Как работает синтезатор речи: Синтезатор речи Google на смартфоне — что это и как работает?
Синтезатор речи Google на смартфоне — что это и как работает?
Как включить синтезатор речи Google на телефоне для озвучивания текстов?
Разработчики операционной системы Android предусмотрели возможность преобразования практически любого текста в речь. Такая опция позволит читать сообщения или статьи на разнообразных сайтах — для этого нужно запустить воспроизведение, отрегулировать громкость и положить телефон на стол, чтобы освободить руки. В результате можно сэкономить массу времени, раньше затрачиваемого на самостоятельное чтение. Также озвучивание текстов пригодится слабовидящим людям, которым проблематично разглядеть мелкий шрифт на экране смартфона.
Рассматриваемая функция неизвестна многим пользователям телефонов, поскольку «спрятана» глубоко в настройках. Давайте рассмотрим последовательность действий, необходимых для включения опции.
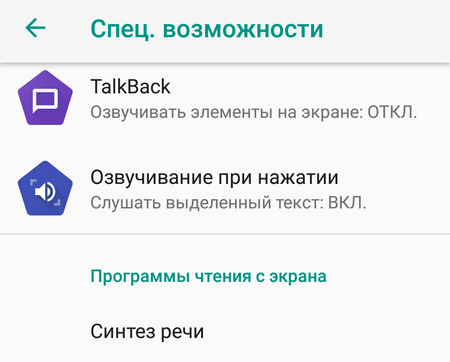
Откройте «Настройки» смартфона и найдите раздел «Специальные возможности». Он часто находится в «Расширенных настройках», но лучше всего воспользоваться поиском.
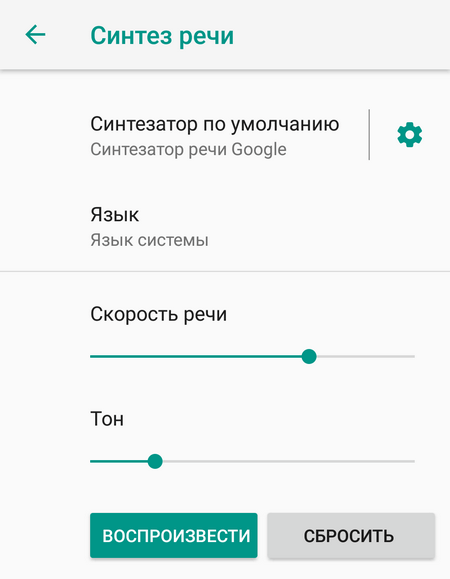
Далее нужно выбрать пункт «Синтез речи». По умолчанию здесь включен «Синтезатор речи Google». Перед использованием преобразователя рекомендуется подобрать оптимальные параметры, например, отрегулировать скорость речи. При желании можно прослушать пример, нажав соответствующую кнопку.
После изменения параметров вернитесь в раздел «Специальные возможности» и включите «Озвучивание при нажатии».
Если соответствующего пункта нет, установите утилиту Android Accessibility Suite из каталога Google Play.
После выполненных действий поверх всех приложений появится небольшой круглый значок с изображением диалогового окна. Если нажать на кнопку, программа предложит выделить область экрана, с которой нужно прочитать текст экране. Внизу появится небольшая панель с несколькими управляющими кнопками, благодаря которым можно быстро переходить на озвучивание предыдущих/следующих текстов или ставить воспроизведение на паузу.
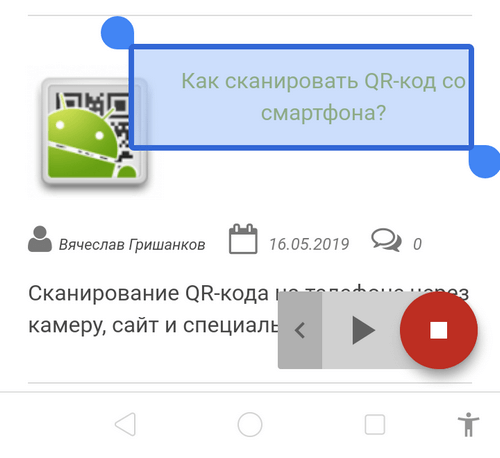
К сожалению, по каким-то причинам синтезатор речи Google не работает на некоторых смартфонах — иконка для воспроизведения текста просто не появляется. Во многих случаях эта кнопка отображается в нижнем меню с навигационными кнопками (как на скриншоте выше).
За счет простого управления и минимума настроек с синтезатором речи Google разберется любой владелец телефона. Дополнительное достоинство — высокое качество преобразования текста в речь и абсолютная бесплатность технологии.
 Загрузка…
Загрузка…
Что такое синтезаторы речи? Лучшие синтезаторы речи :: SYL.ru
Речевые синтезаторы, установленные на компьютеры или мобильные устройства, уже не кажутся такими необычными программами, как раньше. Благодаря современным технологиям обычный настольный ПК может воспроизводить человеческий голос.
Каким образом работают синтезаторы речи? Где они применяются? Какой самый лучший речевой синтезатор? Ответы на эти и другие вопросы изложены в данной статье.
Общее понятие
Синтезаторы речи являются специальными программами, состоящими из некоторого количества модулей, которые предоставляют возможность перевести набранные тексты в озвученные человеческим голосом предложения. Не стоит думать, что вся база слов и фраз записана реальными людьми в профессиональных студиях. Выполнить подобную задачу физически невозможно. Библиотеку с таким большим количеством фраз нельзя установить ни на один современный компьютер, не говоря уже о мобильных телефонах. Для этого разработчики создали технологию Text-to-Speech.
Сфера применения
Синтезаторы речи используются при изучении иностранных языков, прослушивании текстов на страницах книг, создании вокальных партий, выдаче поисковых запросов в форме озвученных фраз и т. п.
Какие разновидности программ существуют? В зависимости от сферы применения утилиты можно разделить на 2 вида: обычные, преобразующие набранный текст в речь, и специальные вокальные модули, используемые в музыкальных приложениях.
Для лучшего понимания рекомендуется рассмотреть оба класса, однако стоит акцентировать внимание на программах в их непосредственном значении.
Преимущества и недостатки
На данный момент компьютер синтезирует человеческую речь только приблизительно. В простейших программах можно наблюдать проблемы со звуком и правильной постановкой ударений в различных словах. Синтезаторы речи, установленные на мобильные устройства, расходуют много энергии. Нередко можно отметить несанкционированную загрузку дополнительных модулей.
К преимуществам следует отнести удобство восприятия. Многим пользователям гораздо проще усваивать звуковую информацию, нежели какую-либо другую.

Лучшие речевые синтезаторы с русскими голосами
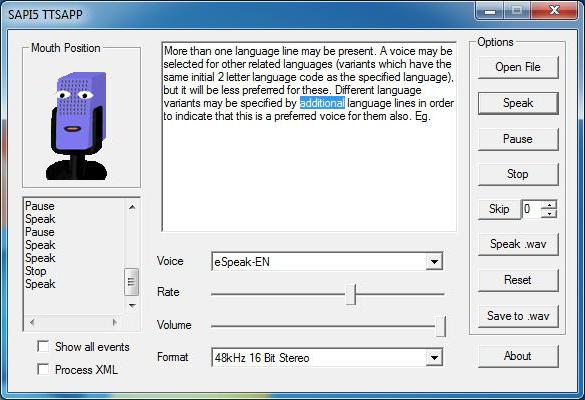
Программа RHVoice была создана Ольгой Яковлевой. Стандартный вариант приложения включает 3 голоса. Настройки очень просты. Программу можно использовать и как самостоятельное приложение, совместимое с SAPI5, и как дополнительный экранный модуль.
Речевой синтезатор Acapela отличается от аналогов идеальным озвучиванием текста. Приложение поддерживает более 30 языков мира. В бесплатной версии доступен лишь 1 женский голос.
Программа Vocalizer часто применяется в call-центрах. Пользователь может настроить постановку ударения, громкость и скорость чтения. При необходимости загружаются дополнительные словари. В приложении есть 1 женский голос. Речевой движок автоматически встраивается в программы для чтения книг в электронном формате.
Утилита eSpeak поддерживает свыше 50 языков. Недостатком программы можно считать сохранение звуковых файлов лишь в формате WAV, который требует много места на жестком диске.
Приложение Festival является мощнейшей утилитой синтеза речи, поддерживающей даже финский язык и хинди.

Установка программы
Как использовать приложения такого типа? Для начала нужно установить программу. В компьютерных ОС применяется стандартный инсталлятор, в котором пользователю остается выбрать лишь поддерживаемый утилитой языковой модуль. Установщик для мобильных устройств можно скачать с официального сайта, Google Play, а также App Store. Инсталляция приложения происходит в автоматическом режиме.
