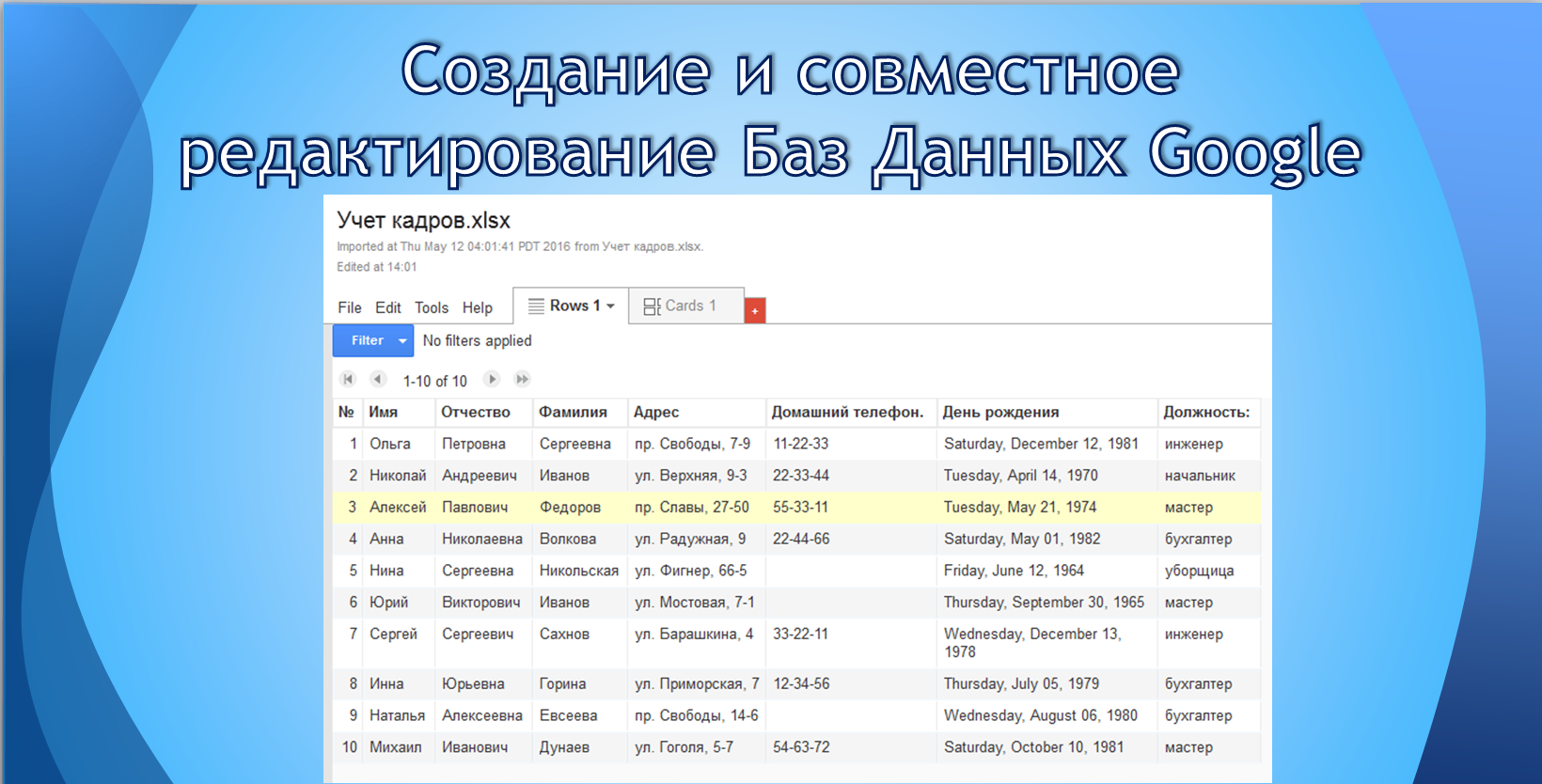
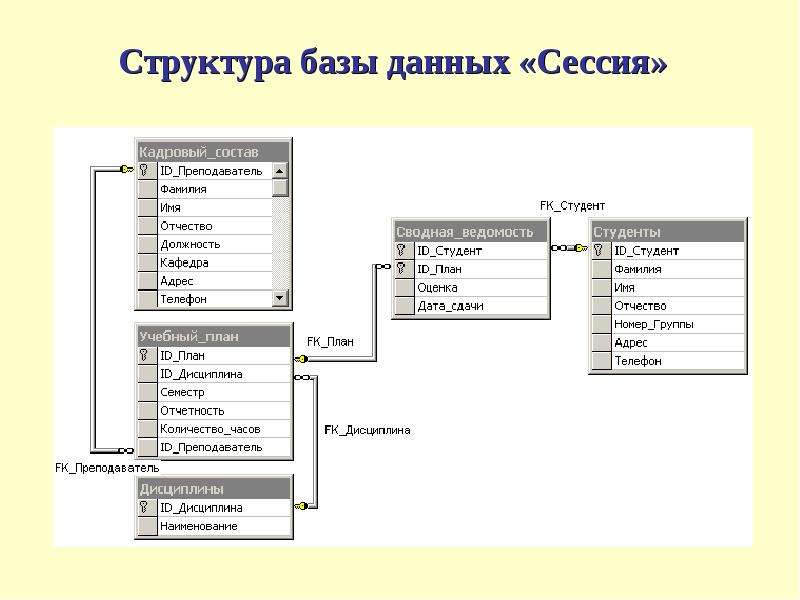
Google база данных: Об ответственном использовании Google Таблиц в роли баз данных
Google spreadsheet как база данных для веб-приложений
Кто-нибудь знает, могу ли я использовать электронную таблицу Google для хранения результатов моей пользовательской формы HTML?
Я знаю, что Google spreadsheet позволяет создавать форму на самом домене Google, но можно ли использовать Google spreadsheet в качестве базы данных для других веб-приложений?
google-sheets
Поделиться
Источник
Pvt
18 октября 2010 в 05:54
2 ответа
- Google Oauth для установленных приложений против Oauth для веб-приложений
Так что мне трудно кое-что понять… Если вы делаете Oauth для веб-приложений, вы регистрируете свой сайт с обратным вызовом URL и получаете уникальный секретный ключ потребителя. Но как только вы получили токен Oauth для веб-приложений, вам не нужно генерировать Oauth вызовов на сервер google из.
 ..
.. - Google Spreadsheet jdbc connector
Мне нужно использовать Google Spreadsheet с сервером JasperReports, для этого мне нужен разъем JDBC для Google Spreadsheet. Я нашел этот проект , но он не обновляется с 2010 года. Мне было интересно, может быть, Google Drive имеет API для такого рода соединений, или кто-то из вас знает другой…
 ..
..Поделиться
casablanca
18 октября 2010 в 05:56
1
Зачем вы хотите это сделать ? Как вы думаете, каково время отклика бэкенда Google, когда приложение получает много запросов ? Каков максимальный разрешенный запрос ?
Поделиться
Ankur Gupta
18 октября 2010 в 05:59
Похожие вопросы:
Аутентификация и использование электронной таблицы Google в качестве базы данных для веб-приложения
Кажется, вокруг этой темы есть много вопросов, но ни один из них, похоже, не отвечает на мой вопрос. У меня есть простой веб-сайт с формой регистрации, и когда пользователи вводят свой email, я хочу…
У меня есть простой веб-сайт с формой регистрации, и когда пользователи вводят свой email, я хочу…
Какой Язык Google Использует Для Веб-Приложений
Я хочу знать одну вещь, какой язык Google использует для разработки веб-приложений, потому что я обсуждал это со своими друзьями, и они говорят, что Google использует Python для веб-приложений, но…
Рекомендации по настройке центральной БД с основными таблицами для веб-приложений
Я начинаю писать все больше и больше веб-приложений для работы. Многие из этих веб-приложений должны хранить одни и те же типы данных, такие как местоположение. Я подумал, что, возможно, лучше…
Google Oauth для установленных приложений против Oauth для веб-приложений
Так что мне трудно кое-что понять… Если вы делаете Oauth для веб-приложений, вы регистрируете свой сайт с обратным вызовом URL и получаете уникальный секретный ключ потребителя. Но как только вы…
Google Spreadsheet jdbc connector
Мне нужно использовать Google Spreadsheet с сервером JasperReports, для этого мне нужен разъем JDBC для Google Spreadsheet.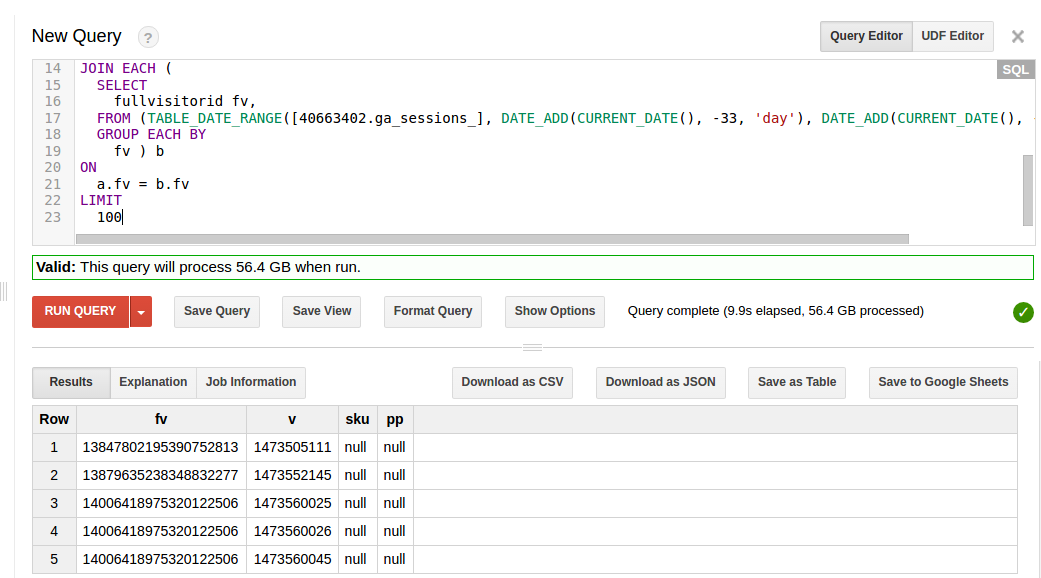 Я нашел этот проект , но он не обновляется с 2010 года. Мне было…
Я нашел этот проект , но он не обновляется с 2010 года. Мне было…
php-google-spreadsheet-client getByTitle возвращает null
Я использую эту библиотеку https://github.com/asimlqt/php-google-spreadsheet-client для взаимодействия с электронной таблицей Google api. Используя приведенные примеры в значительной степени как…
Скачать Google spreadsheet использовать google spreadsheet api
У меня есть рабочий пример, который я получил здесь. https: / / developers.google.com/google-apps/spreadsheets/ мне нужно загрузить некоторые файлы из Google doc пользователя. import…
Интеграция аутентификации входа в систему Google+ для веб-приложений
Мне нужно интегрировать Google+ в мои веб-приложения, чтобы пользователи могли входить в систему со своими учетными данными google. Я не забочусь о других API-х (получение данных для использования с…
Архитектурный веб-сервер, сервер приложений и сервер БД
Насколько мне известно, эта архитектура Веб-сервер -> сервер приложений -> сервер БД это лучше, чем Веб-сервер — > сервер БД Но я не знаю причин. Кто-нибудь знает? Мой сервер приложений — это сервер…
Кто-нибудь знает? Мой сервер приложений — это сервер…
Как несколько разработчиков могут совместно поддерживать решение, основанное на Google Apps Script, Google Forms и Google spreadsheet?
Используя общий аккаунт Google, несколько разработчиков в нашей компании разработали решение на основе Google Apps Script, Google Forms & Google spreadsheet. Мы настроили много временных…
Какую базу данных использует Google?
Большой стол
Распределенная система хранения структурированных данных
Bigtable — это распределенная система хранения (созданная Google) для управления структурированными данными, которая рассчитана на масштабирование до очень большого размера: петабайты данных на тысячах обычных серверов.
Многие проекты в Google хранят данные в Bigtable, включая веб-индексацию, Google Earth и Google Finance. Эти приложения предъявляют к Bigtable очень разные требования, как с точки зрения размера данных (от URL-адресов к веб-страницам до спутниковых изображений), так и требований к задержке (от массовой обработки на сервере до обработки данных в реальном времени).
Несмотря на эти разнообразные требования, Bigtable успешно предоставил гибкое, высокопроизводительное решение для всех этих продуктов Google.

Некоторые особенности
- быстрая и чрезвычайно масштабная СУБД
- разреженная, распределенная многомерная отсортированная карта, разделяющая характеристики как ориентированных на строки, так и ориентированных на столбцы баз данных.
- предназначен для масштабирования в петабайтный диапазон
- он работает на сотнях или тысячах машин
- легко добавить больше компьютеров в систему и автоматически начать использовать эти ресурсы без какой-либо реконфигурации
- каждая таблица имеет несколько измерений (одно из которых является полем для времени, позволяющим управлять версиями)
- Таблицы оптимизированы для GFS (файловой системы Google), поскольку они разбиты на несколько планшетов — сегменты таблицы разделены по выбранной строке таким образом, что размер планшета составит ~ 200 мегабайт.

