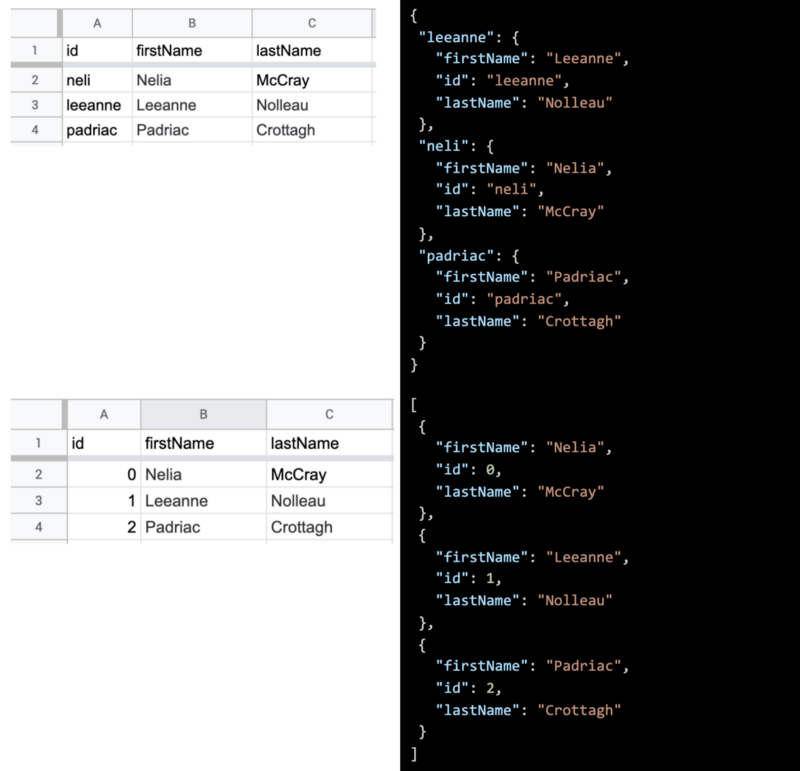
Вложенные данные
При преобразовании таблицы в JSON можно выполнить только один уровень вложенности. Но что, если вам нужны вложенные данные? Приведенный выше скрипт имеет специальную функцию, которая позволяет создавать вложенный объект. Просто назовите заголовок столбца с путем к ключу соединения объектов, используя двойное подчеркивание __. Если вы хотите поместить улицу под адресом, вы можете просто сказать «address__street», это означает, что у вас не может быть столбца с именем только адрес в вашем списке.

Это создаст объект, подобный представленному ниже, и вы также можете вкладывать его на любом уровне.

Попробуйте! Вы не будете разочарованы…
Мы думаем, что техника, которую мы описали, поможет вашим прототипам с реалистичными данными. Наша цель — помочь сократить количество времени, которое вы тратите на ввод данных, и высвободить больше времени для экспериментов и повторений!
Перевод статьи: Sync Google Sheets to a Firebase Realtime Database
Источник: medium.com
Как выгружать данные с вложенной структурой из Google BigQuery на примере пользовательских параметров Google Analytics
Google BigQuery — популярная облачная база данных, которой пользуются компании по всему миру. Она особенно удобна для работы с “сырыми” данными Google Analytics: в GA 360 интеграция с BigQuery настраивается в несколько кликов, а для бесплатной версии существуют сторонние скрипты и модули.
В “сырых” данных Google Analytics каждая запись (строка) соответствует сеансу. Внутри такой записи находятся вложенные поля, которые соответствуют хитам сеанса:
Часто подобная вложенная структура данных сбивает с толку пользователей, которые не понимают как с ней работать и выгружать такие данные.
На примере пользовательских параметров Google Analytics я постараюсь “на пальцах” объяснить, как хранятся вложенные данные в Google BigQuery и как их можно выгружать.
Приведенные коды запросов рабочие, их можно использовать в решении задач, подставляя свои названия таблиц и нужные номера индексов Custom Dimensions.
• Выгрузка строк
• Выгрузка с сохранением структуры вложенности
• Пример замены значений пользовательских параметров
Основы
BigQuery поддерживает 2 диалекта SQL: Legacy и Standard. Google рекомендует использовать более новый SQL Standard, на нем мы и будем писать запросы для выгрузки.