Первый запуск программы
На данном этапе пользователю достаточно установить язык по умолчанию. Иногда требуется отметить качество звучания. Стандартный вариант подразумевает частоту дискретизации 4410 Гц, глубину 16 бит и битрейт 128 кбит/с. В мобильных ОС показатели могут быть ниже. В качестве основы используется определенный голос.
Фильтры и эквалайзеры помогают достичь необходимого звучания. Пользователю доступны три варианта перевода текста. Он может набрать на клавиатуре предложения, включить озвучивание уже имеющегося файла или установить в браузере расширение, которое преобразует содержимое на веб-страницах в речь. Достаточно отметить необходимый вариант действий, тембр голоса и язык, на котором будет произноситься текст. Для включения процесса воспроизведения требуется кликнуть по кнопке «Старт».

Работа со сложными программами
В музыкальных приложениях настройки гораздо сложнее. В речевом модуле программы FL Studio пользователь может выбрать несколько видов голосов, а также указать тональность и скорость воспроизведения. Постановка ударений перед слогами осуществляется с помощью символа «_». С помощью подобного речевого синтезатора можно создать лишь роботизированный голос.
Программа Vocaloid относится к приложениям профессионального типа. Помимо обычных параметров, пользователь может выбирать артикуляцию и глиссандо. В утилите есть база с вокалом профессионалов. При желании можно подгонять под ноты целые предложения. Одна только библиотека с вокалом занимает более 4 Гб в сжатом виде.
«Синтезатор речи Google»: что это за программа
В мае 2014 года компания предоставила пользователям возможность опробовать новый бесплатный продукт. Что такое «Синтезатор речи Google» на «Андроиде»? Это программа, озвучивающая текст на экране мобильного устройства или планшета. Теперь нет необходимости устанавливать сторонние утилиты, которые требуют наличия лицензии. «Синтезатор речи Google» используется при чтении электронных книг, прослушивании правильного произношения слов, запуске приложения TalkBack.
Новая версия программы «Синтезатор речи Google 3.1» получила функцию поддержки английского, итальянского, испанского, корейского, немецкого, нидерландского, польского, португальского, русского и французского языков. Где найти голосовые пакеты? Они загружаются из самого приложения.

Преимущества и недостатки продукта от Google
Особенностями русскоговорящего женского голоса является четкое, громкое звучание и плавная интонация. Скорость воспроизведения можно регулировать в настройках программы. Пользователи, использующие TalkBack и русскую языковую локализацию ОС Android, должны проявлять осторожность при переключении на речевой синтезатор, если ранее в приложении по умолчанию был установлен другой голос. Могут возникнуть проблемы, связанные с сохранением контроля над мобильным устройством на слух. Практически все голоса, кроме русского, неспособны обрабатывать предложения на кириллице.
Среди минусов можно отметить задержку реакции на чтение текстов, состоящих из фраз на разных языках. Русский голос отличается металлическими нотками тембра. Можно услышать дребезжащий звук на низких частотах. К преимуществам можно отнести стабильность работы приложения и приемлемое качество чтения англоязычных слов.
«Синтезатор речи Google»: как пользоваться программой
Для того чтобы утилита заработала как надо, требуется обновить ее до последней версии. Чтобы активировать процесс озвучивания текста, нужно открыть настройки. В разделе «язык и ввод» необходимо поставить флажок на пункте «синтез речи». Тут же следует отметить строку «система по умолчанию». Не стоит забывать о том, что голосовые пакеты в самой программе также нуждаются в обновлении.

Проблемы при работе с утилитой
При необходимости пользователь может отключить приложение. В самых простых утилитах кнопка остановки находится в самой программе. Деактивация расширения, установленного в браузере, производится путем отключения дополнения или полного удаления плагина. При работе с программой на мобильном телефоне также могут возникнуть проблемы. Дело в том, что синтезатор речи автоматически включает загрузку ненужных пользователю языковых модулей.
Данный процесс занимает много времени и существенно расходует трафик. Как отключить «Синтезатор речи Google» на мобильном устройстве и избавиться от этой проблемы? Для начала нужно открыть настройки приложения. Потом необходимо выбрать раздел «язык и голосовой ввод». Далее нужно отметить последнюю строку.
Выбрав голосовой поиск, следует кликнуть по крестику у пункта «распознавание речи офлайн». Затем рекомендуется удалить кэш приложений. Далее требуется перезагрузить мобильный телефон. Чтобы полностью отключить утилиту, необходимо открыть в настройках раздел «приложения», выбрать в списке синтезатор речи и кликнуть по кнопке «остановить».
Удаление программы
Бывает так, что пользователь вообще не использует «Синтезатор речи Google». Можно ли удалить утилиту с мобильного устройства? Для этого нужно открыть Google Play. Затем следует выбрать в перечне установленных программ синтезатор речи и кликнуть по кнопке «удалить».

Итоги
Обычным пользователям и людям с ограниченными возможностями подойдут приложения с простым интерфейсом. Это может быть как RHVoice, так и «Синтезатор речи Google». Русский голос озвучит отображаемый на экране текст. Большего рядовому пользователю не требуется.
Музыкантам рекомендуется отдавать предпочтение профессиональной программе Vocaloid. В приложении есть дополнительные голосовые библиотеки и множество различных опций. Программа позволит получить естественное звучание голоса. Ведь музыкантам так важно, чтобы компьютерный синтез не ощущался на слух.
Синтезатор речи Google на смартфоне — что это и как работает?
| itemprop=’image’ src=’https://trashbox.ru/apk_icons/1137140_192.png’ class=image_microdata> | >IvS2, 16 октября 2019 — 09:50 |
Android 5.0+ Другие версии Синтезатор речи Google озвучивает текст, который виден на экране устройства. Он используется во многих приложениях. Telegram-каналсоздателяТрешбоксапро технологии
- В Google Play Книгах можно пользоваться функцией «Чтение вслух».
- В Google Переводчике можно слушать произношение слов.
- При использовании TalkBack и других специальных возможностей озвучиваются ваши действия.
- Также в Play Маркете есть много других приложений, в которых применяется синтез речи.
Включить Синтезатор речи Google можно в разделе «Настройки > Язык и ввод > Синтез речи». Если он уже включен, здесь его можно обновить. Поддерживаемые языки: английский (Великобритания), английский (Индия), английский (США), итальянский, испанский (Испания), испанский (США), корейский, немецкий, нидерландский, польский, португальский (Бразилия), русский, французский и японский. Telegram-каналпро технологиис инсайдамии розыгрышами Чтобы увидеть более ранние версии, войдите на сайт Последнее изменение: 3 декабря 2019 — 16:29
Разработчики операционной системы Android предусмотрели возможность преобразования практически любого текста в речь. Такая опция позволит читать сообщения или статьи на разнообразных сайтах — для этого нужно запустить воспроизведение, отрегулировать громкость и положить телефон на стол, чтобы освободить руки. В результате можно сэкономить массу времени, раньше затрачиваемого на самостоятельное чтение. Также озвучивание текстов пригодится слабовидящим людям, которым проблематично разглядеть мелкий шрифт на экране смартфона.
Рассматриваемая функция неизвестна многим пользователям телефонов, поскольку «спрятана» глубоко в настройках. Давайте рассмотрим последовательность действий, необходимых для включения опции.
Откройте «Настройки» смартфона и найдите раздел «Специальные возможности». Он часто находится в «Расширенных настройках», но лучше всего воспользоваться поиском.
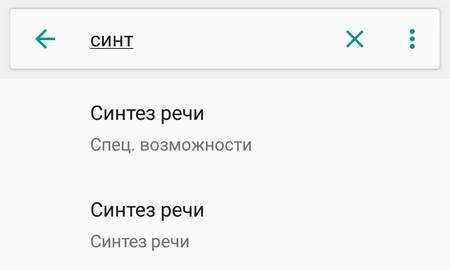
Далее нужно выбрать пункт «Синтез речи». По умолчанию здесь включен «Синтезатор речи Google». Перед использованием преобразователя рекомендуется подобрать оптимальные параметры, например, отрегулировать скорость речи. При желании можно прослушать пример, нажав соответствующую кнопку.
После изменения параметров вернитесь в раздел «Специальные возможности» и включите «Озвучивание при нажатии».
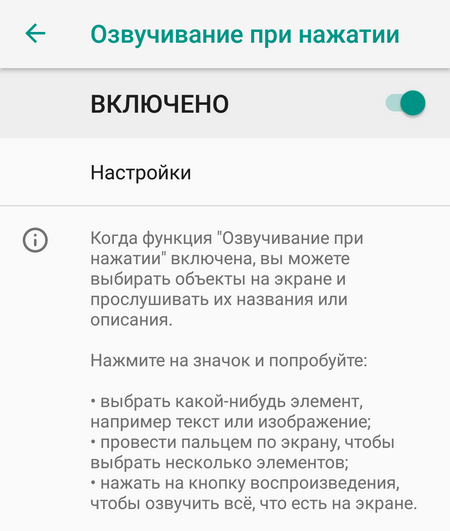
Если соответствующего пункта нет, установите утилиту Android Accessibility Suite из каталога Google Play.