Архитектура
BigTable не является реляционной базой данных. Он не поддерживает объединения и не поддерживает расширенные SQL-подобные запросы. Каждая таблица представляет собой многомерную разреженную карту. Таблицы состоят из строк и столбцов, и каждая ячейка имеет метку времени. Может быть несколько версий ячейки с разными отметками времени. Отметка времени позволяет выполнять такие операции, как «выбрать ‘n’ версии этой веб-страницы» или «удалить ячейки, которые старше определенной даты / времени».
Чтобы управлять огромными таблицами, Bigtable разделяет таблицы по границам строк и сохраняет их как планшеты. Планшет занимает около 200 МБ, а каждая машина экономит около 100 планшетов. Эта настройка позволяет распределять планшеты из одной таблицы между многими серверами. Это также учитывает мелкозернистую балансировку нагрузки. Если одна таблица получает много запросов, она может сбросить другие планшеты или перенести занятую таблицу на другой компьютер, который не так занят. Кроме того, если компьютер выходит из строя, планшет может быть распределен по многим другим серверам, так что влияние на производительность любого компьютера будет минимальным.
Кроме того, если компьютер выходит из строя, планшет может быть распределен по многим другим серверам, так что влияние на производительность любого компьютера будет минимальным.
Таблицы хранятся как неизменяемые SSTables и хвост журналов (один журнал на машину). Когда машине не хватает системной памяти, она сжимает некоторые планшеты, используя собственные методы сжатия Google (BMDiff и Zippy). Незначительные уплотнения включают только несколько планшетов, в то время как крупные уплотнения включают всю систему таблиц и занимают место на жестком диске.
Расположение планшетов Bigtable хранится в клетках. Поиск любого конкретного планшета обрабатывается трехуровневой системой. Клиенты получают точку в таблице META0, из которых только одна. Таблица META0 отслеживает многие планшеты META1, которые содержат местоположения просматриваемых планшетов. В META0 и META1 интенсивно используются предварительная выборка и кэширование, чтобы минимизировать узкие места в системе.
Реализация
BigTable построен на файловой системе Google (GFS), которая используется в качестве резервного хранилища для файлов журналов и данных. GFS обеспечивает надежное хранилище для SSTables, проприетарного формата файлов Google, используемого для сохранения табличных данных.
GFS обеспечивает надежное хранилище для SSTables, проприетарного формата файлов Google, используемого для сохранения табличных данных.
Другим сервисом, который BigTable активно использует, является Chubby , высокодоступный, надежный сервис распределенных блокировок. Chubby позволяет клиентам захватить блокировку, возможно, связав ее с некоторыми метаданными, которые он может обновить, отправив сообщения о том, что они активны, обратно в Chubby. Блокировки хранятся в иерархической структуре именования в виде файловой системы.
В системе Bigtable интерес представляют три основных типа серверов :
- Главные серверы: назначайте планшеты планшетным серверам, отслеживайте расположение планшетов и перераспределяйте задачи по мере необходимости.
- Планшетные серверы: обрабатывают запросы на чтение / запись для планшетов и разделенных планшетов, когда они превышают предельные размеры (обычно 100–200 МБ). Если происходит сбой планшетного сервера, то на 100 планшетных серверах каждый подхватывает 1 новый планшет, и система восстанавливается.
- Блокировка серверов: экземпляры службы распределенной блокировки Chubby. Множество действий в BigTable требует приобретения замков, включая открытие планшетов для записи, обеспечение того, чтобы одновременно было не более одного активного мастера, и проверку контроля доступа.

Пример из исследовательской работы Google:
Часть примера таблицы, в которой хранятся веб-страницы. Имя строки — это
обратный URL . Семейство столбцов содержимого содержит содержимое страницы , а семейство столбцов привязки содержит
текст любых привязок, которые ссылаются на страницу. На домашнюю страницу CNN ссылаются как домашние страницы Sports Illustrated, так и домашние страницы MY-look, поэтому строка содержит столбцы с именами
anchor:cnnsi.comи
anchor:my.look.ca. Каждая якорная ячейка имеет одну версию ; столбец содержание имеет три версии , на временные метки
t3,t5иt6.

API
Типичными операциями для BigTable являются создание и удаление таблиц и семейств столбцов, запись данных и удаление столбцов из строки. BigTable предоставляет эти функции разработчикам приложений в API. Транзакции поддерживаются на уровне строк, но не для нескольких ключей строк.
Вот ссылка на PDF исследовательской работы .
И здесь вы можете найти видео, показывающее Джеффа Дина из Google на лекции в Университете Вашингтона , где обсуждается система хранения контента Bigtable, используемая в бэкэнде Google.
Можно ли использовать Google Диск в качестве базы данных? Oh! Android
Могу ли я использовать Google Диск в качестве базы данных пользователей?
Мне нужно личное хранилище базы данных онлайн для каждого пользователя моего приложения.
Например, пользователю 1 необходимо сохранить записи в таблице базы данных со списком его онлайн-собраний.
Пользователь 2 также должен хранить записи в аналогичной таблице. Ни один пользователь не должен видеть записи друг друга.
Ни один пользователь не должен видеть записи друг друга.
Google Drive предоставляет разработчикам доступ к папке приложения: https://developers.google.com/drive/android/appfolder
В документации указано, что приложение Folder может использоваться для хранения файлов конфигурации, временных файлов или любых других типов файлов, принадлежащих пользователю, но их не следует подделывать.
Я рад создать файловую базу данных, которая либо имеет один файл, чтобы представлять всю таблицу базы данных (в данном случае все собрания), либо один файл в строке таблицы базы данных (одно собрание).
Это что-то, что я могу хранить в папке приложения Google Диска?
Я понимаю, что в приложении Drive API есть квота, но это кажется очень высоким и не запретительным. Для хранения файлов, которые мне нужны, у самих пользователей должно быть достаточно онлайн-хранилища на Google Диске. Я также изучаю Firebase, но Google Диск был бы намного более дешевым решением и хорошо понятным для потенциальных пользователей.
Да, это возможно. Он будет работать нормально, потому что каждый пользователь имеет свои собственные данные на своем собственном диске. Вы можете хранить как можно больше данных в этой специальной папке, если оно не заполняет всю квоту накопителя.
Лично я сделал это, используя таблицы для моей «базы данных». Я не запрашиваю непосредственно таблицу. Вместо этого я инкрементально синхронизирую его с локальной БД на устройстве и читаю только начиная с последней строки, которую я синхронизировал последним. Очень быстрая синхронизация.
Вы не говорите, где работает ваше приложение, но на рабочем столе Chrome у вас даже есть синхронизация файловой системы Chrome, которая хранится на диске пользователя и автоматически синхронизируется с другими хромированными устройствами.
База данных Google Scholar: особенности системы, опции
База данных Google Scholar – поисковая система нового поколения, специализирующаяся на поиске вторичных источников научных публикаций и информации.
Специализированная система Google Scholar, как и универсальная Google, выдает пользователю результаты поиска, включающие в себя фрагмент текста, название и гиперсвязь к документу.
Робот Google Scholar посещает только те сайты, которые связаны с наукой, и дополняет свой индекс необходимой информацией о содержании и местонахождении научных работ. База данных содержит сведения о бесплатных полнотекстовых публикациях, статьях, у которых доступно только реферативное или библиографическое описание.
В Google Scholar содержатся сведения о статьях, опубликованных в журналах и хранящихся в репозиториях либо на сайтах научных коллективов или личных веб-ресурсах ученых.
- Google Scholar собраны данные о печатных и электронных версиях статей. Робот базы данных занимается индексированием онлайновых научных работ. Если в электронном варианте публикации обнаруживается ссылка на офлайновый документ, он также попадает в базу данных. Офлайновые статьи, выдаваемые в списках результатов поиска, отмечаются пометкой [Citation];
- В списке результатов обязательно имеются ссылки, ведущие к разным страницам, на которых размещаются минимальные сведения о статье – к примеру, библиографические описания. Никаких отсылок в первоначальным источникам в списках нет;
- Поисковый робот может выдавать несколько ссылок на материалы, касающиеся одной и той же публикации: ссылки на сайты издательского дома, на реферативную базу данных, персональный сайт автора работы;
- Правила, по которым работает поисковая система Google Scholar, аналогичны правилам Google;
- Google Scholar и Google – совершенно разные базы данных.
 Никаких отсылок в первоначальным источникам в списках нет;
Никаких отсылок в первоначальным источникам в списках нет;Функции, выполняемые базой данных Google Scholar, не только информационные, но и наукометрические. Список результатов поиска по гиперсвязи содержит такие данные, как количество и перечень документов, ссылающихся на определенную публикацию в пределах базы данных.
Число, указанное в графе Cited by, говорит об уровне авторитетности и популярности научной публикации.
Поскольку заполнением базы данных Google Scholar занимается робот, который не во всех случаях корректно находит и отображает библиографические описания. В итоге это приводит к выдаче весьма интересных результатов: к примеру, можно отыскать научные статьи под авторством Минска.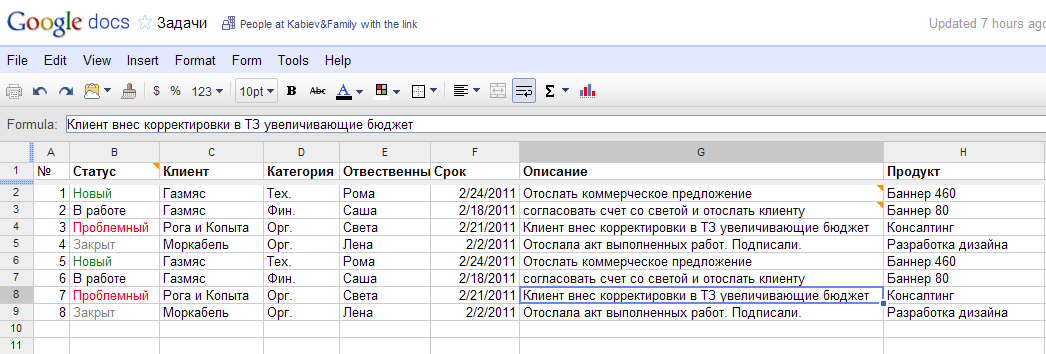
Функции базы данных Google Scholar:
- Поиск публикаций с разных источников;
- Поиск библиографических ссылок, статей, рефератов и прочих научных работ;
- Поиск в базе данных или сети полнотекстового документа;
- Выдача сведений о любых научных работах в разных сферах исследований.
Поиск по всем научным журналам мира
Онлайн базы данных — обзор на CloudERP
2018. В облачной платформе Mail.ru появился сервис аренды баз данных
Игра в догонялки между Mail.ru и Яндексом теперь происходит и на облачном фронте. Недавно Яндекс запустил свою облачную платформу Яндекс.Облако, в составе которой есть сервис аренды баз данных. В Mail.Ru Cloud Solutions такого сервиса не было, поэтому они решили побыстрее это упущение исправить. Новый сервис MCS Базы данных позволяет компаниям быстро разворачивать в облаке популярные базы данных (MySQL, PostgreSQL, Mongo, Galera и Tarantool) и гибко масштабировать их по мере роста проекта. Использование этого PaaS-сервиса даёт возможность сократить время запуска выпускаемых продуктов и сервисов с недель и месяцев до минут. Мониторинг работоспособности и создание бэкапов берёт на себя MCS и гарантирует доступность 99,95%. Стоимость начинается от 1.17 руб/час.
Использование этого PaaS-сервиса даёт возможность сократить время запуска выпускаемых продуктов и сервисов с недель и месяцев до минут. Мониторинг работоспособности и создание бэкапов берёт на себя MCS и гарантирует доступность 99,95%. Стоимость начинается от 1.17 руб/час.
2017. Онлайн-конструктор баз данных и бизнес-приложений GetReport стал бесплатным на 12 пользователей
В 2014 году Forrester Research, международное аналитическое агентство, которое занимается исследованиями рынка информационных технологий, начал отслеживать быстро растущую категорию программного обеспечения, которую обозначили как Low-code development platform. Это платформы, которые обеспечивают быстрое создание бизнес-приложений с минимальным ручным кодированием и минимальными первоначальными инвестициями в настройку, обучение и развертывание. На 2017 год состояние рынка Low-code платформ оценивается в 3,887 миллиарда долларов, прогнозируется, что к 2020 году он вырастет до 15,478 миллиардов долларов.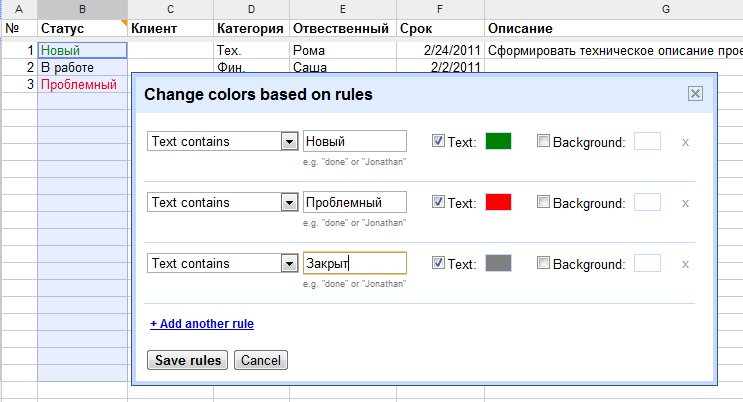 (читать далее) ***
(читать далее) ***
2016. Руна — конструктор для создания бизнес-приложения своими руками
Если вы просмотрели тысячи бизнес-приложений в наших рейтингах и не нашли такого, которое подходит вашей компании, то, возможно, вам будет легче сделать его самостоятельно. К счастью, сейчас для этого не обязательно учить языки программирования — нужно просто понимание того, что вы хотите и умение пользоваться визуальным редактором. Именно так работает конструктор Руна. Это что-то вроде Microsoft Access: вы создаете таблицы с нужными полями в базе данных, формы для ввода и отображения данных и вспомогательные справочники. Зато конструктор Руна — более простой, бесплатный, интегрируется с 1С и работает на Windows, Linux и Android. Платить нужно, только если вы хотите сделать многопользовательскую систему, с которой пользователи смогут работать через интернет. В этом случае — стоимость составит 250 руб/мес за пользователя (т.к. синхронизация будет осуществляться через сервер Руны).