Все, кто хоть немного работал с SQL, знают стандартную конструкцию запроса:
SELECT
*Что хотим выбрать*
FROM
*Из какой таблицы*
WHERE
*Условия фильтрации*
Такая конструкция работает, если структура таблицы простая, без других, вложенных в ячейки полей:
Мы же рассматриваем таблицы с вложенными полями. Структура такой таблицы (например, пользовательские параметры Google Analytics):Пользовательские параметры GA в BQ
В Google BigQuery у такой таблицы будут следующие названия столбцов (разделитель «.» показывает структуру вложенности):
Так как же нам выгрузить данные из вложенных полей?
Выгрузка строк
Вернемся к таблице с примером пользовательских параметров GA в BQ.
Столбцы customDimensions.index и customDimensions.value — это индексы и значения сессионных и пользовательских Custom Dimensions.
Столбцы hits.customDimensions.index и hits.customDimensions.value — индексы и значения хитовых Custom Dimensions.
В Google BigQuery есть еще один уровень действия пользовательских параметров — товар. Названия и значения товарных Custom Dimensions в Google BigQuery находятся в столбцах hits.product.customDimensions.index и hits.product.customDimensions.value. Они выгружаются по аналогии с хитовыми пользовательскими параметрами, необходимо лишь учесть еще один уровень вложенности.
Пользовательские параметры сессионного и пользовательского уровня
Как поступить, если нам необходимо для каждой даты выгрузить значения сессионных (пользовательских) Custom Dimensions без сохранения вложенной структуры (то есть построчно)?
Для ответа на вопрос давайте еще раз внимательнее посмотрим на таблицу с пользовательскими параметрами GA в BQ.
В ней видно, что значения ячеек столбца customDimensions представляют из себя еще одну таблицу:
Достаточно сделать подзапрос к этой таблице в основном запросе:
SELECT
-- выбираем даты
date,
-- выбираем значения столбца value
(SELECT value
-- из таблицы customDimensions, которая вложена в таблицу t
FROM t.customDimensions
-- фильтр по нужному индексу пользовательского параметра
WHERE index = 1) AS customDimensions1
FROM
-- называем основную таблицу t для обращения к ней
`project.dataset.tablename` AS t На выходе получаем таблицу:
Если нам нужно добавить столбец со значением другого пользовательского параметра — делаем еще один подзапрос:
SELECT
date,
(SELECT value FROM t.customDimensions WHERE index = 1) AS customDimensions1,
-- еще один подзапрос к таблице customDimensions
(SELECT value FROM t.customDimensions WHERE index = 2) AS customDimensions2
FROM
`project.dataset.tablename` AS tПолучаем следующее:
Пользовательские параметры хитового уровня
Хитовые пользовательские параметры выгружаются аналогично сессионным (пользовательским), за исключением того, что подзапрос нужно делать к вложенной таблице hits. Другими словами, значения ячеек столбца hits в таблице “сырых” данных Google Analytics представляет из себя вложенную таблицу, в которую вложена таблица customDimensions:
Запрос для выгрузки построчно хитовых пользовательских параметров будет такой:
SELECT
-- выбираем даты
date,
-- выбираем значения столбца value
(SELECT value
-- из таблицы customDimensions, которая вложена в таблицу h
FROM h.customDimensions
-- фильтр по нужному индексу пользовательского параметра
WHERE index = 3) AS customDimensions3
FROM
-- называем основную таблицу t для обращения к ней
`project.dataset.tablename` AS t,
-- вложенную таблицу t.hits называем h для обращения к ней
t.hits AS h Результатом выполнения запроса станет таблица:
Можно выгрузить несколько хитовых пользовательских параметров и добавить параметр hitNumber (порядковый номер хита в сессии):
SELECT
date,
h.hitNumber AS hitNumber,
(SELECT value FROM h.customDimensions WHERE index = 3) AS customDimensions3,
-- делаем еще один подзапрос к вложенной таблице h.customDimensions
(SELECT value FROM h.customDimensions WHERE index = 4) AS customDimensions4
FROM
`project.dataset.tablename` AS t,
t.hits AS hПолучим таблицу:
Сессионные (пользовательские) + хитовые пользовательские параметры
Если в одном запросе мы хотим выгрузить сессионные и хитовые пользовательские параметры, необходимо всего лишь сделать нужные подзапросы к основной и к вложенным таблицам:
SELECT
date,
h.hitNumber AS hitNumber,
-- выгружаем сессионные пользовательские параметры
(SELECT value FROM t.customDimensions WHERE index=1) AS customDimensions1,
(SELECT value FROM t.customDimensions WHERE index=2) AS customDimensions2,
-- выгружаем хитовые пользовательские параметры
(SELECT value FROM h.customDimensions WHERE index=3) AS customDimensions3,
(SELECT value FROM h.customDimensions WHERE index=4) AS customDimensions4
FROM
`project.dataset.tablename` AS t,
t.hits AS hТаблица, которая будет получена в результате выполнения запроса:
Выгрузка с сохранением структуры вложенности
Такая выгрузка может понадобиться при замене значений какого-либо пользовательского параметра в Google BigQuery.