После выполненных действий поверх всех приложений появится небольшой круглый значок с изображением диалогового окна. Если нажать на кнопку, программа предложит выделить область экрана, с которой нужно прочитать текст экране. Внизу появится небольшая панель с несколькими управляющими кнопками, благодаря которым можно быстро переходить на озвучивание предыдущих/следующих текстов или ставить воспроизведение на паузу.
К сожалению, по каким-то причинам синтезатор речи Google не работает на некоторых смартфонах — иконка для воспроизведения текста просто не появляется. Во многих случаях эта кнопка отображается в нижнем меню с навигационными кнопками (как на скриншоте выше).
За счет простого управления и минимума настроек с синтезатором речи Google разберется любой владелец телефона. Дополнительное достоинство — высокое качество преобразования текста в речь и абсолютная бесплатность технологии.
Приложения-синтезаторы речи – удобные и надежные помощники для Андроид пользователей. С их помощью можно «озвучить» приложения на самые популярные языки мира, настроить тембр голоса и другие важные параметры, а также учить языки, прослушивать звучание разных слов. Большинство TTS приложений для Android доступны бесплатно, однако за установку отдельных голосов и функций нужно доплатить. Мы подобрали для вас наиболее удобные синтезаторы речи, скачать которые можно на нашем сайте.
Синтез речи от Google
Жанр | Инструменты |
|---|---|
| Рейтинг | 4,1 |
| Установки | 1 000 000 000–5 000 000 000 |
| Разработчик | Google LLC |
| Русский язык | есть |
| Оценок | 1 107 289 |
| Версия | 3.14.9 |
| Размер apk | 14.7 MB |


Наиболее популярная и доступная TTS-утилита, совместимая со многими Андроид-девайсами. С помощью программы вы можете озвучивать текст на экране, а также выполнять ряд важных функций:
- Озвучивать книги приложения Google Play Книги.
- Переводить и озвучивать слова из Google Переводчика.
- Включать голосовые подсказки при помощи сервиса TalkBack.
Активировать приложение Синтез речи от Google можно прямо на своем девайсе. Для этого откройте пункт меню «Настройки», где зайдите в подраздел «Язык и методы ввода», а там – «Синтез речи». Выберите систему синтеза речи от Google, после чего приложение активируется автоматически.
Программа поддерживает более 40 языков, среди которых английский, русский, французский, немецкий, японский, испанский, датский, хинди и много других. В последней версии утилиты добавлено 3 новые языка – румынский, эстонский и словацкий, а также улучшено качество голоса в целом.
Acapela TTS Voices
Жанр | Связь |
|---|---|
| Рейтинг | 3,5 |
| Установки | 100 000–500 000 |
| Разработчик | Acapela Group S.A. |
| Русский язык | нет |
| Оценок | 3 883 |
| Версия | 6.0.0.2 |
| Размер apk | 9.3 MB |
Еще один качественный синтезатор речи на Андроид, который доступен на нашем портале. Программа является условно бесплатной, при этом перед тем, как купить приложение, вы можете прослушать демо-версии мужских и женских голосов в режиме онлайн. Утилита позволяет покупать и устанавливать программы с голосом высокого качества, такие как Google TalkBack, переводчики приложений для чтения книг и озвучивания новостей.
Для выбора и установки голоса в приложении войдите в меню, после чего нажмите на голос и удерживайте несколько секунд. Возле выбранного голоса появится значок желтой звезды, и он будет установлен по умолчанию. Теперь вы можете использовать эту программу с вашей любимой читалкой книг.
Приложение Acapela TTS Voices можно активировать следующими действиями.
- Загрузите сервис на нашем сайте или портале Google Play.
- После установки приложения кликните на иконку программы. Убедитесь в наличии Интернет-соединения.
- Ознакомьтесь со списком голосов, которые загружены с сервера.
- Нажмите на меню напротив каждого голоса, где можно прослушать собственный текст или сразу перейти к покупке.
- После покупки и оплаты голос будет загружен, и вы сможете пользоваться им в любое время.
Приложение Acapela TTS Voices совместимо с ОС Android 2.2 и более поздними версиями.
Vocalizer TTS Voice
Жанр | Работа |
|---|---|
| Рейтинг | 3,3 |
| Установки | 500 000–1 000 000 |
| Разработчик | Code Factory |
| Русский язык | есть |
| Оценок | 3 405 |
| Версия | 2.0.8 |
| Размер apk | 5.4 MB |
Синтезатор речи с меню на английском языке. Программа обладает интегрированным TTS-движком, поддерживающим более 50 языков. Сервис выгодно выделяется приятным и чистым звуком, тембр которого можно настраивать на свое усмотрение.
Vocalizer позволяет озвучить популярные Андроид-приложения, такие как книги, приложения для навигации по GPS, переводчики и реабилитационное программное обеспечение.
Среди других важных функций Vocalizer TTS Voice стоит отметить:
- Поддержка 50 языков и 100 видов голоса.
- Поддержка эмоцзи (а вы знали, что есть клавиатуры с поддержкой эмодзи?).
- Озвучивание слов в словарях.
- Настройки скорости чтения.
- Настройки озвучивания пунктуации.
После того, как программа будет установлена на вашем устройстве, вы можете активировать ее через меню настроек в разделе «Язык и методы ввода» – Text-To-Speech и установить Vocalizer TTS как систему по умолчанию.
Приложение совместимо с системой Android версии 4.0 и далее.
Если вам понравилось это приложение, и вы ищете похожие приложения – посмотрите обзор приложений для записи телефонных разговоров. А если вы в незнакомой стране, и вам не до озвучки текста, вам нужно перевести этот текст – вы можете сфотографировать его и перевести фотопереводчиком на Андроид.
Речевые синтезаторы, установленные на компьютеры или мобильные устройства, уже не кажутся такими необычными программами, как раньше. Благодаря современным технологиям обычный настольный ПК может воспроизводить человеческий голос.
Каким образом работают синтезаторы речи? Где они применяются? Какой самый лучший речевой синтезатор? Ответы на эти и другие вопросы изложены в данной статье.
Общее понятие
Синтезаторы речи являются специальными программами, состоящими из некоторого количества модулей, которые предоставляют возможность перевести набранные тексты в озвученные человеческим голосом предложения. Не стоит думать, что вся база слов и фраз записана реальными людьми в профессиональных студиях. Выполнить подобную задачу физически невозможно. Библиотеку с таким большим количеством фраз нельзя установить ни на один современный компьютер, не говоря уже о мобильных телефонах. Для этого разработчики создали технологию Text-to-Speech.
Сфера применения
Синтезаторы речи используются при изучении иностранных языков, прослушивании текстов на страницах книг, создании вокальных партий, выдаче поисковых запросов в форме озвученных фраз и т. п.
Какие разновидности программ существуют? В зависимости от сферы применения утилиты можно разделить на 2 вида: обычные, преобразующие набранный текст в речь, и специальные вокальные модули, используемые в музыкальных приложениях.
Для лучшего понимания рекомендуется рассмотреть оба класса, однако стоит акцентировать внимание на программах в их непосредственном значении.
Преимущества и недостатки
На данный момент компьютер синтезирует человеческую речь только приблизительно. В простейших программах можно наблюдать проблемы со звуком и правильной постановкой ударений в различных словах. Синтезаторы речи, установленные на мобильные устройства, расходуют много энергии. Нередко можно отметить несанкционированную загрузку дополнительных модулей.
К преимуществам следует отнести удобство восприятия. Многим пользователям гораздо проще усваивать звуковую информацию, нежели какую-либо другую.
Лучшие речевые синтезаторы с русскими голосами
Программа RHVoice была создана Ольгой Яковлевой. Стандартный вариант приложения включает 3 голоса. Настройки очень просты. Программу можно использовать и как самостоятельное приложение, совместимое с SAPI5, и как дополнительный экранный модуль.
Речевой синтезатор Acapela отличается от аналогов идеальным озвучиванием текста. Приложение поддерживает более 30 языков мира. В бесплатной версии доступен лишь 1 женский голос.
Программа Vocalizer часто применяется в call-центрах. Пользователь может настроить постановку ударения, громкость и скорость чтения. При необходимости загружаются дополнительные словари. В приложении есть 1 женский голос. Речевой движок автоматически встраивается в программы для чтения книг в электронном формате.
Утилита eSpeak поддерживает свыше 50 языков. Недостатком программы можно считать сохранение звуковых файлов лишь в формате WAV, который требует много места на жестком диске.
Приложение Festival является мощнейшей утилитой синтеза речи, поддерживающей даже финский язык и хинди.