2009. Amazon запустила MySQL as a Service
Как и в прошлом году перед майкрософтовской конференцией разработчиков PDC (где Microsoft анонсирует платформенные новинки), Amazon начинает шевелиться и что-то делать. В прошлом году Microsoft анонсировала Windows Azure, и Amazon тут-же предложила разработчикам виртуальные сервера EC2 под управлением Windows. В этом году на своей конференции Microsoft собирается представить облачную реляционную СУБД Azure SQL. И вот вам ответ Amazon — новый сервис Amazon RDS (Relational Database as a Service), который представляет собой готовую к использованию масштабируемую реляционную базу данных MySQL. ***
2008. Zoho и Google создают новые возможности для SaaS разработчиков
В последние пару недель Zoho и Google анонсировали сразу несколько новинок для своих платформ разработки. Пожалуй, наиболее важная из них — это сервис CloudSQL от Zoho, который позволяет, используя любой удобный язык SQL-запросов (MySQL, PostrgeSQL, MSSQL . ..), получить доступ к базе данных, с которой работают ваши Zoho-приложения. Это означает беспрецедентную возможность интегрировать свои Zoho-приложения с другими SaaS-сервисами или локальными системами.Под Zoho-приложениями имеются в виду как стандартные их сервисы (Zoho CRM, Zoho DB, Zoho Mail …), так и собственные web-приложения, созданные на Zoho Creator.Дополнительно — это возможность когда угодно и в каком-угодно формате бэкапить свои данные, что благоприятно влияет на нервы пользователя.Другие новшества от Zoho и Google для разработчиков:Сделай сам: Приложения Zoho Creator можно установить на Google App EngineРанее создать SaaS приложение на Google App Engine могли только программисты (и только знающие Питон). Теперь каждый, кто умеет перетягивать мышкой квадратики может это сделать. Для этого следует создать приложение на Zoho Creator — обычно это некая база данных с возможностью вводить в нее информацию через форму и отображать данные в различном виде. Приложение в Zoho Creator может сделать любой чайник.
..), получить доступ к базе данных, с которой работают ваши Zoho-приложения. Это означает беспрецедентную возможность интегрировать свои Zoho-приложения с другими SaaS-сервисами или локальными системами.Под Zoho-приложениями имеются в виду как стандартные их сервисы (Zoho CRM, Zoho DB, Zoho Mail …), так и собственные web-приложения, созданные на Zoho Creator.Дополнительно — это возможность когда угодно и в каком-угодно формате бэкапить свои данные, что благоприятно влияет на нервы пользователя.Другие новшества от Zoho и Google для разработчиков:Сделай сам: Приложения Zoho Creator можно установить на Google App EngineРанее создать SaaS приложение на Google App Engine могли только программисты (и только знающие Питон). Теперь каждый, кто умеет перетягивать мышкой квадратики может это сделать. Для этого следует создать приложение на Zoho Creator — обычно это некая база данных с возможностью вводить в нее информацию через форму и отображать данные в различном виде. Приложение в Zoho Creator может сделать любой чайник. Затем это приложение можно экспортировать в спец-формате для Google App Engine, и импортировать его туда.Какой смысл это делать? Во-первых, для обеспечения более надежного и мощного хостинга. Во-вторых, для того, чтоб это приложение можно было разместить на собственном домене. В-третьих, чтобы интегрировать с другими приложениями на платформе гугла…Мониторинг работоспособности приложения на Google App EngineВ панели управления GAE появился раздел, подобный недавно появившемуся сервису Zoho Status для мониторинга вэб-приложений.Модель ценообразования Google App EngineДо сих пор разработчики пользуются GAE бесплатно, но при этом они ограничены некоторыми ежедневными лимитами на использование ресурсов. Поэтому, многих интересует, сколько же прийдется платить, когда этих бесплатных ресурсов не будет хватать.Модель ценообразования GAE напоминает Adwords. Вы устанавливаете максимальный дневной бюджет. Его, кстати, можно распределить между ресурсами (процессор, входящий трафик, исходящий трафик, память)И каждый день, когда бесплатно выделяемые ресурсы будут превышены — начинают капать ваши денежки (в карман гуглу).
Затем это приложение можно экспортировать в спец-формате для Google App Engine, и импортировать его туда.Какой смысл это делать? Во-первых, для обеспечения более надежного и мощного хостинга. Во-вторых, для того, чтоб это приложение можно было разместить на собственном домене. В-третьих, чтобы интегрировать с другими приложениями на платформе гугла…Мониторинг работоспособности приложения на Google App EngineВ панели управления GAE появился раздел, подобный недавно появившемуся сервису Zoho Status для мониторинга вэб-приложений.Модель ценообразования Google App EngineДо сих пор разработчики пользуются GAE бесплатно, но при этом они ограничены некоторыми ежедневными лимитами на использование ресурсов. Поэтому, многих интересует, сколько же прийдется платить, когда этих бесплатных ресурсов не будет хватать.Модель ценообразования GAE напоминает Adwords. Вы устанавливаете максимальный дневной бюджет. Его, кстати, можно распределить между ресурсами (процессор, входящий трафик, исходящий трафик, память)И каждый день, когда бесплатно выделяемые ресурсы будут превышены — начинают капать ваши денежки (в карман гуглу). Сколько их накапало — будет видно в панели управления. Деньги с карточки будут сниматься еженедельно.
Сколько их накапало — будет видно в панели управления. Деньги с карточки будут сниматься еженедельно.
2007. Amazon открыла новую онлайновую базу данных
Компания Amazon открывает новый сервис под названием SimpleDB, представляющий собой онлайновую базу данных. Как сообщает Information Week со ссылкой на заявления вице-президента Amazon Адама Селипски, служба SimpleDB дополнит уже действующие сервисы компании Simple Storage Service (S3) и Elastic Compute Cloud (EC2). Сервис Amazon S3, заработавший в прошлом году, предназначен для хранения больших объемов информации. Подписчики службы S3 платят 15 центов за гигабайт сохраняемых данных и 20 центов за гигабайт передаваемых данных. Что касается системы Amazon EC2, то она позволяет создавать масштабные распределенные веб-сервисы. Новая база данных SimpleDB, по словам Селипски, предназначена для хранения небольших по размеру блоков информации. Это могут быть метаданные или сведения об определенных объектах. Подписчики сервиса смогут осуществлять поиск по базе и получать быстрый доступ к нужной информации. К достоинствам SimpleDB разработчики относят простоту использования, высокую производительность и надежность. Позиционируется сервис SimpleDB в качестве онлайновой альтернативы традиционным реляционным базам данных. Компания Amazon за предоставления доступа к службе SimpleDB не планирует взимать обязательную ежемесячную плату. Подписчикам придется оплачивать только машинное время из расчета 14 центов в час, а также трафик. При этом один гигабайт сохраняемой информации будет стоить 10 центов, а гигабайт извлекаемых из базы данных — 18 центов. Ограниченное тестирование сервиса начнется в течение нескольких ближайших недель. ***
К достоинствам SimpleDB разработчики относят простоту использования, высокую производительность и надежность. Позиционируется сервис SimpleDB в качестве онлайновой альтернативы традиционным реляционным базам данных. Компания Amazon за предоставления доступа к службе SimpleDB не планирует взимать обязательную ежемесячную плату. Подписчикам придется оплачивать только машинное время из расчета 14 центов в час, а также трафик. При этом один гигабайт сохраняемой информации будет стоить 10 центов, а гигабайт извлекаемых из базы данных — 18 центов. Ограниченное тестирование сервиса начнется в течение нескольких ближайших недель. ***
2007. Google купила разработчика web презентаций
Google купил фирму Zenter, компанию, специализирующуюся на разработке программных средств для создания и демонстрации презентаций в онлайне. Технологии Zenter, как ожидается, будут использованы с целью расширения функциональности онлайнового офисного пакета Google Docs & Spreadsheets. В состав Google Docs & Spreadsheets уже сейчас входит приложение для работы с презентациями, созданное на базе методик, выкупленных поисковым гигантом у компании Tonic Systems. Наработки Zenter, предположительно, позволят упростить демонстрацию презентаций через Сеть и их обмен между пользователями интернета
Наработки Zenter, предположительно, позволят упростить демонстрацию презентаций через Сеть и их обмен между пользователями интернета
2007. Zoho Creator поможет создать простое Веб-приложение
Сегодня вышла версия 2.0 сервиса Zoho Creator. Он предназначен для создания простых приложений для работы с базами данных (попросту говоря — таблиц, в которые можно удобно заносить записи, быстро искать их там и редактировать). Естественно, фишка в том, что работать с таким приложением смогут несколько человек. Это может быть база контактов, прайс-лист, учет расходов и доходов и т.д. Все это делается визуально и не требует знания языков программирования. Надо сказать, что подобная штука, если ее грамотно использовать, может быть намного полезней многих навороченных бизнес-приложений.
2007. Dabble — база данных в стиле Web 2.0
Dabble — это онлайн альтернатива MS Access. В этом сервисе есть возможность создать несколько таблиц, связать их и составить перекрёстный отчёт, но при этом не приходится думать о типах связей или индексах. Одна из находок Dabble — это представления (views). Создав или импортировав таблицу, можно сортировать её так или эдак, фильтровать по нужным параметрам, подсчитать какое-нибудь значение по одному из столбцов и сохранить результат в готовом виде, чтобы в любой момент к нему вернуться. Это выгодно отличает Dabble от традиционных СУБД. Чтобы что-то зафиксировать, используя СУБД, нужно приложить усилия: составить запрос и каким-то образом интерпретировать полученные по нему данные. В Dabble DB всё сохраняется прямо по ходу просмотра, и, для того чтобы зафиксировать представление, нужно лишь ввести его названиеВторая особенность, которая заставляет с уважением относиться к Dabble, — это разные подходы к работе с различными форматами данных. К примеру, если один из столбцов таблицы — даты, то, рассказав об этом программе, можно перейти к виду, в котором все записи таблицы будут разложены на календаре. Ещё больше впечатляет карта — её можно увидеть в том случае, если какой-то из столбцов будет содержать географические данные.
Одна из находок Dabble — это представления (views). Создав или импортировав таблицу, можно сортировать её так или эдак, фильтровать по нужным параметрам, подсчитать какое-нибудь значение по одному из столбцов и сохранить результат в готовом виде, чтобы в любой момент к нему вернуться. Это выгодно отличает Dabble от традиционных СУБД. Чтобы что-то зафиксировать, используя СУБД, нужно приложить усилия: составить запрос и каким-то образом интерпретировать полученные по нему данные. В Dabble DB всё сохраняется прямо по ходу просмотра, и, для того чтобы зафиксировать представление, нужно лишь ввести его названиеВторая особенность, которая заставляет с уважением относиться к Dabble, — это разные подходы к работе с различными форматами данных. К примеру, если один из столбцов таблицы — даты, то, рассказав об этом программе, можно перейти к виду, в котором все записи таблицы будут разложены на календаре. Ещё больше впечатляет карта — её можно увидеть в том случае, если какой-то из столбцов будет содержать географические данные. Последний важный плюс Dabble — широкие возможности экспорта данных. Любую из таблиц можно получить не только в виде XLS или CSV, но и PDF и, что самое интересное, RSS и iCal. Таким образом, Dabble очень хорошо интегрируется с другими сервисами и программами. Очень интересно, к примеру, подружить его с Yahoo Pipes. Жаль только, что результат работы Pipes нельзя импортировать в Dabble автоматически.Под конец два главных минуса — необходимость ежемесячной оплаты услуг Dabble и плохая поддержка кириллицы. Правда, оба минуса выражены в довольно мягкой форме. После первого месяца работы придётся либо начинать платить, либо делать свои таблицы общедоступными. Что касается кириллицы, то её надо избегать лишь при выборе названий таблиц и столбцов, да и то лишь в том случае, если данные предполагается экспортировать в RSS.
Последний важный плюс Dabble — широкие возможности экспорта данных. Любую из таблиц можно получить не только в виде XLS или CSV, но и PDF и, что самое интересное, RSS и iCal. Таким образом, Dabble очень хорошо интегрируется с другими сервисами и программами. Очень интересно, к примеру, подружить его с Yahoo Pipes. Жаль только, что результат работы Pipes нельзя импортировать в Dabble автоматически.Под конец два главных минуса — необходимость ежемесячной оплаты услуг Dabble и плохая поддержка кириллицы. Правда, оба минуса выражены в довольно мягкой форме. После первого месяца работы придётся либо начинать платить, либо делать свои таблицы общедоступными. Что касается кириллицы, то её надо избегать лишь при выборе названий таблиц и столбцов, да и то лишь в том случае, если данные предполагается экспортировать в RSS.