Пример
В Google Analytics в сессионный пользовательский параметр с индексом 12 и в хитовой пользовательский параметр с индексом 25 для пользователей из России передается название страны в полном формате: RUSSIA. Необходимо поменять формат страны на сокращенный: RUS.
Для этого необходимо заменить нужные значения пользовательского параметра со страной пользователя за всю историю данных в Google BigQuery.
Порядок решения задачи:
- Выгружаем все данные с сохранением структуры вложенности
- Заменяем значение пользовательского параметра со страной
- Перезаписываем таблицу
Для выгрузки данных с сохранением структуры вложенности необходимо использовать функцию ARRAY и конструкцию SELECT AS STRUCT. Разберемся, что это такое.
Синтаксис функции ARRAY следующий:
ARRAY(*подзапрос*)Она возвращает массив элементов.
Сравнение массива с построчной записью:
Слева — массив, справа — построчная запись
Если мы хотим сохранить вложенную структуру и выгрузить массив с несколькими колонками, необходимо использовать ARRAY(SELECT AS STRUCT …):
Массив с вложенной структурой
Пользовательские параметры сессионного и пользовательского уровня
Для выгрузки с сохранением структуры сессионных (пользовательских) Custom Dimensions используем запрос:
SELECT
date,
-- используем ARRAY(SELECT AS STRUCT...) для сохранения вложенности
ARRAY(SELECT AS STRUCT index, value FROM t.customDimensions) AS customDimensions
FROM
`project.dataset.tablename` AS tВ результате его выполнения получается таблица, в которой сохранена структура вложенности “сырых” данных Google Analytics:
Пользовательские параметры хитового уровня
Для выгрузки значений хитовых пользовательских параметров из Google BigQuery с сохранением структуры вложенности важно учесть, что таблица customDimensions вложена в таблицу hits. Другими словами, необходимо 2 раза сделать подзапрос ARRAY(SELECT AS STRUCT…): сначала к вложенной таблице hits, потом к вложенной в нее таблице customDimensions:
SELECT
date,
-- подзапрос к таблице t.hits
ARRAY(SELECT AS STRUCT hitNumber,
-- подзапрос к таблице h.customDimensions
ARRAY(SELECT AS STRUCT index, value FROM h.customDimensions) AS customDimensions
FROM t.hits AS h ) AS hits
FROM
`project.dataset.tablename` AS tРезультатом такого запроса будет таблица:
Сессионные (пользовательские) + хитовые пользовательские параметры
Как и при построчной выгрузке, нам необходимо объединить в одном запросе подзапросы ARRAY(SELECT AS STRUCT…) к нужным вложенным таблицам:
SELECT
date,
-- сессионные (пользовательские) Custom Dimensions
ARRAY(SELECT AS STRUCT index, value FROM t.customDimensions ) AS customDimensions,
-- хитовые Custom Dimensions
ARRAY(SELECT AS STRUCT hitNumber,
ARRAY(SELECT AS STRUCT index, value FROM h.customDimensions ) AS customDimensions
FROM
t.hits AS h) AS hits
FROM
`project.dataset.tablename` AS tЧто получается в результате:
Пример замены значений пользовательских параметров
Вернемся к нашему примеру.
В предыдущем разделе мы получили запрос для выгрузки сессионных (пользовательских) и хитовых пользовательских параметров Google Analytics с сохранением структуры вложенности.