Установка программы
Как использовать приложения такого типа? Для начала нужно установить программу. В компьютерных ОС применяется стандартный инсталлятор, в котором пользователю остается выбрать лишь поддерживаемый утилитой языковой модуль. Установщик для мобильных устройств можно скачать с официального сайта, Google Play, а также App Store. Инсталляция приложения происходит в автоматическом режиме.
Первый запуск программы
На данном этапе пользователю достаточно установить язык по умолчанию. Иногда требуется отметить качество звучания. Стандартный вариант подразумевает частоту дискретизации 4410 Гц, глубину 16 бит и битрейт 128 кбит/с. В мобильных ОС показатели могут быть ниже. В качестве основы используется определенный голос.
Фильтры и эквалайзеры помогают достичь необходимого звучания. Пользователю доступны три варианта перевода текста. Он может набрать на клавиатуре предложения, включить озвучивание уже имеющегося файла или установить в браузере расширение, которое преобразует содержимое на веб-страницах в речь. Достаточно отметить необходимый вариант действий, тембр голоса и язык, на котором будет произноситься текст. Для включения процесса воспроизведения требуется кликнуть по кнопке «Старт».
Работа со сложными программами
В музыкальных приложениях настройки гораздо сложнее. В речевом модуле программы FL Studio пользователь может выбрать несколько видов голосов, а также указать тональность и скорость воспроизведения. Постановка ударений перед слогами осуществляется с помощью символа «_». С помощью подобного речевого синтезатора можно создать лишь роботизированный голос.
Программа Vocaloid относится к приложениям профессионального типа. Помимо обычных параметров, пользователь может выбирать артикуляцию и глиссандо. В утилите есть база с вокалом профессионалов. При желании можно подгонять под ноты целые предложения. Одна только библиотека с вокалом занимает более 4 Гб в сжатом виде.
«Синтезатор речи Google»: что это за программа
В мае 2014 года компания предоставила пользователям возможность опробовать новый бесплатный продукт. Что такое «Синтезатор речи Google» на «Андроиде»? Это программа, озвучивающая текст на экране мобильного устройства или планшета. Теперь нет необходимости устанавливать сторонние утилиты, которые требуют наличия лицензии. «Синтезатор речи Google» используется при чтении электронных книг, прослушивании правильного произношения слов, запуске приложения TalkBack.
Новая версия программы «Синтезатор речи Google 3.1» получила функцию поддержки английского, итальянского, испанского, корейского, немецкого, нидерландского, польского, португальского, русского и французского языков. Где найти голосовые пакеты? Они загружаются из самого приложения.
Преимущества и недостатки продукта от Google
Особенностями русскоговорящего женского голоса является четкое, громкое звучание и плавная интонация. Скорость воспроизведения можно регулировать в настройках программы. Пользователи, использующие TalkBack и русскую языковую локализацию ОС Android, должны проявлять осторожность при переключении на речевой синтезатор, если ранее в приложении по умолчанию был установлен другой голос. Могут возникнуть проблемы, связанные с сохранением контроля над мобильным устройством на слух. Практически все голоса, кроме русского, неспособны обрабатывать предложения на кириллице.
Среди минусов можно отметить задержку реакции на чтение текстов, состоящих из фраз на разных языках. Русский голос отличается металлическими нотками тембра. Можно услышать дребезжащий звук на низких частотах. К преимуществам можно отнести стабильность работы приложения и приемлемое качество чтения англоязычных слов.
«Синтезатор речи Google»: как пользоваться программой
Для того чтобы утилита заработала как надо, требуется обновить ее до последней версии. Чтобы активировать процесс озвучивания текста, нужно открыть настройки. В разделе «язык и ввод» необходимо поставить флажок на пункте «синтез речи». Тут же следует отметить строку «система по умолчанию». Не стоит забывать о том, что голосовые пакеты в самой программе также нуждаются в обновлении.
Проблемы при работе с утилитой
При необходимости пользователь может отключить приложение. В самых простых утилитах кнопка остановки находится в самой программе. Деактивация расширения, установленного в браузере, производится путем отключения дополнения или полного удаления плагина. При работе с программой на мобильном телефоне также могут возникнуть проблемы. Дело в том, что синтезатор речи автоматически включает загрузку ненужных пользователю языковых модулей.
Данный процесс занимает много времени и существенно расходует трафик. Как отключить «Синтезатор речи Google» на мобильном устройстве и избавиться от этой проблемы? Для начала нужно открыть настройки приложения. Потом необходимо выбрать раздел «язык и голосовой ввод». Далее нужно отметить последнюю строку.
Выбрав голосовой поиск, следует кликнуть по крестику у пункта «распознавание речи офлайн». Затем рекомендуется удалить кэш приложений. Далее требуется перезагрузить мобильный телефон. Чтобы полностью отключить утилиту, необходимо открыть в настройках раздел «приложения», выбрать в списке синтезатор речи и кликнуть по кнопке «остановить».
Удаление программы
Бывает так, что пользователь вообще не использует «Синтезатор речи Google». Можно ли удалить утилиту с мобильного устройства? Для этого нужно открыть Google Play. Затем следует выбрать в перечне установленных программ синтезатор речи и кликнуть по кнопке «удалить».
Итоги
Обычным пользователям и людям с ограниченными возможностями подойдут приложения с простым интерфейсом. Это может быть как RHVoice, так и «Синтезатор речи Google». Русский голос озвучит отображаемый на экране текст. Большего рядовому пользователю не требуется.
Музыкантам рекомендуется отдавать предпочтение профессиональной программе Vocaloid. В приложении есть дополнительные голосовые библиотеки и множество различных опций. Программа позволит получить естественное звучание голоса. Ведь музыкантам так важно, чтобы компьютерный синтез не ощущался на слух.
Похожие статьи
Google открыла доступ к собственной технологии перевода печатного текста в аудио. С помощью Google Cloud Platform создатели приложений могут использовать синтез речи для внедрения функций автоответчика и озвучивания любого текста.
Разработчикам предлагается выбор из 32 голосов и 12 языков. В настройках можно изменять тембр, скорость и громкость. Поддерживаются разные форматы аудио, включая MP3 и WAV.
Улучшенный синтез речи
Технология основана на обновленной версии WaveNet, поэтому команда проекта уверена в правильном звучании даже сложного текста. Благодаря облачному процессору Google TPU, искусственная речь генерируется в 1000 раз быстрее: одна секунда воспроизведенного текста создается за 50 миллисекунд. Для более естественного звучания качество звуковых фрагментов повышено с 8 до 16 бит.
Для оценки качества речи были привлечены добровольцы. Созданные системой WaveNet аудиозаписи получили в среднем 4,1 балла. Для сравнения, голос реального человека был оценен максимум на 4,59 балла из 5:
Оценка качества обычного синтезатора, WaveNet и человеческой речи
Стоимость сервиса зависит от объема работы: стандартная система озвучивания стоит 4 $ за каждый миллион озвученных символов, а WaveNet — 16 $. Подробнее о технологии можно узнать в документации.
У системы перевода печатного текста в аудио от Google есть серьезные конкуренты. В феврале 2018 года технология Baidu Deep Voice научилась менять женский голос на мужской.
Источник: блог Google Cloud Platform
Не смешно? А здесь смешно: @ithumor
Используемые источники:
- https://trashbox.ru/link/google-text-to-speech-android
- https://androidlime.ru/google-speech-synthesizer-on-smartphone
- https://gemapps.ru/sravnenie/obzor-sintezatorov-rechi-dlya-android
- https://www.syl.ru/article/298926/chto-takoe-sintezatoryi-rechi-luchshie-sintezatoryi-rechi
- https://tproger.ru/news/google-text-to-speech-for-all/
Предыдущая статьяSamsung Galaxy A5 2017 (SM-A520F) и его полные характеристикиСледующая статьяСкачать Переводчик Сканер камеры — PDF на андроид v.64.0
Обзор технологий синтеза речи / Блог компании Tinkoff / Хабр
Всем привет! Меня зовут Влад и я работаю data scientist-ом в команде речевых технологий Тинькофф, которые используются в нашем голосовом помощнике Олеге.
В этой статье я бы хотел сделать небольшой обзор технологий синтеза речи, использующихся в индустрии, и поделиться опытом нашей команды построения собственного движка синтеза.
Синтез речи
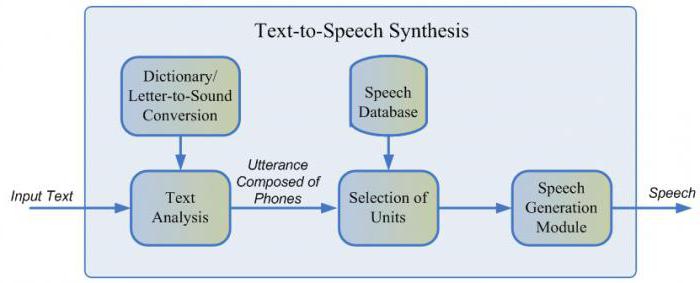
Синтез речи — это создание звука на основе текста. Эту задачу сегодня решают двумя подходами:
- Unit selection [1], или конкатенативный подход. Он основан на склейке фрагментов записанного аудио. С конца 90-х долгое время он считался де-факто стандартом для разработки движков синтеза речи. Например, голос, звучащий по методу unit selection, можно было встретить в Siri [2].