2006. ThinkFree заюзал технологию Ajax
Компания ThinkFree представила бета-версию продукта Ajax Edition. Новое онлайн приложение, доступное в рамках сервиса ThinkFree Online, гарантирует совместимость с популярными во всем мире инструментами для редактирования текста, работы с электронными таблицами и создания презентаций, производимыми компанией Microsoft. Новые высокопроизводительные и компактные инструменты позволят создавать превосходные документы с элементами форматирования на базе шаблонов. Пользователи также смогут вносить изменения в уже существующие документы, не беспокоясь о сохранности данных и целостности макета оригинального документа.Разработчики внесли в свой продукт целый ряд усовершенствований, упрощающих коллективную работу с документами. К примеру, теперь пользователь сможет без труда отобразить список изменений, сделанных другими специалистами. Ранее для обнаружения изменений приходилось внимательно просматривать весь документ.Решение ThinkFree Ajax Edition позволяет заниматься подготовкой самых разных документов для персонального или делового использования, выгодно отличаясь от аналогичных web-приложений на базе технологии AJAX, которые не исключают вероятности утери или повреждения данных при чтении и сохранении документов Office.
Новые высокопроизводительные и компактные инструменты позволят создавать превосходные документы с элементами форматирования на базе шаблонов. Пользователи также смогут вносить изменения в уже существующие документы, не беспокоясь о сохранности данных и целостности макета оригинального документа.Разработчики внесли в свой продукт целый ряд усовершенствований, упрощающих коллективную работу с документами. К примеру, теперь пользователь сможет без труда отобразить список изменений, сделанных другими специалистами. Ранее для обнаружения изменений приходилось внимательно просматривать весь документ.Решение ThinkFree Ajax Edition позволяет заниматься подготовкой самых разных документов для персонального или делового использования, выгодно отличаясь от аналогичных web-приложений на базе технологии AJAX, которые не исключают вероятности утери или повреждения данных при чтении и сохранении документов Office.
2006. Google создает онлайн хранилище файлов?
Появилось подозрение, что Google разрабатывает онлайновое файлохранилище. По крайней мере, о подобной возможности говорится в презентации, обнародованной в рамках мероприятия Analyst Day. На одном из слайдов презентации говорится, чтокомпания намерена «собрать всю информацию пользователя в онлайне, включая фотографии, электронные письма,закладки и прочее». Причём доступ к этим данным клиенты смогут получатьс любых устройств, построенных на базе различных программных платформ.Впрочем, о возможных сроках запуска онлайнового хранилища данных Googleпока ничего не сообщается. ***
По крайней мере, о подобной возможности говорится в презентации, обнародованной в рамках мероприятия Analyst Day. На одном из слайдов презентации говорится, чтокомпания намерена «собрать всю информацию пользователя в онлайне, включая фотографии, электронные письма,закладки и прочее». Причём доступ к этим данным клиенты смогут получатьс любых устройств, построенных на базе различных программных платформ.Впрочем, о возможных сроках запуска онлайнового хранилища данных Googleпока ничего не сообщается. ***
1997. IBM Web Data Connector публикует данные на Web сервера
Корпорация IBM расширила область применения своей онлайн базы данных Net.Data — инструментального средства подготовки публикаций в Web, добавив “настоящую” поддержку Oracle и Sybase SQL Server; кроме того, в ней расширена масштабируемость и улучшена поддержка Web-серверов корпораций Microsoft и Netscape Communications. Кроме медленного (но универсального) интерфейса CGI (Соттон Gateway Interface) Net.Data теперь поддерживает собственные протоколы обращения к Web-серверам корпораций Netscape, Microsoft и IBM. Мы не испытывали никаких трудностей, когда во время тестирования использовали Net.Data вместе с Internet Information Server корпорации Microsoft. В дополнение к улучшенной поддержке Web-серверов Net.Data теперь можно сконфигурировать для поддержки пула соединений, чтобы избежать накладных расходов при установлении соединения с БД каждый раз, когда пользователь обращается к Web-странице. Язык программирования Net.Data в данной версии был значительно расширен: введены операторы перехода, стал возможным вызов внешних модулей на языках REXX, Си или Си++ и использование встроенного Java-кода. Net.Data появился в конце января по цене $295; выпускаются версии для операционных сред AIX, OS/2 и Windows NT. Связь Net.Data с системами AS/400 будет бесплатной.
Мы не испытывали никаких трудностей, когда во время тестирования использовали Net.Data вместе с Internet Information Server корпорации Microsoft. В дополнение к улучшенной поддержке Web-серверов Net.Data теперь можно сконфигурировать для поддержки пула соединений, чтобы избежать накладных расходов при установлении соединения с БД каждый раз, когда пользователь обращается к Web-странице. Язык программирования Net.Data в данной версии был значительно расширен: введены операторы перехода, стал возможным вызов внешних модулей на языках REXX, Си или Си++ и использование встроенного Java-кода. Net.Data появился в конце января по цене $295; выпускаются версии для операционных сред AIX, OS/2 и Windows NT. Связь Net.Data с системами AS/400 будет бесплатной.
Подключение к базе данных Google BigQuery в Power BI Desktop — Power BI
-
 000Z» data-article-date-source=»ms.date»>09/30/2020
000Z» data-article-date-source=»ms.date»>09/30/2020 - Чтение занимает 2 мин
В этой статье
В Power BI Desktop вы можете подключиться к базе данных Google BigQuery и использовать ее так же, как и любой другой источник данных в Power BI Desktop.In Power BI Desktop, you can connect to a Google BigQuery database and use the underlying data just like any other data source in Power BI Desktop.
Подключение к Google BigQueryConnect to Google BigQuery
Для подключения к базе данных Google BigQuery на вкладке Главная на ленте в Power BI Desktop выберите Получение данных.To connect to a Google BigQuery database select Get Data from the Home ribbon in Power BI Desktop. В области слева выберите категорию База данных. Отобразится пункт Google BigQuery. Select Database from the categories on the left, and you see Google BigQuery.
Select Database from the categories on the left, and you see Google BigQuery.
В появившемся окне Google BigQuery войдите в свою учетную запись Google BigQuery и выберите команду Подключиться.In the Google BigQuery window that appears, sign in to your Google BigQuery account and select Connect.
После входа вы увидите следующее окно, означающее, что вход выполнен успешно.When you’re signed in, you see the following window indicated you’ve been authenticated.
После успешного подключения откроется окно Навигатор, содержащее данные, доступные на сервере. Из них вы можете выбрать один или несколько элементов для импорта и использования в Power BI Desktop.Once you successfully connect, a Navigator window appears and displays the data available on the server, from which you can select one or multiple elements to import and use in Power BI Desktop.
Рекомендации и ограниченияConsiderations and Limitations
Существуют определенные ограничения и рекомендации, которые следует учитывать в соединителе Google BigQuery.There are a few limits and considerations to keep in mind with the Google BigQuery connector:
Соединитель Google BigQuery доступен в Power BI Desktop и в службе Power BI.The Google BigQuery connector is available in Power BI Desktop and in the Power BI service. В службе Power BI доступ к соединителю может осуществляться с помощью подключения типа «облако к облаку» из Power BI в Google BigQuery.In the Power BI service, the connector can be accessed using the Cloud-to-Cloud connection from Power BI to Google BigQuery.
Power BI можно использовать совместно с Проектом выставления счетов Google BigQuery.You can use Power BI with the Google BigQuery Billing Project. По умолчанию Power BI использует первый проект из списка, возвращаемого пользователю.
By default, Power BI uses the first project from the list returned for the user.Чтобы настроить поведение проекта выставления счетов при использовании Power BI, укажите следующий параметр в разделе M на этапе Source, который можно настроить с помощью редактора Power Query Editor в Power BI Desktop:To customize the behavior of the Billing Project when you use it with Power BI, specify the following option in the underlying M in the Source step, which can be customized by using Power Query Editor in Power BI Desktop:
Source = GoogleBigQuery.Database([BillingProject="Include-Billing-Project-Id-Here"])Начиная с выпуска за сентябрь 2020 года мы включили поддержку API хранения данных Google BigQuery.Beginning in the September 2020 release, we enabled support for the Google BigQuery Storage API. Эта функция включена по умолчанию и управляется необязательным логическим аргументом с именем «UseStorageApi».This feature is enabled by default and is controlled by the optional boolean argument called «UseStorageApi».
Некоторые клиенты могут столкнуться с проблемами с этой функцией, если они используют детализированные разрешения.Some customers might encounter issues with this feature if they use granular permissions. В этом случае может появиться следующее сообщение об ошибке:In this scenario, you might see the following error message:ERROR [HY000] [Microsoft][BigQuery] (131) Unable to authenticate with Google BigQuery Storage API. Check your account permissionsЭту проблему можно устранить, настроив разрешения пользователя для API хранения данных.You can resolve this issue by adjusting the user permissions for Storage API. Назначьте следующие разрешения API хранения данных:Assign these Storage API permissions:
bigquery.readsessions.create— создает новый сеанс чтения через API хранения данных BigQuery.bigquery.readsessions.create— Creates a new read session via the BigQuery Storage API.bigquery.readsessions.getData— считывает данные из сеанса чтения через API хранения данных BigQuery. bigquery.readsessions.getData— Reads data from a read session via the BigQuery Storage API.bigquery.readsessions.update— обновляет сеанс чтения через API хранения данных BigQuery.bigquery.readsessions.update— Updates a read session via the BigQuery Storage API.
Эти разрешения обычно предоставляются в роли BigQuery.User.These permissions typically are provided in the BigQuery.User role. Дополнительные сведения см. в разделе Стандартные роли и разрешения Google BigQuery.For more information, see Google BigQuery Predefined roles and permissions.
Если описанные выше действия не помогли устранить проблему или вы хотите отключить поддержку API хранения, измените запрос следующим образом:If the above steps do not resolve the problem or if you want to disable the support for Storage API, change your query to the following:
Source = GoogleBigQuery.Database([UseStorageApi=false])Если вы уже используете проект выставления счетов, измените запрос следующим образом:Or if you are already using a billing project, change the query to the following:
Source = GoogleBigQuery. Database([BillingProject="Include-Billing-Project-Id-Here", UseStorageApi=false])
 By default, Power BI uses the first project from the list returned for the user.
By default, Power BI uses the first project from the list returned for the user. Некоторые клиенты могут столкнуться с проблемами с этой функцией, если они используют детализированные разрешения.Some customers might encounter issues with this feature if they use granular permissions. В этом случае может появиться следующее сообщение об ошибке:In this scenario, you might see the following error message:
Некоторые клиенты могут столкнуться с проблемами с этой функцией, если они используют детализированные разрешения.Some customers might encounter issues with this feature if they use granular permissions. В этом случае может появиться следующее сообщение об ошибке:In this scenario, you might see the following error message:
 Database([BillingProject="Include-Billing-Project-Id-Here", UseStorageApi=false])
Database([BillingProject="Include-Billing-Project-Id-Here", UseStorageApi=false])
Дальнейшие действияNext steps
В Power BI Desktop можно подключаться к данным самых разных видов.There are all sorts of data you can connect to using Power BI Desktop. Дополнительные сведения об источниках данных см. в перечисленных ниже статьях.For more information on data sources, check out the following resources:
15 баз данных, где можно найти практически все
Чтобы принимать правильные решения, нужно руководствоваться данными. Поэтому качественные источники информации — это половина успеха и в учебе, и в бизнесе. Приготовили подборку из 15 баз данных, где можно найти статистические показатели на разные темы — от ВВП до количества игроков World of Warcraft. В списке есть международные базы и ресурсы с данными по России и Москве. Узнайте, откуда брать свежую информацию, которой можно доверять. А чтобы прокачать критическое мышление, научиться оценивать релевантность данных и использовать их для решения бизнес-задач, приходите на курс Changellenge >> Польза.
Международные базы данных
Показатели развитости стран и индустрий
World Bank Open Data
Что здесь есть: статистические сведения по 570 показателям мирового развития. Временные ряды представлены с 1960 года для 208 стран. Охвачены экономические, социальные, финансовые показатели, данные по природным ресурсам и окружающей среде. Кроме того, база содержит сведения о государственном долге и его выплатах, иностранных инвестициях и финансовых потоках за период с 1970 по 2012 год для 135 стран.
Языки: английский, французский, испанский, арабский, китайский.
Форматы файлов: HTML, PDF.
Кому пригодится: стратегам, консультантам, GR-специалистам.
Лайфхаки: можно подписаться на рассылку новых исследований.
OECD.Stat
Что здесь есть: данные об экономических, финансовых, социальных, научно-технических и отраслевых показателях стран-участников Организации экономического сотрудничества и развития и отдельных стран, не являющихся членами организации. Например, в базе можно найти объем налоговых поступлений и трудовой миграции по индустриям, а также количество патентов разных видов.
Например, в базе можно найти объем налоговых поступлений и трудовой миграции по индустриям, а также количество патентов разных видов.
Языки: английский, французский.
Форматы файлов: XLS, CSV, HTML.