Дополним этот запрос конструкциями SELECT *REPLACE для выгрузки с заменой и CASE для обновления значений нужных пользовательских параметров:
-- выгружаем всё с заменой колонок t.customDimensions и t.hits
SELECT *REPLACE(
-- сессионные (пользовательские) Custom Dimensions
ARRAY(SELECT AS STRUCT index,
-- меняем значение нужного пользовательского параметра
CASE WHEN index=12 AND value='RUSSIA' THEN 'RUS' ELSE value END AS value
FROM t.customDimensions) AS customDimensions,
-- хитовые Custom Dimensions
-- выгружаем колонку t.hits с заменой ее вложенных полей h.customDimensions
ARRAY(SELECT AS STRUCT *REPLACE(
ARRAY(SELECT AS STRUCT index,
-- меняем значение нужного пользовательского параметра
CASE WHEN index=25 AND value='RUSSIA' THEN 'RUS' ELSE value END AS value
FROM h.customDimensions) AS customDimensions)
FROM t.hits AS h) AS hits)
FROM
`project.dataset.tablename` AS tВ результате выполнения данного запроса мы получим оригинальную таблицу с “сырыми” данными из Google Analytics. У неё полностью сохранится оригинальная структура вложенности, но значения нужных пользовательских параметров изменятся на новые.
Тема работы с вложенной структурой данных в Google BigQuery не относится к легким.
Надеюсь, у меня получилось внести ясность в этот вопрос. Но, напомню, лучший способ научиться делать что-то — это больше практиковаться.
Импорт данных из Google BigQuery l Справка Zoho Analytics
Если у вас есть данные, хранящиеся в базе данных Google BigQuery Cloud, вы можете легко импортировать их в Zoho Analytics для составления отчетов и анализа. Вы также можете настроить расписания для периодического извлечения последних данных из базы данных Google BigQuery.
- Как импортировать данные из базы данных Google BigQuery?
- Как отредактировать настройку?
- Сколько времени нужно, чтобы данные были импортированы в Zoho Analytics?
- Могу ли я импортировать данные из представлений, созданных в Google BigQuery (кроме таблиц), в Zoho Analytics?
- Будут ли внешние ключи, определенные между моими таблицами в базе данных Google BigQuery, быть связаны в Zoho Analytics?
- Могу ли я изменить тип данных столбцов в Zoho Analytics?
- Я синхронизировал данные из базы данных в таблицу.Могу ли я изменить источник данных этой таблицы?
- Могу ли я импортировать данные из моей базы данных Google BigQuery в существующую рабочую область Zoho Analytics?
- Могу ли я мгновенно синхронизировать данные из моей облачной базы данных?
- Как удалить программу установки?
1. Как импортировать данные из базы данных Google BigQuery?
2. Как мне отредактировать настройку?
3. Сколько времени нужно, чтобы данные были импортированы в Zoho Analytics?
После настройки вам, возможно, придется подождать, пока начнется первоначальная выборка.Это зависит от объема данных, которые нужно импортировать в Zoho Analytics, а также от времени ответа вашего сервера Google BigQuery. После завершения импорта вы получите уведомление по электронной почте. Обратите внимание, что если вы получите доступ к рабочей области до первоначальной выборки, она не отобразит никаких данных.
4. Могу ли я импортировать данные из представлений, созданных в Google BigQuery (кроме таблиц), в Zoho Analytics?
Да, вы можете импортировать данные как из представлений , так и из таблиц в Zoho Analytics.
5. Будут ли внешние ключи, определенные между моими таблицами в базе данных Google BigQuery, быть связаны в Zoho Analytics?
При импорте нескольких таблиц внешние ключи, определенные между таблицами в базе данных Google BigQuery, будут связаны в Zoho Analytics. Внешние ключи будут созданы в виде столбцов поиска в Zoho Analytics.
Если вы импортируете данные из одной таблицы за раз (выбирая опцию одной таблицы), то внешние ключи не будут определены. Однако вы можете вручную связать таблицы в Zoho Analytics, используя функцию столбца поиска.Щелкните здесь, чтобы узнать о функции столбца поиска.
6. Могу ли я изменить тип данных столбцов, импортированных в Zoho Analytics?