- Параметрический синтез речи [3], суть которого состоит в построении вероятностной модели, предсказывающей акустические свойства аудиосигнала для данного текста.
Речь моделей unit selection имеет высокое качество, низкую вариативность и требует большого объема данных для обучения. В то же время для тренировки параметрических моделей необходимо гораздо меньшее количество данных, они генерируют более разнообразные интонации, но до недавнего времени страдали от общего достаточно низкого качества звука по сравнению с подходом unit selection.
Однако с развитием технологий глубокого обучения модели параметрического синтеза достигли существенного прироста по всем метрикам качества и способны создавать речь, практически неотличимую от человеческой.
Метрики качества
Прежде чем говорить о том, какие модели синтеза речи лучше, нужно определить метрики качества, по которым будет проводиться сравнение алгоритмов.
Поскольку один и тот же текст можно прочитать бесконечным количеством способов, априори правильного способа для произношения конкретной фразы не существует. Поэтому зачастую метрики качества синтеза речи субъективны и зависят от восприятия слушающего.
Стандартная метрика — это MOS (mean opinion score), усредненная оценка естественности речи, выданная асессорами для синтезированных аудио по шкале от 1 до 5. Единица означает совсем неправдоподобное звучание, а пятерка — речь, неотличимую от человеческой. Реальные записи людей обычно получают значения примерно 4,5, и значение больше 4 считается достаточно высоким.
Как работает синтез речи
Первый шаг к построению любой системы синтеза речи — сбор данных для обучения. Обычно это аудиозаписи высокого качества, на которых диктор читает специально подобранные фразы. Примерный размер датасета, необходимый для обучения моделей unit selection, составляет 10—20 часов чистой речи [2], в то время как для нейросетевых параметрических методов верхняя оценка равна примерно 25 часам [4, 5].
Обсудим обе технологии синтеза.
Unit selection
Обычно записанная речь диктора не может покрыть всех возможных случаев, в которых будет использоваться синтез. Поэтому суть метода состоит в разбиении всей аудиобазы на небольшие фрагменты, называющиеся юнитами, которые затем склеиваются друг с другом с использованием минимальной постобработки. В качестве юнитов обычно выступают минимальные акустические единицы языка, такие как полуфоны или дифоны [2].
Весь процесс генерации состоит из двух этапов: NLP frontend, отвечающий за извлечение лингвистического представления текста, и backend, который вычисляет функцию штрафа юнитов для заданных лингвистических признаков. В NLP frontend входят:
- Задача нормализации текста — перевод всех небуквенных символов (цифр, знаков процентов, валют и так далее) в их словесное представление. Например, “5 %” должно быть переведено в “пять процентов”.
- Извлечение лингвистических признаков из нормализованного текста: фонемное представление, ударения, части речи и так далее.
Обычно NLP frontend реализован с помощью вручную прописанных правил для конкретного языка, однако в последнее время происходит все больший уклон в сторону использования моделей машинного обучения [7].
Штраф, оцениваемый backend-подсистемой, — это сумма target cost, или соответствия акустического представления юнита для конкретной фонемы, и concatenation cost, то есть уместности соединения двух соседних юнитов. Для оценки штраф функций можно использовать правила или уже обученную акустическую модель параметрического синтеза [2]. Выбор наиболее оптимальной последовательности юнитов с точки зрения выше определенных штрафов происходит с помощью алгоритма Витерби [1].
Примерные значения MOS моделей unit selection для английского языка: 3,7—4,1 [2, 4, 5].
Достоинства подхода unit selection:
- Естественность звучания.
- Высокая скорость генерации.
- Небольшой размер моделей — это позволяет использовать синтез прямо на мобильном устройстве.
Недостатки:
- Синтезируемая речь монотонна, не содержит эмоций.
- Характерные артефакты склейки.
- Требует достаточно большой тренировочной базы аудиоданных для покрытия всевозможных контекстов.
- В принципе не может генерировать звук, не встречающийся в обучающей выборке.
Параметрический синтез речи
В основе параметрического подхода лежит идея о построении вероятностной модели, оценивающей распределение акустических признаков заданного текста.
Процесс генерации речи в параметрическом синтезе можно разделить на четыре этапа:
- NLP frontend — такая же стадия предобработки данных, как и в подходе unit selection, результат которой — большое количество контекстно-зависимых лингвистических признаков.
- Duration model, предсказывающая длительность фонем.
- Акустическая модель, восстанавливающая распределение акустических признаков по лингвистическим. В акустические признаки входят значения фундаментальной частоты, спектральное представление сигнала и так далее.
- Вокодер, переводящий акустические признаки в звуковую волну.
Для обучения duration и акустической моделей можно использовать скрытые марковские модели [3], глубокие нейронные сети или их рекуррентные разновидности [6]. Традиционный вокодер — это алгоритм, основанный на source-filter модели [3], которая предполагает, что речь — это результат применения линейного фильтра шума к первоначальному сигналу.
Общее качество речи классических параметрических методов оказывается достаточно низким из-за большого количества независимых предположений об устройстве процесса генерации звука.
Однако с приходом технологий глубокого обучения стало возможным обучать end-to-end модели, которые напрямую предсказывают акустические признаки по буквам. Например, нейронные сети Tacotron [4] и Tacotron 2 [5] принимают на вход последовательность букв и возвращают мел-спектрограмму с помощью алгоритма seq2seq [8]. Таким образом шаги 1—3 классического подхода заменяются одной нейросетью. На схеме ниже показана архитектура сети Tacotron 2, достигающей достаточно высокого качества звука.
Другим фактором существенного прироста в качестве синтезируемой речи стало применение нейросетевых вокодеров вместо алгоритмов цифровой обработки сигналов.
Первым таким вокодером была нейронная сеть WaveNet [9], которая последовательно, шаг за шагом, предсказывала значения амплитуды звуковой волны.
Благодаря использованию большого количества сверточных слоев с пропусками для захвата большего контекста и skip connection в архитектуре сети удалось достичь примерно 10%-го улучшения MOS по сравнению с моделями unit selection. На схеме ниже представлена архитектура сети WaveNet.
Главный недостаток WaveNet — низкая скорость работы, связанная с последовательной схемой сэмплирования сигнала. Эту проблему можно решить либо с помощью инженерной оптимизации для конкретной архитектуры железа, либо заменой схемы сэмплирования на более быструю.
Оба подхода были успешно реализованы в индустрии. Первый — в Tinkoff.ru, а в рамках второго подхода компания Google представила сеть Parallel WaveNet [10] в 2017 году, наработки которой используются в Google Assistant.
Примерные значения MOS для нейросетевых методов: 4,4—4,5 [5, 11], то есть синтезируемая речь практически не отличается от человеческой.
Достоинства параметрического синтеза:
- Естественное и плавное звучание при использовании end-to-end подхода.
- Большее разнообразие в интонациях.
- Использование меньшего объема данных по сравнению с моделями unit selection.
Недостатки:
- Низкая скорость работы по сравнению с unit selection.
- Большая вычислительная сложность.
Как работает синтез речи в Tinkoff
Как следует из обзора, методы параметрического синтеза речи, основанные на нейросетях, на текущий момент существенно превосходят по качеству подход unit selection и гораздо проще для разработки. Поэтому для построения собственного движка синтеза мы использовали именно их.
Для обучения моделей было использовано около 25 часов чистой речи профессионального диктора. Тексты для чтения были специально подобраны так, чтобы наиболее полно покрыть фонетику разговорной речи. Кроме того, чтобы добавить синтезу большее разнообразие в интонации, мы попросили диктора читать тексты с выражением, зависящим от контекста.
Архитектура нашего решения концептуально выглядит так:
- NLP frontend, в который входит нейросетевая текстовая нормализация и модель по расстановке пауз и ударений.
- Tacotron 2, принимающий на вход буквы.
- Авторегрессионный WaveNet, работающий в real time на CPU.
Благодаря такой архитектуре наш движок генерирует выразительную речь высокого качества в режиме реального времени, не требует построения фонемного словаря и дает возможность управлять ударениями в отдельных словах. Примеры синтезированных аудио можно прослушать, перейдя по ссылке.
Ссылки:
[1] A. J. Hunt, A. W. Black. Unit selection in a concatenative speech synthesis system using a large speech database, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio, R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System, Interspeech, 2017.
[3] H. Zen, K. Tokuda, A. W. Black. Statistical parametric speech synthesis, Speech Communication, Vol. 51, no. 11, pp. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous. Tacotron: Towards End-to-End Speech Synthesis.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions.