Кому пригодится: стратегам, консультантам, GR-специалистам.
Лайфхаки: зарегистрированному пользователю доступно больше функций. Например, история поиска, создание собственных подборок данных и возможность ими поделиться.
Eurostat
Что здесь есть: информация о странах — членах ЕС. В базе собрана общая и региональная статистика, экономические и финансовые показатели, демографические и социальные условия, данные о промышленности и торговле и многое другое.
Языки: английский, французский, немецкий.
Форматы файлов: PNG, PDF, ZIP, TSV. Файл в формате TSV можно открыть в Excel и сохранить в другом формате.![]()
Кому пригодится: стратегам, консультантам, GR-специалистам.
Лайфхаки: есть опция отправки данных по почте. Зарегистрированные пользователи могут сохранить историю поиска.
Euromonitor International
Что здесь есть: рыночные исследования по странам, индустриям, компаниям и потребителям. Вы получите исчерпывающие данные для анализа бизнес-среды, отраслевых показателей, долей рынка по брендам и компаниям, отраслевого состава крупнейших экономик мира и взаимоотношений между компаниями (B2B).
Языки: английский, французский и немецкий.
Форматы файлов: PDF, XLS, PowerPoint.
Кому пригодится: маркетологам, рекламщикам, PR-специалистам, продакт-менеджерам, инвест-банкирам, стратегам и консультантам.
Лайфхаки: можно купить доступ к онлайн-версии продуктов. Есть специальные тарифы для академических подписок на базы данных. Поэтому на этот ресурс подписаны многие крупные университеты (возможно, и ваш).
Поэтому на этот ресурс подписаны многие крупные университеты (возможно, и ваш).
Statista
Что здесь есть: необычная статистика и отчеты по 150 странам и 600 отраслям. Например, если вам интересно, сколько людей в мире играют в World of Warcraft или у какой доли населения Индии есть смартфоны, то вам сюда.
Языки: английский, французский, немецкий и испанский.
Форматы файлов: PDF, XLS, PPT, PNG.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, продакт-менеджерам, HR-специалистам, инвест-банкирам, стратегам и консультантам.
Лайфхаки: в бесплатном аккаунте есть доступ только к базовой статистике (без данных по отраслям), скачивать информацию можно в PDF и PNG. За 49 долларов дают полный доступ к базе и возможность скачивать файлы в формате XLS. Есть корпоративная подписка для университетов и компаний. Можно заказать собственное исследование.
Можно заказать собственное исследование.
Экономические и финансовые показатели
International Monetary Fund Data
Что здесь есть: данные в виде временных рядов по экономическим и финансовым показателям, обменные курсы в масштабе отдельных стран и мира в целом.
Язык: английский.
Форматы файлов: XLS, PDF, PPT, PNG.
Кому пригодится: инвест-банкирам, стратегам, консультантам, GR-специалистам.
Лайфхаки: данные доступны только после регистрации. Можно подписаться на рассылку обновлений. Есть приложение для iOS.
OPEC Data / Graphs
Что здесь есть: данные стран ОПЕК по нефтяной отрасли (цена, налоги, запасы нефти, информация о производстве и продаже).
Языки: английский, французский.
Форматы файлов: XLS, XML.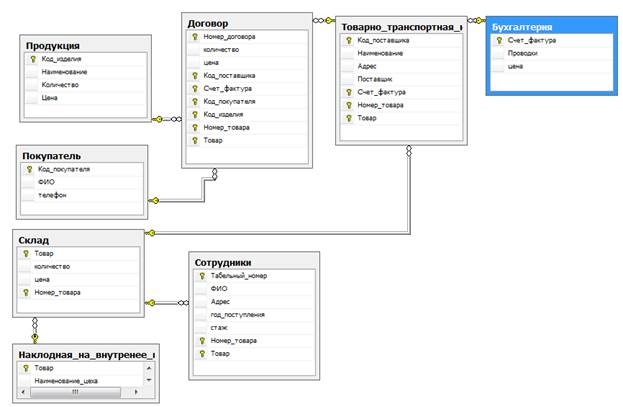
Кому пригодится: инвест-банкирам, стратегам, консультантам, GR-специалистам.
Лайфхаки: есть приложение для iOS и Android.
WTO Statistics
Что здесь есть: данные о торговых потоках, тарифах, нетарифных мерах и доле торговли в добавленной стоимости по странам мира.
Языки: английский, французский, испанский.
Форматы файлов: XLS, CSV, HTML.
Кому пригодится: стратегам, консультантам, GR-специалистам, продакт-менеджерам, маркетологам.
Лайфхаки: у базы есть два варианта поиска данных: Tariff Analysis Online и The Tariff Download Facility. Tariff Analysis Online содержит данные о тарифах на уровне «тарифной линии» — восемь или более цифр кодов Гармонизированной системы описания и кодирования товаров. Чтобы получить доступ, нужно зарегистрироваться. The Tariff Download Facility содержит упрощенные данные — о связанных, применяемых и преференциальных тарифах и статистике импорта.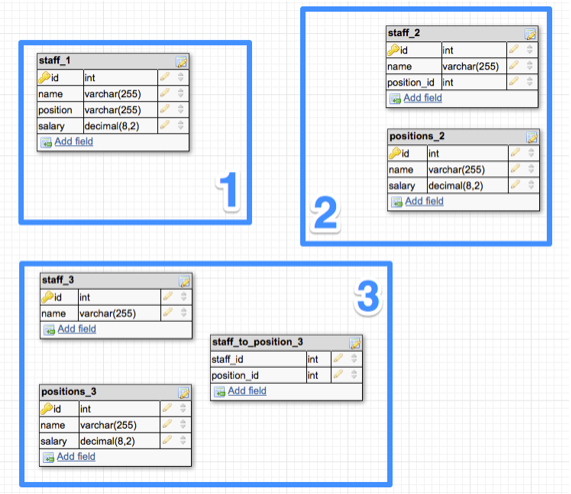 Данные доступны в виде шестизначных кодов Гармонизированной системы описания и кодирования товаров. Информация находится в открытом доступе.
Данные доступны в виде шестизначных кодов Гармонизированной системы описания и кодирования товаров. Информация находится в открытом доступе.
Базы данных по РФ
Финансовые показатели
Центральный банк РФ / Статистика
Что здесь есть: официальная статистика Центробанка РФ. В базе собраны макроэкономические показатели, показатели банковского сектора, финансового рынка, национальной платежной системы и операций денежно-кредитной политики.
Язык: русский.
Форматы файлов: DOC, XLS, PDF, ARJ. Формат архива ARJ можно открыть архиваторами для ZIP.
Кому пригодится: инвест-банкирам, стратегам, консультантам, GR-специалистам.
Лайфхаки: данные до 2008–2012 годов лежат в Архиве.
Показатели развитости индустрий в стране
Национальное агентство финансовых исследований
Что здесь есть: исследования, аналитика и прогнозы по разным темам (финансы, социальное развитие, предпринимательство, IT и телеком, строительство, рынок труда и HR, бренд и реклама, PR и GR-проекты).
Язык: русский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, продакт-менеджерам, проджект-менеджерам, HR-специалистам, инвест-банкирам, стратегам и консультантам.
Лайфхаки: часть данных находится в открытом доступе. Можно бесплатно подписаться на рассылку и получать новые исследования. Есть возможность заказать свое исследование.
JSON.TV
Что здесь есть: исследования преимущественно по техническим тематикам. В базе можно найти данные об интернете вещей, цифровизации, блокчейне, искусственном интеллекте, телекоме, а также рекламе, онлайн-играх, образовании и многом другом.
Языки: русский, английский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: Продакт-менеджерам, проджект-менеджерам, стратегам и консультантам.
Лайфхаки: после регистрации доступна краткая версия исследований. За полную нужно заплатить.
Социологические исследования
Всероссийский центр изучения общественного мнения
Что здесь есть: социологические исследования, рейтинги политиков, индексы одобрения государственных и общественных институтов и другие опросы общественного мнения.
Язык: русский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, HR-специалистам.
Лайфхаки: можно заказать свое исследование.
Аналитический центр Юрия Левады
Что здесь есть: результаты опросов общественного мнениях на разные темы начиная с 1988 года.
Языки: русский, английский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: GR- и PR-специалистам.
Лайфхаки: можно оформить бесплатную подписку и получать новые исследования.
Фонд «Общественное мнение»
Что здесь есть: социологические и маркетинговые данные, собранные в результате опросов разных групп населения. Исследования и аналитика по темам: образ жизни, ценности, работа и дом, экономика, СМИ и интернет.
Язык: русский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, продакт-менеджерам, проджект-менеджерам, HR-специалистам.
Лайфхаки: можно заказать исследование.
База данных по Москве
Портал открытых данных правительства Москвы
Что здесь есть: информация по таким категориям, как транспорт, ЖКХ, здравоохранение, культура, общественное питание, строительство, трудоустройство и так далее.
Языки: русский, английский.
Форматы файлов: XLS, HTML, JSON. Формат JSON можно открыть в «Блокноте» или конвертировать в CSV для работы в Excel.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, продакт-менеджерам, проджект-менеджерам, HR-специалистам, стратегам и консультантам.
Лайфхаки: на главной странице есть информация об обновлениях.
Теги
Реляционные | Раствор для чистого металлаПоднимите и перенесите рабочие нагрузки Oracle в Google Cloud |
|
Облако SQLУправляемый MySQL, PostgreSQL и SQL Server Узнайте, как выполнить миграцию из таких баз данных, как |
| |
Облачный гаечный ключ Cloud-native с неограниченным масштабированием, согласованностью и Узнайте, как выполнить миграцию из таких баз данных, как | ||
Ключевое значение | Облако Bigtable Облачное хранилище с широкими столбцами NoSQL для больших масштабов, Узнайте, как перейти с |
|
Документ | Firestore Cloud-native NoSQL для простой разработки многофункциональных мобильных, | |
База данных Firebase в реальном времениХранение и синхронизация данных в реальном времени | ||
В памяти | Память Полностью управляемые Redis и Memcached за менее миллисекунды |
|
Дополнительный NoSQL | MongoDB АтласГлобальная облачная служба баз данных для современных приложений | |
Google Cloud Partner Services управляемых предложений от нашего партнера с открытым исходным кодом |
 999% доступность
999% доступностьПочему не следует использовать Google Таблицы в качестве базы данных | Эрик Коледа
В этом году на Google Cloud Next я выступил со-представителем сессии под названием «Как превратить электронную таблицу в приложение», где тезис заключался в том, что OK начать с электронной таблицы и слоя дополнительных технологий, как вы получить признание, и ваши требования изменятся.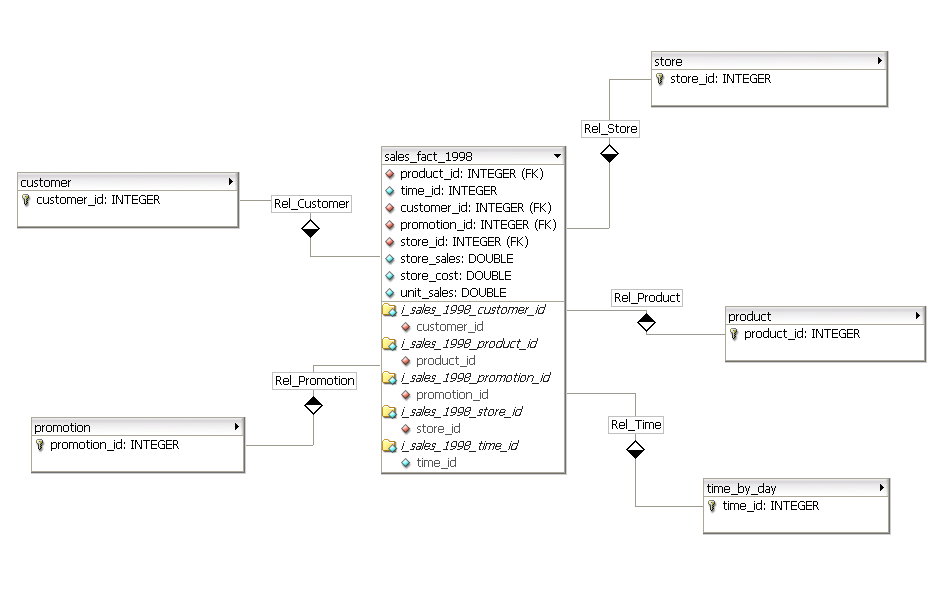 Однако это не означает, что Таблицы всегда являются отличным выбором для хранения данных вашего приложения, и в этом посте я рассмотрю некоторые сигналы, по которым вам следует искать другие варианты базы данных.
Однако это не означает, что Таблицы всегда являются отличным выбором для хранения данных вашего приложения, и в этом посте я рассмотрю некоторые сигналы, по которым вам следует искать другие варианты базы данных.
Примечание : В этом посте я использую термин «база данных» для обозначения внутреннего хранилища данных, которое разработчик программного обеспечения использует при создании приложения. Для более разговорного значения «список вещей, которые я пытаюсь отслеживать», не бойтесь, электронная таблица — отличный вариант!
База данных Ника Янгсона CC BY-SA 3.0 Alpha Stock Images
Таблицы для людей
В первую очередь Таблицы — это инструмент для пользователей , позволяющий им исследовать свои данные и работать с ними. Это хранилище данных, оптимизированное с учетом поведения человека, а не масштаб и пропускная способность, которые требуются большинству приложений. Нет схемы, нет проблем! Вычисляемые поля, которые зависят от других вычисляемых полей, конечно!