Да, вы можете изменить тип данных столбцов, импортированных в Zoho Analytics. Однако необходимо, чтобы тип данных вашего столбца был совместим с типом данных столбца в вашей базе данных Google BigQuery для успешной синхронизации данных. Всегда рекомендуется изменять тип данных как в базе данных Google BigQuery, так и в рабочем пространстве Zoho Analytics.
7. Я синхронизировал данные из базы данных в таблицу. Могу ли я изменить источник данных этой таблицы?
Да, вы можете изменить источник данных таблицы, в которую была синхронизирована база данных Google BigQuery.
Выполните следующие шаги для импорта, если источник доступен в той же базе данных Google BigQuery, которая импортируется в таблицу.
- Откройте рабочее пространство .
- Щелкните Импортировать данные > Импортировать в эту таблицу .
- Откроется вкладка Выберите данные для импорта мастера импорта.
- Можно выбрать импорт из другой таблицы с помощью параметра Выбрать таблицу или импорт с помощью пользовательского запроса .
Выполните следующие шаги для импорта, если источник доступен в другой локальной базе данных.
- Откройте рабочую область.
- Щелкните Источник данных на левой панели.
- Будут перечислены все источники данных для этой рабочей области.Щелкните источник данных, который хотите изменить.
- Откроется страница источника данных. Щелкните Изменить соединение .
- В открывшемся диалоговом окне Cloud Database — Edit Connection измените источник данных. Вы также можете изменить Databridge, который получает данные.
8. Могу ли я импортировать данные из моей базы данных Google BigQuery в существующее рабочее пространство Zoho Analytics?
Да. Выполните следующие шаги, чтобы импортировать данные в существующее рабочее пространство:
- Откройте рабочее пространство, в которое вы хотите импортировать данные.
- Перейдите по Создать > Импортировать данные .
- Щелкните опцию Cloud Databases .
Настройка импорта будет аналогична шагам, описанным в этой презентации.
9. Могу ли я мгновенно синхронизировать данные из моей облачной базы данных?
Да, при необходимости вы можете мгновенно синхронизировать данные из облачной базы данных.
Для мгновенной синхронизации данных:
- Войдите в свою учетную запись Zoho Analytics.
- Откройте соответствующее рабочее пространство.
- На домашней странице щелкните вкладку Источник данных . Откроется страница источника данных.
- Щелкните ссылку Синхронизировать сейчас .
Примечание : Этот параметр можно использовать максимум пять раз в день.
10. Как удалить программу установки?
Чтобы удалить настройку,
- Войдите в свою учетную запись Zoho Analytics.
- Откройте соответствующее рабочее пространство.
- На домашней странице щелкните вкладку Источник данных .Откроется страница источника данных.
- Щелкните значок Настройки .
- В открывшемся раскрывающемся меню выберите Удалить источник данных .
Обратите внимание, что соединение с источником данных будет удалено, но таблицы и данные останутся в рабочей области. Поскольку подключенный источник данных удаляется, дальнейшая синхронизация выполняться не будет.
.
Google Ngram Viewer
Книги Ngram Viewer
доля
Загрузить необработанные данные
доля
код
Вставить диаграмму

facebook

щебет
Вставить диаграмму
content_copy
копия
Теги части речи
cook_VERB, _DET_ Президент
Wildcards
Король *, лучший * _NOUN
интонации
потряс_INF drive_VERB_INF
Арифметические композиции
(цвет / (цвет + цвет))
Выбор корпуса
Хочу: eng_2019
близко
Просмотреть все варианты
1800
—
2019
arrow_drop_down
Выберите годы
в
Отмена
Подать заявление
Английский (2019)
arrow_drop_down
Выбрать корпус
checkEnglish3019
checkAmerican English3019 checkBritish English3019 checkEnglish Fiction2019 checkChinese (упрощенный) 2019 checkFrench3019 checkGerman2019 checkHebrew2019 checkItalian2019 checkRussian2019 checkSpanish3019 checkAmerican English3012 checkBritish English3012 checkChinese (упрощенный) 2012 checkEnglish3012 checkEnglish Fiction2012 checkFrench3012 checkGerman2012 checkHebrew2012 checkИтальянский2012 checkРусский2012 checkИспанский3012 checkАмериканский английский3009 checkБританский английский3009 checkКитайский (упрощенный) 2009 checkEnglish3009 checkEnglish Fiction2009 checkEnglish One Million check2009