[6] Heiga Zen, Andrew Senior, Mike Schuster. Statistical parametric speech synthesis using deep neural networks.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Xiaochang Peng, Kyle Gorman, Brian Roark. Neural Models of Text Normalization for Speech Applications.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning with Neural Networks.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: A Generative Model for Raw Audio.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman, Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, Demis Hassabis. Parallel WaveNet: Fast High-Fidelity Speech Synthesis.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech.
[12] Dario Rethage, Jordi Pons, Xavier Serra. A Wavenet for Speech Denoising.
как технологии помогают людям с особенностями здоровья — Лайфхакер
Особенности зрения
Людям со слабым зрением или нарушением цветового восприятия бывает тяжело сосредоточиться на мелких деталях экрана или белом курсоре. Но и небольшой размер букв и кнопок, и слишком маленький курсор, и недостаточную контрастность экрана можно изменять под различные особенности зрения. А невидящим и слабовидящим пользователям поможет дублирование информации в другом формате, например аудио. Текст на веб‑странице или в окне программы можно не только посмотреть, но и послушать. Вот инструменты, которые помогут всё это сделать.
1. Экранная лупа
 Экранная лупа в Windows 10
Экранная лупа в Windows 10
Если графика, текст или кнопки плохо различимы, запустите экранную лупу и наведите её на нужный элемент. В Windows окошко с увеличенным полем можно закрепить вверху экрана — там будет отображаться крупнее всё, на что вы направите курсор. Ещё лупа даёт возможность увеличить фрагмент на размер всего дисплея. Её кратность можно настраивать и выбирать комфортный масштаб под ваше зрение.
Также лупа может перемещаться вслед за курсором. В последнем обновлении Windows, вышедшем в мае 2020 года, с помощью лупы можно воспроизвести текст: в инструмент встроили возможность чтения вслух с помощью электронного диктора.
2. Увеличение масштаба экрана и текста в интерфейсе
Чтобы не тратить время и силы на поиск мелких кнопок или подписей, воспользуйтесь настройками масштаба экрана. С ними можно сделать больше все элементы страницы или поддерживаемой программы: кнопки, надписи, иконки меню. Это поможет работать легче и удобнее.
3. Настройки цвета и размера курсора
 Изменение настроек курсора в Windows
Изменение настроек курсора в Windows
Мелкий указатель чёрного или белого цвета может быть плохо различим. Другое дело — розовый! Или ярко‑зелёный! Меняйте настройки стрелки мыши как вам нравится: увеличьте размер или выберите более яркий оттенок. Сделать крупнее можно и текстовый курсор. А в майском обновлении Windows 10 появилась возможность включить цветовые маркеры‑шашечки, которые помогают лучше видеть место курсора в строке.
4. Настройки контрастности и цветовые фильтры
 Изменение настроек контрастности в Windows
Изменение настроек контрастности в Windows
Серые экранные окна, белый фон и чёрные буквы. Это всё сливается в неразличимое пятно, если человек слабо видит или иначе различает цвета. Но выйти из ситуации несложно — цветовую гамму и настройки контрастности можно менять. Если сделать вкладки бирюзовыми, а фон — чёрным, границы между окнами будут чётче, а буквы станет легче различать.
5. Экранный диктор
Проговорит вслух все элементы окна, чтобы пользователи с особенностями зрения могли понять, на какой странице они находятся. Экранный диктор зачитывает тексты на веб‑страницах и в окнах программ на русском языке. Он распознаёт не только названия окон, тексты, кнопки и подписи к изображениям, но и всплывающие уведомления.
6. Синтезатор речи
Установите на компьютер программу, чтобы преобразовать любой письменный текст в аудио, или воспользуйтесь встроенным синтезатором речи в Windows 10. С его помощью люди с особенностями зрения могут прослушивать веб‑страницы и файлы в браузере Edge, а документы – в актуальных версиях Word. Нужный язык можно выбрать в настройках. Сейчас синтезаторы речи разрабатывают даже для диалектов или не самых распространённых языков. Например, есть отдельная программа для татарского языка.
7. Брайлевский дисплей
 Клавиатура Брайля
Клавиатура Брайля
Невидящие и слабовидящие пользователи при работе за компьютером могут воспринимать информацию с помощью тактильных ощущений. В таком случае на помощь придёт брайлевский дисплей. Это отдельное устройство, которое трансформирует информацию на экране в шрифт Брайля. Windows 10 поддерживает дисплеи Брайля и даёт возможность задавать разные команды для навигации и работы с приложениями и программами.
8. Диктовка и голосовые команды
 Настройки диктовки в macOS
Настройки диктовки в macOS
Стучать пальцами по клавиатуре не единственный способ набрать сообщение или написать e‑mail. Информацию можно наговорить голосом. Функция диктовки есть как в Windows (но пока не на русском, поддерживаются английский и некоторые другие языки), так и в macOS. Включите микрофон — и всё, что вы скажете, преобразуется в текст в режиме реального времени. Ещё в системе macOS голосом можно давать компьютеру некоторые команды: например, «открыть почту», «прокрутить вниз», «переместить курсор влево на пять пикселей».
Особенности слуха
Аудио на компьютере можно адаптировать под слабый слух и другие особенности здоровья. Для этого есть настройки громкости и звучания. Но при этом аудио- и видеоматериалы можно воспринимать не только на слух. Есть программы и функции, которые позволят вам добавить визуальное сопровождение и дадут возможность понимать, о чём идёт речь, без необходимости слышать звук.
9. Субтитры к слайдам, аудио- и видеоматериалам
 Субтитры, созданные автоматически в PowerPoint
Субтитры, созданные автоматически в PowerPoint
Самый простой способ расширить границы восприятия. Субтитры поддерживают большинство видеопроигрывателей и платформ, в том числе YouTube. Кстати, функция пригодится не только слабослышащим людям, но и тем, кто смотрит видео на другом языке и хочет подстраховаться. В PowerPoint тоже можно добавить субтитры к аудио или видео на слайде. Эта фишка выручит вас во время презентаций. Чтобы получить субтитры к материалу, наберите в поиске «создать файл с субтитрами формата vtt». Вы найдёте бесплатный софт, который поможет сделать файл с визуальным сопровождением звука.
10. Транслятор живой речи в субтитры
Субтитры — это отлично, но непонятно, что делать, если никто точно не знает, что скажет лектор на презентации. Решение есть — воспользоваться транслятором PowerPoint. Во время показа слайдов PowerPoint можно преобразовывать речь в субтитры в режиме реального времени. Подключите микрофон, чтобы система лучше распознавала слова. Всё сказанное выступающим будет мгновенно появляться на экране. Более того, если в аудитории есть люди, читающие на другом языке, можно подключить лайв‑перевод. Транслятор речи сразу доступен в PowerPoint для Microsoft 365 и Office 365. В более ранних версиях нужно установить отдельную бесплатную надстройку Presentation Translator.
11. Настройки звука
Увеличить громкость — банальный совет. Но настройки аудио позволяют адаптировать звук не только под слабый слух, но и под другие особенности. Возможно, вы не знали, что сделать звук громче можно только с одной стороны, чтобы сбалансировать восприятие. Кроме того, в настройках вы можете перевести стереозвук в формат моно. Это значит, что он станет одинаковым в обоих наушниках, и человек за компьютером будет слышать всё, даже если пользуется только одной стороной.
12. Визуальные оповещения
Сообщения об ошибке или другие уведомления часто сопровождаются звуковым сигналом. Это нужно, чтобы привлечь внимание пользователя к тому, что пытается сказать система. Но эти звуки могут слышать не все. Поможет изменение настроек: звук ошибки будет сопровождаться мерцанием экрана. В Windows есть возможность выбрать самый удобный способ визуальных оповещений: мигание заголовка активного окна, самого окна или всего экрана.
13. Настройки времени оповещений на экране
Некоторые уведомления пропадают с экрана слишком быстро. Пользователь мог бы их заметить и без звукового сигнала, если бы они оставались на дисплее дольше. Проблема легко решается: зайдите в настройки оповещений и увеличьте время, в течение которого уведомления остаются на экране. Можно настроить систему так, чтобы уведомления висели на дисплее до 5 минут.
Здесь можно узнать больше об инклюзивных инструментах Windows и Office, которые расширяют возможности для учёбы и работы.
Особенности восприятия
В полотне текста не всегда легко зацепиться глазами за нужную строчку. Особенно если у пользователя дислексия — избирательное нарушение способности к чтению. Кроме того, для людей с расстройствами аутистического спектра или проблемами с концентрацией дополнительные неудобства создают всплывающие окна и оповещения на веб‑страницах. Вот что поможет это скорректировать.