Хотя вы можете получать доступ к таблицам и изменять их программно — с помощью Drive API, Sheets API или Apps Script — базовая архитектура была создана и оптимизирована для пользователей. Например, Таблицы хранятся на Google Диске пользователя, и если его учетная запись заблокирована или удалена, данные уходят вместе с ней.
Например, Таблицы хранятся на Google Диске пользователя, и если его учетная запись заблокирована или удалена, данные уходят вместе с ней.
Практическое правило: если вы не ожидаете, что пользователи откроют электронную таблицу, вам, вероятно, не следует хранить там свои данные.
Не все Таблицы используются одинаково
Вообще говоря, есть три широкие категории приложений, которые хранят данные в Таблицах:
- Совместная работа над электронной таблицей — Приложение похоже на помощника, которое делает что-то полезное для пользователя и очень во многом сосредоточен на электронной таблице.Например, у вас может быть приложение, которое синхронизирует некоторые данные на листе с внешней системой. Если пользователь удаляет таблицу, это нормально, значит, приложение просто помогало.
- Использование электронной таблицы в качестве ввода / вывода — Приложение использует электронную таблицу как удобный интерфейс для ввода данных или создания отчетов. Например, позволяя пользователям массово добавлять новые записи или загружать отчет. Если пользователь удаляет таблицу, это нормально, данные всегда хранятся в другом месте.
- Использование электронной таблицы в качестве базы данных — Приложение использует Таблицы в качестве постоянного хранилища некоторых данных и обслуживает их. Например, небольшие приложения для рабочего процесса, такие как утверждение расходов. Если пользователь удаляет электронную таблицу, приложение не работает.
Приложения, которые попадают в категории №1 и №2, полностью подходят для моей книги, поскольку они работают с пользователями в центре и в человеческом масштабе. Категория №3 — самая напряженная и центральная в этом посте.
Вам следует рассматривать использование Таблиц в качестве базы данных только в том случае, если объем данных небольшой, трафик невелик, а некоторые пользователи (утверждающие и т. Д.) Все еще регулярно открывают электронную таблицу. Если что-либо из этого неверно, вам следует сохранить свои данные в соответствующей базе данных.
Холодные, точные числа
Даже если вы хотите проигнорировать все «правильные» способы использования электронных таблиц, существуют лишь некоторые жесткие ограничения, которые делают их плохо подходящими в качестве базы данных. Несмотря на то, что команда Таблиц за эти годы добилась больших успехов в разрешении хранения большего количества данных в электронной таблице, текущего ограничения в 5 миллионов ячеек, вероятно, будет недостаточно для многих приложений большого или среднего размера.Кроме того, квоты API Таблиц ограничивают ваше приложение где-то между 1–5 запросами в секунду, устанавливая верхний предел для функций реального времени, которые вы можете предоставить, и одновременных пользователей, которых вы можете поддерживать.
Функции базы данных, которые вы пропустите
Несмотря на все возможности Sheets, есть некоторые общие функции, которые вы пропустите, если будете полагаться на нее как на базу данных:
- Запросы: помимо
= Формула QUERY, вы не можете выполнять поиск по своим данным - Согласованность : все, что находится в ячейке электронной таблицы, и правки пользователя добавляют еще больше хаоса
- Присоединяется к : вы можете немного подделать
= ВПРи= IMPORTRANGE, но когда вы выходите за пределы таблицы или двух данных, вещи ломаются
Альтернативы, которые следует рассмотреть
Итак, я убедил вас отказаться от электронной таблицы, что теперь?
База данных Firebase Realtime — отличный способ хранить большие двоичные объекты JSON и возвращать их позже. Если вас не интересуют функции базы данных и вам просто нужно больше места или пропускной способности, это отличный вариант. В новой базе данных Cloud Firestore это расширяется за счет дальнейшего увеличения масштабирования и добавления поддержки схем. У обоих есть уровень бесплатного пользования, что делает его следующим шагом, если вы переросли электронную таблицу.
Если вас не интересуют функции базы данных и вам просто нужно больше места или пропускной способности, это отличный вариант. В новой базе данных Cloud Firestore это расширяется за счет дальнейшего увеличения масштабирования и добавления поддержки схем. У обоих есть уровень бесплатного пользования, что делает его следующим шагом, если вы переросли электронную таблицу.
Если вы настроены на более традиционную базу данных, тогда Google Cloud SQL — вариант, позволяющий настроить полностью управляемые базы данных MySQL и PostgreSQL за считанные минуты. Это то, что Google App Maker использует под капотом, и существует множество ORM, которые упрощают работу с данными на выбранном вами языке программирования.Цены здесь немного сложны (мягко говоря), но TL; DR вы будете тратить как минимум пару долларов в месяц только для того, чтобы согреть серверы.
Наконец, если вам нужно хранилище данных вместо базы данных (журналирование транзакций и т. Д.), Вам стоит взглянуть на BigQuery. Он отлично подходит для хранения и анализа больших объемов структурированных данных, а с предстоящей функцией связанных листов вы можете легко вернуть эти данные в Таблицы для дальнейшего изучения.
Но не забывайте о Таблицах!
Тот факт, что вы переместили данные в другую базу данных, не означает, что вам нужно полностью отказываться от Таблиц.Вы можете перейти к другим категориям использования, которые я описал ранее, используя Таблицы как расширение вашего пользовательского интерфейса, а не как хранилище данных. Например, в нашей лаборатории кода API Таблиц мы демонстрируем, как вы можете использовать Таблицы в качестве настраиваемого инструмента отчетности для своего приложения, синхронизируя выбранные данные с электронной таблицей и автоматически создавая полезные сводные таблицы и диаграммы.
Обозреватель базы данных — Google Workspace Marketplace
Запросите свою базу данных и отредактируйте ее из таблицы Google.
Обозреватель баз данных делает Google Sheet потрясающим новым способом просмотра вашей базы данных.Подключите базу данных, составьте список таблиц, запросите записи таблицы в Google Sheet с интуитивно понятным и ярким графическим интерфейсом.
 Эта надстройка «Браузер баз данных» предоставляет простой графический интерфейс для установления соединения с базами данных, просмотра таблиц и запроса записей в Google Sheet.
ПОДДЕРЖИВАЕМЫЕ БАЗЫ ДАННЫХ
► MySQL
► Oracle
► Microsoft SQL Server
► Google Cloud SQL
► Google BigQuery
► mLab - MongoDB
► Магазин огня
► Хранилище данных
► MongoDB (любой включает Атлас)
► PostgreSQL
КЛЮЧЕВАЯ ОСОБЕННОСТЬ
► Управление подключениями - создавайте, тестируйте и сохраняйте подключения к базам данных в Интернете и в облаке.► Управление запросами - создавайте, выполняйте, сохраняйте запросы и результаты запросов в Google Sheet.
► Редактировать - вставлять и обновлять записи в таблице базы данных, добавляя и изменяя данные из таблицы Google (это профессиональная функция)
► Автоматическое выполнение запроса в фоновом режиме и журналы истории выполнения
Наша миссия состоит в том, чтобы упростить изучение баз данных с удобством Google Sheet.
УПРАВЛЕНИЕ СОЕДИНЕНИЯМИ
► Пользователь может подготовить соединение, указав тип базы данных, IP-адрес хоста, имя базы данных, имя пользователя и пароль или другие параметры.
Эта надстройка «Браузер баз данных» предоставляет простой графический интерфейс для установления соединения с базами данных, просмотра таблиц и запроса записей в Google Sheet.
ПОДДЕРЖИВАЕМЫЕ БАЗЫ ДАННЫХ
► MySQL
► Oracle
► Microsoft SQL Server
► Google Cloud SQL
► Google BigQuery
► mLab - MongoDB
► Магазин огня
► Хранилище данных
► MongoDB (любой включает Атлас)
► PostgreSQL
КЛЮЧЕВАЯ ОСОБЕННОСТЬ
► Управление подключениями - создавайте, тестируйте и сохраняйте подключения к базам данных в Интернете и в облаке.► Управление запросами - создавайте, выполняйте, сохраняйте запросы и результаты запросов в Google Sheet.
► Редактировать - вставлять и обновлять записи в таблице базы данных, добавляя и изменяя данные из таблицы Google (это профессиональная функция)
► Автоматическое выполнение запроса в фоновом режиме и журналы истории выполнения
Наша миссия состоит в том, чтобы упростить изучение баз данных с удобством Google Sheet.
УПРАВЛЕНИЕ СОЕДИНЕНИЯМИ
► Пользователь может подготовить соединение, указав тип базы данных, IP-адрес хоста, имя базы данных, имя пользователя и пароль или другие параметры. ► Пользователь может указать имя соединения, чтобы на него можно было ссылаться в запросе
► Пользователь может проверить, успешно ли установлено соединение для данной конфигурации
► Пользователь может перечислять, добавлять, изменять, удалять подключения
УПРАВЛЕНИЕ ЗАПРОСАМИ
► Пользователь может подготовить запрос, выбрав соединение, таблицы и поля таблицы
► Пользователь может подготовить предложение where запроса, визуально выбрав поля и сформировав условия
► Пользователь может указать имя для запроса
► Пользователь может выполнить запрос и отобразить / сохранить результаты в Google Sheet
► Пользователь может перечислять, добавлять, изменять, удалять запросы
РЕДАКТИРОВАТЬ
► Пользователь может добавить новую строку в лист Google, которая будет добавлена в таблицу базы данных.
► Пользователь может обновить строку в листе Google, которая обновляется в таблице базы данных.
Базовые функции «Обозревателя баз данных» можно начать БЕСПЛАТНО.Расширенные функции, такие как редактирование, автоматическое (фоновое) выполнение и расширенная квота, доступны для платных планов.
► Пользователь может указать имя соединения, чтобы на него можно было ссылаться в запросе
► Пользователь может проверить, успешно ли установлено соединение для данной конфигурации
► Пользователь может перечислять, добавлять, изменять, удалять подключения
УПРАВЛЕНИЕ ЗАПРОСАМИ
► Пользователь может подготовить запрос, выбрав соединение, таблицы и поля таблицы
► Пользователь может подготовить предложение where запроса, визуально выбрав поля и сформировав условия
► Пользователь может указать имя для запроса
► Пользователь может выполнить запрос и отобразить / сохранить результаты в Google Sheet
► Пользователь может перечислять, добавлять, изменять, удалять запросы
РЕДАКТИРОВАТЬ
► Пользователь может добавить новую строку в лист Google, которая будет добавлена в таблицу базы данных.
► Пользователь может обновить строку в листе Google, которая обновляется в таблице базы данных.
Базовые функции «Обозревателя баз данных» можно начать БЕСПЛАТНО.Расширенные функции, такие как редактирование, автоматическое (фоновое) выполнение и расширенная квота, доступны для платных планов.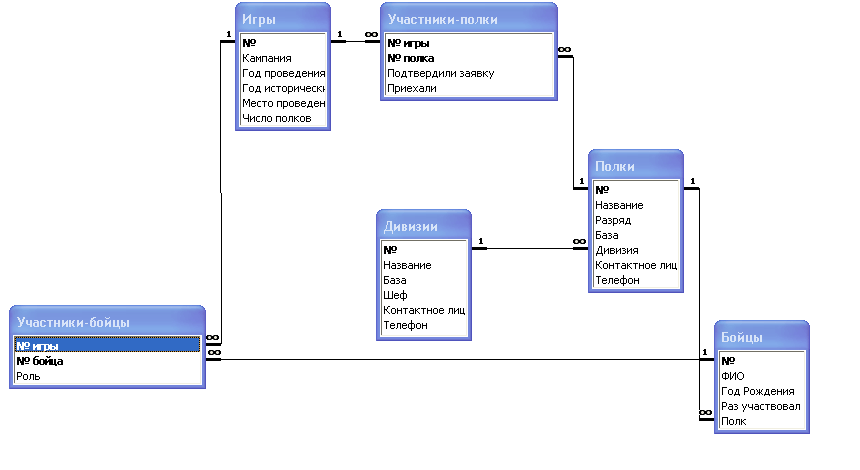 ПОДДЕРЖИВАТЬ
Подробнее см. Http://databasebrowser.jivrus.com/
Свяжитесь с нами по адресу http://www.jivrus.com/about/contact-us или по электронной почте
ПОДДЕРЖИВАТЬ
Подробнее см. Http://databasebrowser.jivrus.com/
Свяжитесь с нами по адресу http://www.jivrus.com/about/contact-us или по электронной почте База данных Firebase в реальном времени
Храните и синхронизируйте данные с нашей облачной базой данных NoSQL. Данные
синхронизируется между всеми клиентами в реальном времени и остается доступным, когда ваш
приложение отключается.
База данных Firebase Realtime — это база данных, размещенная в облаке. Данные хранятся в формате JSON
и синхронизируются в реальном времени с каждым подключенным клиентом. Когда вы строите
кроссплатформенные приложения с нашими SDK для iOS, Android и JavaScript, все ваши
клиенты совместно используют один экземпляр базы данных Realtime и автоматически получают обновления с
новейшие данные.