14. Иммерсивное чтение
 Режим иммерсивного чтения в OneNote для Windows 10
Режим иммерсивного чтения в OneNote для Windows 10
Непроглядное полотно текста можно сделать более удобным. Режим иммерсивного чтения поделит слова на слоги, увеличит отступы между строчками и шрифт и, если вам захочется, прочитает текст вслух. А чтобы пользователь не терял место, на котором остановился, инструмент выделяет его ярким цветом. Это помогает удерживать концентрацию и не путаться в тексте. Кроме того, в этом режиме может быть доступен визуальный словарь — наглядная иллюстрация слова картинкой. Иммерсивный формат полезен для детей, которые учатся читать: им будет проще выделять слоги, видеть разные части речи, понимать смысл прочитанного.
Режим иммерсивного чтения есть в Microsoft Word и заметках OneNote, в Outlook для веба, в браузере Microsoft Edge и в сообщениях Microsoft Teams. Ещё есть бесплатное приложение Office Lens. Оно может отсканировать любой текст и преобразовать его в иммерсивный формат.
15. Удаление отвлекающих факторов
Реклама и надоедливые баннеры, всплывающие на веб‑страницах, могут мешать концентрироваться. Чтобы не отвлекаться, активируйте фильтр, который будет их блокировать. Некоторые сайты имеют отдельный интерфейс для людей с особенностями восприятия. Многие программы или видеоигры заранее предупреждают о том, что в них присутствует мерцание экрана или быстрая смена изображений, которые могут вызвать реакцию у людей, склонных к эпилепсии.
16. Совместная работа людей с разными возможностями здоровья
Если над одним проектом работают люди с разными особенностями здоровья, нужна платформа без барьеров для восприятия. Например, в Microsoft Teams все смогут удалённо общаться, креативить, вести проекты и устраивать мозговые штурмы. Программа имеет возможность задавать настройки чтения, добавлять субтитры, использовать быстрые сочетания клавиш.
Особенности мобильности
Классические мышка и клавиатура требуют вовлечённой работы пальцами. Но такой режим подходит не всем. Чтобы удобнее управлять компьютером, пользователи с нарушениями подвижности могут воспользоваться специальными программами и более современными гаджетами.
17. Виртуальная клавиатура или клавиатура с большими клавишами
![]() Виртуальная клавиатура с датчиком для управления глазами
Виртуальная клавиатура с датчиком для управления глазами
У обычной клавиатуры довольно маленькие клавиши, которые требуют точных движений. Но есть виртуальные клавиатуры, где снижается или пропадает риск промахнуться. Набирать буквы можно кликом мышки, движением джойстика или даже глаз. Другой вариант — сенсорная клавиатура с большими кнопками. Клавиши реагируют на лёгкое прикосновение, и попасть по ним значительно проще. Пользователи могут размещать клавиатуру перед лицом и управлять ей с помощью носа.
18. Залипание клавиш
Чтобы выделить текст клавишами (Ctrl + A), нужно нажать две кнопки сразу. А чтобы вызвать диспетчер задач (Ctrl + Shift + Esc) — целых три. Горячих клавиш много, и работу с ними можно здорово облегчить. Для этого есть функция залипания клавиш. С этой настройкой система узнает команду, даже если пользователь нажмёт кнопки поочерёдно, одну за другой, а не все сразу.
19. Фильтрация ввода
Печатать текст сложнее, если руки совершают непроизвольные движения. Но здесь помогут настройки фильтрации ввода. Задайте параметры так, чтобы система игнорировала случайные повторы или воспринимала только длительное нажатие на клавишу. В этом случае, когда пользователь непреднамеренно набирает «ааааааа», система распознает это как «а». Можно выбрать удобное время нажатия.
20. Настройки мыши
Чтобы мышь не металась по экрану от любого случайного микродвижения, можно снизить её чувствительность в настройках. Или наоборот — повысить, чтобы человек, работающий за компьютером, прилагал меньше усилий. А если пользователю сложно позиционировать курсор с помощью мыши, это можно сделать на цифровом блоке клавиатуры. Достаточно просто активировать эту функцию в настройках манипулятора.
21. Альтернативные мышки
Мышка, к которой все привыкли, далеко не единственный вариант. Можно подобрать удобное устройство под разные особенности мобильности. Допустим, надеть на палец специальный датчик и управлять курсором взмахом руки. Или приобрести трекбол и менять положение стрелки на экране, вращая шарик. Кроме того, есть джойстики, которые удобно захватывать всей ладонью, а не только пальцами. Мышь ProPoint можно держать как пишущую ручку, расположив кисть на столе.
22. Системы контроля с помощью головы
 HeadMouse Nano для управления компьютером с помощью головы. Вторая часть (маленький круглый датчик) крепится на голову / www.orin.com
HeadMouse Nano для управления компьютером с помощью головы. Вторая часть (маленький круглый датчик) крепится на голову / www.orin.com
Чтобы совсем не использовать руки для управления компьютером, приобретите отдельную систему контроля. Например, HeadMouse Nano — это небольшой круглый сенсор, который крепится на лоб, оправу очков или головной убор. Гаджет соединяется с компьютером и распознаёт движения головы, меняя положение курсора. Похожим образом работает AbleNet TrackerPro. Эти устройства действуют на всех операционных системах, а ещё с их помощью можно управлять смартфонами и планшетами.
23. Управление глазами
 Набор текста на виртуальной клавиатуре при помощи глаз
Набор текста на виртуальной клавиатуре при помощи глаз
Если человек лишён возможности управлять компьютером с помощью тела, он может делать это глазами. Есть специальные гаджеты, распознающие движение зрачков, — eye trackers. «Айтрекеры» анализируют положение движения глаз и выполняют команды, следуя за взглядом. С их помощью можно набирать текст и выполнять другие операции.
Синтезаторы речи с русскими голосами. Лучший синтезатор речи. Как пользоваться синтезатором речи?
Сегодня синтезаторы речи, применяемые в стационарных компьютерных системах или мобильных устройствах, чем-то необычным уже не кажутся. Технологии шагнули далеко вперед и позволили воспроизвести человеческий голос. Как все это работает, где применяется, каков лучший речевой синтезатор и с какими потенциальными проблемами может столкнуться пользователь, смотрите ниже.
Что представляют собой речевые синтезаторы и где они применяются?
Синтезаторы речи представляют собой специальные программы, состоящие из нескольких модулей, которые позволяют переводить набранный на клавиатуре текст в обычную человеческую речь в виде звукового сопровождения.
Было бы наивно полагать, что сопутствующие библиотеки содержат абсолютно все слова или возможные фразы, записанные в студиях реальными людьми. Это просто физически невозможно. К тому же библиотеки фраз имели бы такой размер, что установить их даже на современные винчестеры большого объема, не говоря уже о мобильных девайсах, просто не представлялось бы возможным.
Для этого была разработана технология, получившая название Text-to-Speech (перевод текста в речь).
Наиболее широкое распространение синтезаторы речи получили в нескольких областях, к которым можно отнести самостоятельное изучение иностранных языков (программы нередко имеют поддержку в 50 языков и более), кода нужно услышать правильное произношение слова, прослушивание текстов книг вместо чтения, создание речевых и вокальных партий в музыке, использование их людьми с ограниченными возможностями, выдача поисковых запросов в виде озвученных слов и фраз и т. д.
Разновидности программ
В зависимости от области применения, все программы можно разделить на два основных типа: стандартные, непосредственно преобразующие текст в речь, и речевые или вокальные модули, применяемые в музыкальных приложениях.
Для более полного понимания картины рассмотрим оба класса, но больший упор будет сделан все-таки на синтезаторы речи в их непосредственном назначении.
Плюсы и минусы простейших речевых приложений
Что же касается преимуществ и недостатков программ такого типа, сначала рассмотрим все-таки недостатки.
Прежде всего нужно четко понимать, что компьютер — он и есть компьютер, который на данном этапе развития человеческую речь может синтезировать весьма приблизительно. В простейших программах зачастую наблюдаются проблемы с постановкой ударений в словах, пониженное качество звука, а в мобильных устройствах – повышенное энергопотребление, а иногда и несанкционированная загрузка речевых модулей.
Но и преимуществ хватает, ведь очень многие звуковую информацию воспринимают гораздо лучше, нежели визуальную. Удобство восприятия налицо.
Как пользоваться синтезатором речи?
Теперь несколько слов об основных принципах использования программ такого типа. Установить синтезатор речи любого типа можно без особых проблем. В стационарных системах используется стандартный инсталлятор, где основной задачей станет выбор поддерживаемых языковых модулей. Для мобильных девайсов установочный файл можно скачать из официального магазина или хранилища вроде Google Play или AppStore, после чего приложение инсталлируется в автоматическом режиме.