настройка iOS
Настройка Android
Настройка через Интернет
REST API
Настройка C ++
Настройка Unity
Настройка администратора
Основные возможности
| В реальном времени | Вместо обычных HTTP-запросов база данных Firebase Realtime использует данные синхронизация — каждый раз при изменении данных любое подключенное устройство получает это обновление за миллисекунды.  Обеспечьте сотрудничество и Обеспечьте сотрудничество ииммерсивный опыт, не думая о сетевом коде. |
| Не в сети | Приложения Firebase остаются отзывчивыми даже в автономном режиме, потому что Firebase Realtime Database SDK сохраняет ваши данные на диске. После подключения восстанавливается, клиентское устройство получает все пропущенные изменения, синхронизируя его с текущим состоянием сервера. |
| Доступно с клиентских устройств | Доступ к базе данных Firebase Realtime можно получить прямо с мобильного устройства. или веб-браузер; нет необходимости в сервере приложений.Безопасность и проверка данных доступна через базу данных Firebase Realtime. Правила безопасности, правила на основе выражений, которые выполняются, когда данные прочитал или написал. |
| Масштабирование для нескольких баз данных | С базой данных Firebase Realtime в тарифном плане Blaze вы можете поддерживать масштабируемость потребностей вашего приложения в данных за счет разделения данных на несколько экземпляры базы данных в одном проекте Firebase.  Оптимизация аутентификации Оптимизация аутентификациис Firebase Authentication в вашем проекте и аутентифицировать пользователей через ваши экземпляры базы данных.Управляйте доступом к данным в каждой базе данных с помощью настраиваемые правила базы данных Firebase Realtime для каждого экземпляра базы данных. |
Как это работает?
База данных Firebase Realtime позволяет создавать многофункциональные приложения для совместной работы.
разрешая безопасный доступ к базе данных непосредственно из клиентского кода. Данные
сохраняется локально, и даже в автономном режиме события в реальном времени продолжают запускаться,
давая конечному пользователю возможность быстро реагировать. Когда устройство восстановит соединение,
База данных реального времени синхронизирует изменения локальных данных с удаленными обновлениями
это произошло, когда клиент был в автономном режиме, автоматически объединяя любые конфликты.
База данных реального времени предоставляет гибкий язык правил на основе выражений,
называется Firebase Realtime Database Security Rules, чтобы определить, как ваши данные должны быть
структурированы и когда данные могут быть прочитаны или записаны.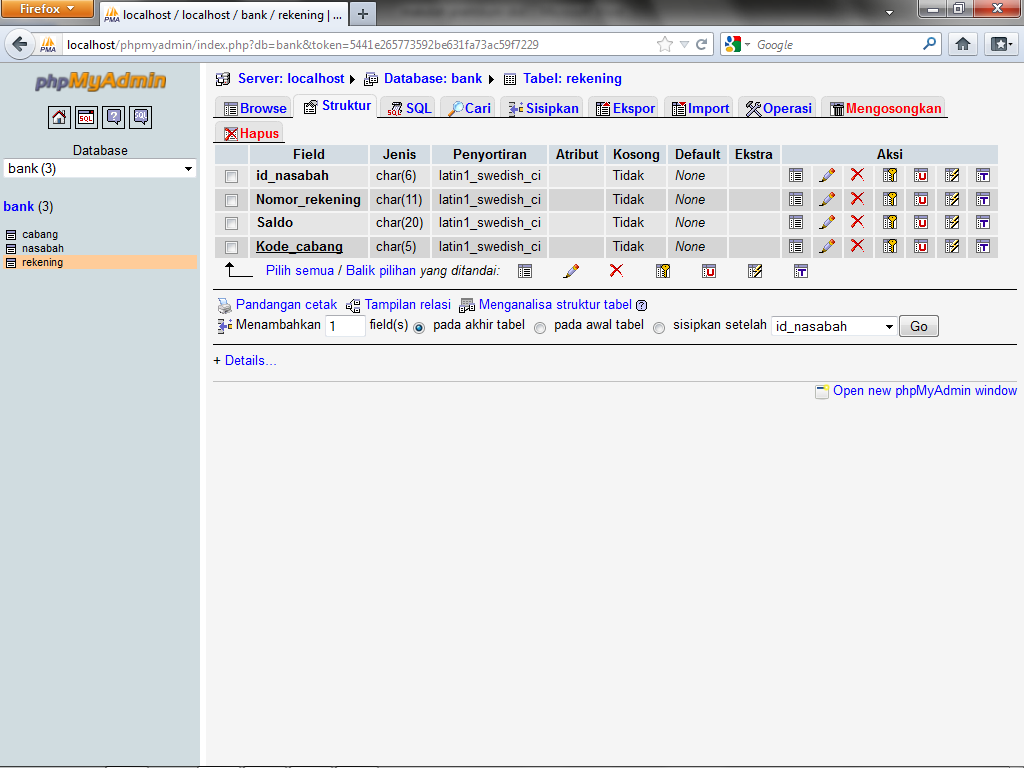 При интеграции с
При интеграции с
Firebase Authentication, разработчики могут определять, кто и как имеет доступ к каким данным.
они могут получить к нему доступ.
База данных реального времени — это база данных NoSQL, поэтому она имеет различные оптимизации.
и функциональность по сравнению с реляционной базой данных.API базы данных реального времени
разработан, чтобы разрешить только операции, которые могут быть выполнены быстро. Это позволяет вам
для создания отличного опыта в реальном времени, который может обслуживать миллионы пользователей без
компромисс по отзывчивости. В связи с этим важно думать о
как пользователям нужен доступ к вашим данным, а затем
структурируйте его соответствующим образом.
Способ реализации
| Интегрируйте SDK базы данных Firebase Realtime | Быстро подключайте клиентов через Gradle, CocoaPods или скрипт. | |
| Создание ссылок на базу данных в реальном времени | Ссылайтесь на свои данные JSON, например «users / user: 1234 / phone_number», чтобы установить data или подпишитесь на изменение данных.  | |
| Установка данных и отслеживание изменений | Используйте эти ссылки для записи данных или подписки на изменения. | |
| Включить автономное сохранение | Разрешить запись данных на локальный диск устройства, чтобы они были доступны в автономном режиме. | |
| Защитите свои данные | Используйте правила безопасности баз данных Firebase в реальном времени для защиты ваших данных. |
Хотите хранить другие типы данных?
- Cloud Firestore — это гибкая масштабируемая база данных для
разработка мобильных, веб-приложений и серверов с помощью Firebase и Google Cloud Platform.
Чтобы узнать больше о различиях между параметрами базы данных, см.
Выберите базу данных: Cloud Firestore или Realtime Database. - Firebase Remote Config хранит указанный разработчик
пары ключ-значение для изменения поведения и внешнего вида вашего приложения без
требуя от пользователей загрузки обновления. - Firebase Hosting размещает HTML, CSS и
JavaScript для вашего веб-сайта, а также других ресурсов, предоставляемых разработчиком, например
графика, шрифты и значки. - Cloud Storage хранит такие файлы, как изображения,
видео и аудио, а также другой пользовательский контент.
Следующие шаги:
Google догоняет AWS и Azure с новым сервисом миграции баз данных
Сегодня компания Google официально представила свою новую службу миграции баз данных (DMS), призванную упростить для клиентов Google Cloud перенос своих баз данных MySQL, PostgreSQL и SQL Server в полностью управляемую службу баз данных Cloud SQL от Google.
Это было давно, учитывая, что AWS Amazon запустила службу миграции баз данных более пяти лет назад, а Microsoft запустила свое воплощение для Azure два года спустя.
Google уже предлагал услуги миграции баз данных в рамках партнерства с такими компаниями, как Striim, но устранение посредника упрощает процесс и снижает как время, так и вероятность того, что что-то пойдет не так во время переноса.
Одна из основных причин, по которой Google запускает свою DMS сейчас, заключается в том, чтобы извлечь выгоду из резкого роста спроса на облачные вычисления, вызванного глобальной пандемией, и побудить компании перенести свои базы данных из локальной инфраструктуры в более масштабируемую бессерверную версию на базе Google. облако.Но компании также могут использовать службу миграции для переноса баз данных от других облачных провайдеров, включая AWS и Azure, поэтому сегодняшние новости фактически ставят Google наравне с Amazon и Microsoft с точки зрения предоставления собственных инструментов, чтобы побудить компании сделать переход.
Кроме того, по данным Gartner, к 2023 году 75% баз данных будут храниться в облаке, и предоставление инструментов для этого перехода могло бы побудить большее количество предприятий в долгосрочной перспективе использовать Google Cloud, а не его конкурентов.
«Поскольку подавляющее большинство рабочих нагрузок все еще выполняется локально, для облака все еще очень рано, и мы думаем, что у нас невероятно дифференцированный подход», — сказал VentureBeat представитель Google.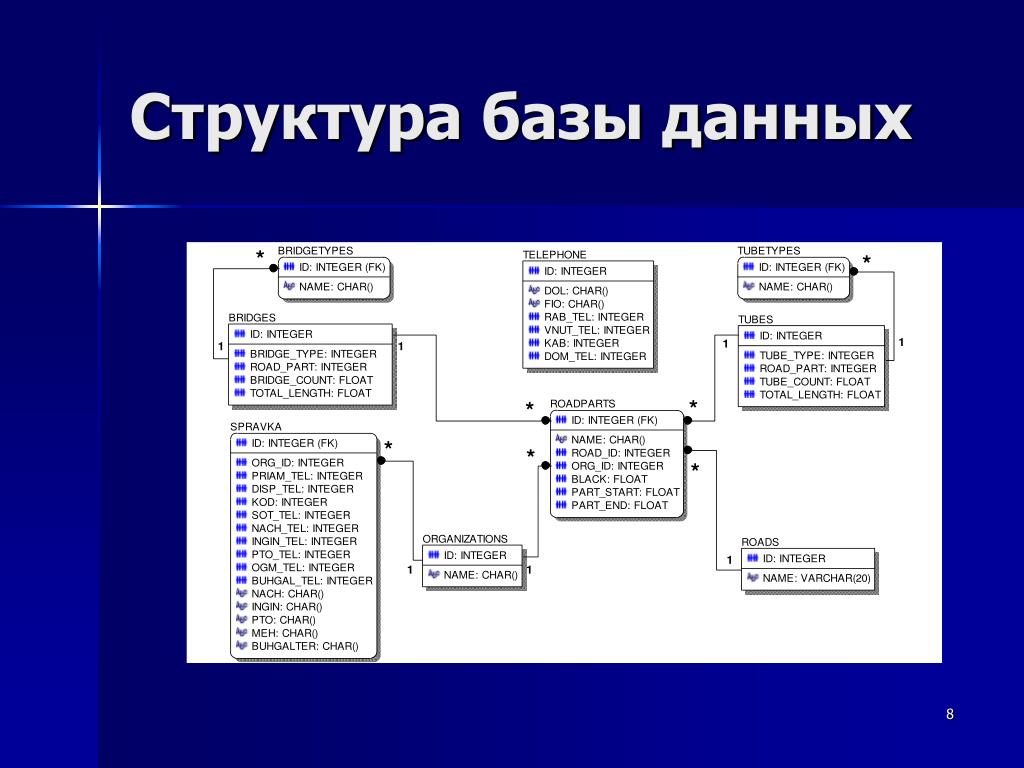 «По сравнению с тем, что было всего несколько лет назад, спрос больше не только на аренду серверных площадей в наших центрах обработки данных».
«По сравнению с тем, что было всего несколько лет назад, спрос больше не только на аренду серверных площадей в наших центрах обработки данных».
Google в целом отставал от AWS и Azure в сфере общедоступной облачной инфраструктуры, при этом в 2019 году их дуэт претендовал на долю рынка около 45% и 18% соответственно — Google, со своей стороны, принадлежал около 5%.Ранее в этом году Alphabet впервые начала выделять доход от Google Cloud, и, хотя его рост в настоящее время превышает рост AWS, трудно проводить четкие сравнения, учитывая, что Google объединяет G Suite вместе с Google Cloud Platform при составлении отчетов о своих финансовых показателях.
DMS доступна в предварительной версии для аналогичных миграций с сегодняшнего дня для баз данных MySQL, в то время как поддержка PostgreSQL доступна только для «ограниченных клиентов» в предварительной версии, а SQL Server «скоро появится».”
VentureBeat
Миссия VentureBeat — стать цифровой городской площадью, где лица, принимающие технические решения, могут получить знания о трансформирующих технологиях и транзакциях.
На нашем сайте представлена важная информация о технологиях и стратегиях обработки данных, которая поможет вам руководить своей организацией. Мы приглашаем вас стать членом нашего сообщества, чтобы получить доступ:
- актуальная информация по интересующим вас вопросам
- наши информационные бюллетени
- закрытый контент для лидеров мысли и доступ со скидкой на наши призовые мероприятия, такие как Transform
- сетевых функций и многое другое
Стать участником
Безопасность | Стеклянная дверь
Мы получаем подозрительную активность от вас или от кого-то, кто использует вашу интернет-сеть.Подождите, пока мы убедимся, что вы настоящий человек. Ваш контент появится в ближайшее время.
Если вы продолжаете видеть это сообщение, напишите нам
чтобы сообщить нам, что у вас проблемы.
Nous aider à garder Glassdoor sécurisée
Nous avons reçu des activités suspectes venant de quelqu’un utilisant votre réseau internet.
Подвеска Veuillez Patient que nous vérifions que vous êtes une vraie personne. Вотре содержание
apparaîtra bientôt. Si vous continuez à voir ce message, veuillez envoyer un
электронная почта à
pour nous informer du désagrément.
Unterstützen Sie uns beim Schutz von Glassdoor
Wir haben einige verdächtige Aktivitäten von Ihnen oder von jemandem, der in ihrem
Интернет-Netzwerk angemeldet ist, festgestellt. Bitte warten Sie, während wir
überprüfen, ob Sie ein Mensch und kein Bot sind. Ihr Inhalt wird в Kürze angezeigt.
Wenn Sie weiterhin diese Meldung erhalten, informieren Sie uns darüber bitte по электронной почте:
.
We hebben verdachte activiteiten waargenomen op Glassdoor van iemand of iemand die uw internet netwerk deelt.Een momentje geduld totdat, мы исследовали, что u daadwerkelijk een persoon bent. Uw bijdrage zal spoedig te zien zijn.
Als u deze melding blijft zien, электронная почта:
om ons te laten weten dat uw проблема zich nog steeds voordoet.
Hemos estado detectando actividad sospechosa tuya o de alguien con quien compare tu red de Internet. Эспера
Эспера
mientras verificamos que eres una persona real. Tu contenido se mostrará en breve. Si Continúas recibiendo
este mensaje, envía un correo electrónico
a para informarnos de
que tienes problemas.
Hemos estado percibiendo actividad sospechosa de ti o de alguien con quien compare tu red de Internet. Эспера
mientras verificamos que eres una persona real. Tu contenido se mostrará en breve. Si Continúas recibiendo este
mensaje, envía un correo electrónico a
para hacernos saber que
estás teniendo problemas.
Temos Recebido algumas atividades suspeitas de voiceê ou de alguém que esteja usando a mesma rede. Aguarde enquanto
confirmamos que Você é Uma Pessoa de Verdade.Сеу контексто апаресера эм бреве. Caso продолжить Recebendo esta
mensagem, envie um email para
пункт нет
informar sobre o проблема.
Abbiamo notato alcune attività sospette da parte tua o di una persona che condivide la tua rete Internet.
Attendi mentre verifichiamo Che sei una persona reale. Il tuo contenuto verrà visualizzato a breve. Secontini
Secontini
Visualizzare questo messaggio, invia un’e-mail all’indirizzo
per informarci del
проблема.
Пожалуйста, включите куки и перезагрузите страницу.
Это автоматический процесс. Ваш браузер в ближайшее время перенаправит вас на запрошенный контент.
Подождите до 5 секунд…
Перенаправление…
Код объявления: CF-102 / 62585fcacfb31756.
Использование таблиц Google в качестве базы данных: всесторонний анализ — выучить
Используете ли вы или ваша организация Google Таблицы для хранения данных? Вы когда-нибудь задумывались, можете ли вы использовать Google Таблицы в качестве бесплатной базы данных? Как вы думаете, можно ли интегрировать Google Таблицы в качестве базы данных в свои веб-службы, не покупая традиционную базу данных? Если ответ на поставленные выше вопросы утвердительный, значит, вы попали в нужное место.
В этом сообщении блога мы стремимся обсудить, как мы можем преобразовать и использовать Google Таблицы в качестве базы данных. Вот краткое описание того, что вы расскажете в этом посте.
Hevo предлагает более быстрый способ перемещения данных из баз данных или приложений SaaS в ваше хранилище данных для визуализации в инструменте бизнес-аналитики. Hevo полностью автоматизирован и, следовательно, не требует программирования.
Ознакомьтесь с некоторыми интересными функциями Hevo:
- Полностью автоматизированная: Платформа Hevo может быть установлена всего за несколько минут и требует минимального обслуживания.
- Передача данных в реальном времени: Hevo обеспечивает миграцию данных в реальном времени, поэтому вы всегда можете иметь готовые для анализа данные.
- 100% полная и точная передача данных: Надежная инфраструктура Hevo обеспечивает надежную передачу данных с нулевой потерей данных.
- Масштабируемая инфраструктура: Hevo имеет встроенную интеграцию для более чем 100 источников, которые могут помочь вам масштабировать инфраструктуру данных по мере необходимости.
- Круглосуточная поддержка в режиме реального времени: Команда Hevo доступна круглосуточно, чтобы оказать вам исключительную поддержку через чат, электронную почту и звонки в службу поддержки.
- Управление схемой: Hevo снимает утомительную задачу управления схемой и автоматически определяет схему входящих данных и сопоставляет ее со схемой назначения.
- Мониторинг в реальном времени: Hevo позволяет отслеживать поток данных, чтобы вы могли проверить, где находятся ваши данные в определенный момент времени.

Вы можете попробовать Hevo бесплатно, подписавшись на 14-дневную бесплатную пробную версию.
Введение в Google Таблицы
Google Таблицы — это продукт Google, который предоставляет возможность создания электронных таблиц в облаке. Google Таблицы очень похожи на приложение для работы с электронными таблицами, но на стероидах. Благодаря облачной платформе он предоставляет больше функциональных возможностей по сравнению со стандартной электронной таблицей.
Google Таблицы очень похожи на приложение для работы с электронными таблицами, но на стероидах. Благодаря облачной платформе он предоставляет больше функциональных возможностей по сравнению со стандартной электронной таблицей.
Некоторые из основных функций Google Таблиц: —
- Поскольку это веб-интерфейс, вы можете получить доступ к данным, хранящимся в Таблицах, из любого места через Интернет.
- Все ведущие операционные системы устройств имеют интегрированное приложение для Google Таблиц, которое обеспечивает удобство работы.
- Его можно использовать бесплатно, и он идет в комплекте с вашей учетной записью Gmail.Вам не нужно выкладывать ни копейки, чтобы использовать Google Таблицы.
- Google Таблицы очень похожи на Microsoft Excel, и если вы работали с Excel, Google Таблицы не будут проблемой.
- Google Таблицы позволяет загружать подключаемый модуль, надстройки и собственный код для эффективного анализа данных в электронных таблицах.

Введение в базы данных
База данных — это набор данных в строках и столбцах. База данных контролирует и организует структурированную информацию данных с помощью системы управления базами данных (СУБД).База данных позволяет легко получать доступ, отслеживать, систематизировать и управлять данными.
Большое количество баз данных использует язык структурированных запросов (SQL) для записи и запроса данных.
Некоторые популярные базы данных —
- MySQL
- PostgreSQL
- SQL Server
- MongoDB (база данных NoSQL)
Таблицы Google как база данных
Google Таблицы — это очень продвинутая форма электронной таблицы со многими готовыми возможностями.Поскольку это облачное приложение, вы также можете использовать их в качестве базы данных для своего небольшого приложения или веб-сайтов. Вы можете легко отказаться от дорогих БД, таких как MySQL, PostgreSQL и т. Д., И использовать Google Таблицы для хранения данных и управления ими в режиме реального времени. Мы не говорим, что Google Таблицы исключают использование БД, но для небольших наборов данных это можно рассматривать как вариант.
Мы не говорим, что Google Таблицы исключают использование БД, но для небольших наборов данных это можно рассматривать как вариант.
Давайте посмотрим, как можно использовать Google Таблицы в качестве базы данных.
Предварительные требования
- Аккаунт Google Cloud Platform
- Python 3.6 или новее
- Базовое понимание языков программирования и данных Excel.
Включить проект в Google Cloud Console
- Зайдите в Google API Manager и создайте новый проект.
- Добавить в проект Google Drive API . Это необходимо для доступа к электронным таблицам, хранящимся на Google Диске.
- Сгенерируйте учетные данные, которые будут использоваться для аутентификации запроса, который будет сгенерирован программой Python.
- Сохраните сгенерированный ключ JSON на локальном компьютере с именем keys.json.
- Откройте сгенерированный ключ в текстовом редакторе и скопируйте адрес электронной почты, указанный в свойстве client_email .
- Создайте лист под названием «Учебник» и добавьте данные для начала.
- Предоставьте доступ к электронной таблице по указанному выше адресу электронной почты. Это позволит получить доступ к электронной таблице из API.

Подключение к электронной таблице через Python
- Откройте вашу любимую Python IDE и установите следующие пакеты —
pip install gspread oauth3client - Создайте файл с именем googleSheetToPython.py и напишите следующие строки кода.
# импорт библиотеки
импортное распространение
# Учетные данные клиента службы от oauth3client
из oauth3client.service_account импорт ServiceAccountCredentials
# Печатайте красиво
импортный отпечаток
#Create scope
scope = ['https://spreadsheets.google.com/feeds']
# создать учетные данные, используя эту область и содержимое keys.json
creds = ServiceAccountCredentials.from_json_keyfile_name (keys. json ', область действия)
#create gspread авторизуйтесь с использованием этих учетных данных
client = gspread.авторизовать (кредиты)
# Теперь будет доступ к нашим таблицам Google, которые мы называем client.open в StartupName
sheet = client.open ('Учебник'). sheet1
pp = pprint.PrettyPrinter ()
# Доступ ко всей записи внутри этого
результат = sheet.get_all_record ()  json ', область действия)
#create gspread авторизуйтесь с использованием этих учетных данных
client = gspread.авторизовать (кредиты)
# Теперь будет доступ к нашим таблицам Google, которые мы называем client.open в StartupName
sheet = client.open ('Учебник'). sheet1
pp = pprint.PrettyPrinter ()
# Доступ ко всей записи внутри этого
результат = sheet.get_all_record ()
json ', область действия)
#create gspread авторизуйтесь с использованием этих учетных данных
client = gspread.авторизовать (кредиты)
# Теперь будет доступ к нашим таблицам Google, которые мы называем client.open в StartupName
sheet = client.open ('Учебник'). sheet1
pp = pprint.PrettyPrinter ()
# Доступ ко всей записи внутри этого
результат = sheet.get_all_record () - После настройки вышеуказанных учетных данных вы можете использовать API для подключения к своей электронной таблице и выполнения операции CRUD (создание, чтение, обновление, удаление) в таблицах Google.
- Под кодом Python, помогает читать данные из Google Sheet —
result = sheet.row_values (5) # Просмотреть отдельную строку
result_col = sheet.col.values (5) # Просмотреть отдельный столбец
result_cell = sheet.cell (5,2) # Посмотреть конкретную ячейку
pp = pprint.PrettyPrinter () - Обновить значения на листе
#update values
sheet. update_cell (2,9, '500000') # Изменить значение в ячейке (2,9) на листе
результат = sheet.cell (2,9)
pp.pprint (результат)  update_cell (2,9, '500000') # Изменить значение в ячейке (2,9) на листе
результат = sheet.cell (2,9)
pp.pprint (результат)
update_cell (2,9, '500000') # Изменить значение в ячейке (2,9) на листе
результат = sheet.cell (2,9)
pp.pprint (результат) Ограничения использования Google Таблиц в качестве базы данных
Google Таблицы предлагают пользователям отличные функции для управления и анализа ваших данных.Однако он не может исключить использование стандартных баз данных. Обратите внимание на некоторые ограничения, с которыми вы можете столкнуться при использовании Google Таблиц в качестве базы данных.
- Not Fault Tolerant — Хотя Google Таблицы доступны в облаке, они не так устойчивы к сбоям, как стандартная база данных. Если какой-либо пользователь удалит электронную таблицу, все данные будут потеряны. В то время как в случае стандартной базы данных данные реплицируются на несколько узлов и, следовательно, обеспечивают гораздо более отказоустойчивые системы.
- Ограничение хранилища — Google Таблицы могут хранить только до 5 миллионов записей. На первый взгляд это может показаться значительным числом, но этого недостаточно для средних и крупных приложений.
 На первый взгляд это может показаться значительным числом, но этого недостаточно для средних и крупных приложений.
На первый взгляд это может показаться значительным числом, но этого недостаточно для средних и крупных приложений.- Отсутствующие функции базы данных — Google Таблицы в качестве базы данных не предоставляют такие функции базы данных, как запросы, поиск, объединения, согласованность. Не существует стандартного API, позволяющего выполнять плавные соединения. Для выполнения этих задач всегда нужно писать сложные программы
Заключение
Из этого сообщения в блоге вы узнали о Google Таблицах и их функциях, а также о том, как вы можете использовать Google Таблицы в качестве базы данных.Однако Google Sheet не может заменить стандартную базу данных, так как в ней отсутствуют определенные функции.
Если вы ищете альтернативу, мы рекомендуем вам попробовать Hevo Data, конвейер данных без кода, который поможет вам передавать данные из выбранного вами источника полностью автоматизированным и безопасным способом без необходимости повторного написания кода. Hevo, с его безопасной интеграцией с более чем 100 источниками и инструментами бизнес-аналитики, позволяет вам экспортировать, загружать, преобразовывать и обогащать ваши данные и делать их готовыми к анализу в мгновение ока.
Hevo, с его безопасной интеграцией с более чем 100 источниками и инструментами бизнес-аналитики, позволяет вам экспортировать, загружать, преобразовывать и обогащать ваши данные и делать их готовыми к анализу в мгновение ока.
Если вам интересно, вы можете сначала бесплатно попробовать Hevo. Подпишитесь на 14-дневную бесплатную пробную версию!
Что вы думаете об использовании Google Таблиц в качестве базы данных? Делитесь с нами в комментариях!
Конвейер данных без кода для вашего хранилища данных
.