Как правило, при первом запуске никаких настроек, кроме установки языка по умолчанию, производить не нужно. Правда, иногда программа может предложить выбрать качество звучания (в стандартном варианте, применяемом повсеместно, частота дискретизации 4410 Гц, глубина 16 бит и битрейт 128 кбит/с). В мобильных устройствах эти показатели ниже. Тем не менее за основу берется определенный голос. С использованием стандартного шаблона произношения путем применения фильтров и эквалайзеров достигается звучание именно такого тембра.
В использовании можно выбрать несколько вариантов перевода текста: ввод текста вручную, озвучивание уже имеющего текста из файла, интеграция в другие приложения (например, веб-браузеры) с активацией выдачи поисковых результатов или прочтения текстового содержимого на страницах онлайн. Достаточно выбрать нужный вариант действий, язык и голос, которым все это будет произноситься. Многие программы имеют несколько разновидностей голосов: как мужских, так и женских. Для активации процесса воспроизведения обычно используется кнопка старта.
Если говорить о том, как отключить синтезатор речи, тут может быть несколько вариантов. В самом простом случае используется кнопка остановки воспроизведения в самой программе. В случае интеграции в браузер деактивация производится в настройках расширений или полным удалением плагина. А вот с мобильными устройствами, несмотря на непосредственное отключение, могут быть проблемы, о которых будет сказано отдельно.
В музыкальных программах настройки и ввод текста намного сложнее. Например, в приложении FL Studio есть свой речевой модуль, в котором можно выбрать несколько типов голосов, изменить настройки тональности, скорости воспроизведения и т. д. Для постановки ударений перед слогом используется символ «_». Но и такой синтезатор годится только для создания роботизированных голосов.
Но вот пакет Vocaloid от Yamaha относится к программам профессионального типа. Технология Text-to-Speech здесь реализована в наиболее полном объеме. В настройках, помимо стандартных параметров, можно выставить артикуляцию, глиссандо, использовать библиотеки с вокалом профессиональных исполнителей, составлять слова и фразы, подгоняя их под ноты, и еще кучу всего. Неудивительно, что пакет только с одним вокалом занимает порядка 4 Гб и более в установочном дистрибутиве, а после распаковки — вдвое-втрое больше.
Синтезаторы речи с русскими голосами: краткий обзор самых популярных
Но вернемся к самым простым приложениям и рассмотрим самые популярные из них.
RHVoice – по мнению большинства экспертов, лучший синтезатор речи, являющийся российской разработкой авторства Ольги Яковлевой. В стандартном варианте доступно три голоса (Александр, Ирина, Елена). Настройки просты. А само приложение может использоваться и как самостоятельная программа, совместимая с SAPI5, и как экранный модуль.

Acapela – достаточно интересное приложение, главной особенностью которого является почти идеальная озвучка текста более чем на 30 языках мира. В обычной версии, правда, доступен только один голос (Алена).
Vocalizer – мощное приложение с женским голосом Milena. Очень часто эта программа применяется в call-центрах. Имеется множество настроек постановки ударения, громкости, скорости чтения и установки дополнительных словарей. Главное отличие состоит в том, что речевой движок может встраиваться в программы вроде Cool Reader, Moon+ Reader Pro или Full Screen Caller ID.
Festival – мощнейшая утилита синтеза и распознавания речи, созданная для систем Linux и Mac OS X. Приложение поставляется с открытым исходным кодом и, помимо стандартных языковых пакетов, имеет поддержку даже финского языка и хинди.
eSpeak – речевое приложение, поддерживающее более 50 языков. Главным недостатком считается сохранение файлов с синтезированной речью исключительно в формате WAV, который занимает уж очень много места. Зато программа является кроссплатформенной и может использоваться даже в мобильных системах.
Проблемы с синтезатором речи в Google Android
При установке «родного» синтезатора речи от Google, пользователи постоянно жалуются на то, что он самопроизвольно включает загрузку дополнительных языковых модулей, что может не только занимать достаточно длительный промежуток времени, но еще и расходует трафик.
Избавиться от этого в Android-системах можно очень просто. Для этого используем меню настроек, далее переходим в раздел языка и голосового ввода, выбираем голосовой поиск и на параметре распознавания речи оффлайн нажимаем на крестик (отключение). Дополнительно рекомендуется почистить кэш приложений и перезагрузить устройство. Иногда может потребоваться в самом приложении отключить показ уведомлений.
Что в итоге?
Поводя некий итог, можно сказать, что в большинстве случаев рядовым пользователям подойдут самые простые программы. Во всех рейтингах лидирует RHVoice. Но для музыкантов, которые хотят добиться естественного звучания голоса, чтобы разница между живым вокалом и компьютерным синтезом не ощущалась на слух, лучше отдать предпочтение программам типа Vocaloid, тем более что для них выпускается множество дополнительных голосовых библиотек, а настройки имеют столько возможностей, что примитивные приложения, как говорится, и рядом не стояли.
Как слепой разработчик в одиночку создала синтезатор речи
Мы все, так или иначе, сталкивались с пользователями, имеющими проблемы зрения. Отвечающие за UI, не важно сайта, мобильного приложения или любого другого софта, скорее всего, знают про необходимость учитывать потребности таких людей и поэтому делали режимы повышенной контрастности, увеличенные шрифты и так далее.
А что, если пользователь совсем слепой и все эти режимы никак не упрощают его жизнь? Здесь на арену выходят программы для чтения экрана и синтезаторы звука, без которых им не обойтись. И вот про один из них я бы хотел вам сегодня рассказать.
Называется от RhVoice и упоминался в нескольких публикациях на Хабре. Но знаете ли вы, что многие считают его лучшим бесплатным синтезатором русской (и не только) речи, а написан он в одиночку полностью слепым разработчиком — Ольгой Яковлевой?
Сегодня восстанавливаем историческую справедливость и немного узнаем про сам синтезатор вообще, и Ольгу в частности.
Сразу раскроем все карты: гитхаб синтезатора
Код синтезатора распространяется бесплатно по GPL, а значит его может встроить в свой продукт любой желающий. Доступен на трех платформах: Windows, Linux и Android. Ведет разработку Ольга одна и работает в Linux. Лучшим (из опенсорсных) синтезатором русской речи, его считают сами пользователи и это не только люди с плохим зрением. В своей работе синтезатор использует статистический параметрический синтез и был основан на наработках уже существующих проектов, таких как HTS, и опубликованных научных исследованиях. Это гибридная глубокая нейронная сеть, работающая со скрытой марковской моделью. Задача таких сетей, это разгадка неизвестных параметров на основе наблюдаемых. Можно считать, что это простейшая Байесовская сеть. Сам HTS был основан на наработках другого проекта — HTK. Но нас тут больше всего интересует, что часть наработок была опубликована для свободного использования, включая описание алгоритмов и примененных техник.
Сам синтезатор позиционируется как средство для ежедневной работы. Его можно использовать и в более творческих целях вроде озвучивания книг, но все же лучше, когда их озвучивают люди.
Ольга начала свой проект почти 10 лет назад, когда стала изучать Linux и не нашла там удобного для себя синтезатора. Пишет весь код она сама, используя для этого специальный Брайлевский дисплей. Это специальное устройство предназначенное для отображения текстовой информации в виде шести точечных символов азбуки Брайля. Также в работе использует JAWS, программу для чтения с экрана, которая ведет свою историю со времен DOS и тоже созданную при активном участии слепого.
А теперь, когда вводные даны, давайте немного углубимся в мир синтезаторов речи.
Что же такое синтезатор речи и что в него входит?
Традиционно принято считать, что любой синтезатор состоит из двух частей: языковой компонент и компонент генерации речевого сигнала. Языковой компонент анализирует текст, получаемый от чтеца экрана. Его задача разбить текст на предложения, предложения на фразы, слова и слоги. В конце строится транскрипция всех слов и по ней создается карта звуков (как всем известно, не всегда как пишется, так и говорится). Разбор этот можно делать с разной глубиной проработки. У RhVoice, например, нет ресурсов для сложных операций вроде определения роли в предложении или части речи. Но в любом случае в конце разбора у нас получается набор звуков, которые должен собрать компонент генерации речевого сигнала, используя базу пред записанных звуков. Немного позже мы подробнее остановимся на каждом из компонентов.
Демонстрация работы с синтезатором
История Ольги
Ольга живет в Чебоксарах, закончила математический факультет Чувашского государственного университета и работает программистом. Как и все незрячие люди, она училась в специализированных школах. Сначала были 6 классов в школе Нижнего Новгорода, потому что на тот момент в Чебоксарах не было мест, куда бы принимали полностью слепых детей. Но спустя шесть лет все же получилось вернуться в родной город, и доучилась Ольга уже в Чебоксарах. Там же в школе, Ольга полюбила математику, что в дальнейшем позволило ей поступить на математический факультет. В какой-то момент она думала о поступлении на ИВТ, но тут свою роль сыграла неуверенность в собственных силах. Да и среди выпускников математического факультета было несколько незрячих, а на вступительном собеседовании декан сказал, что у них программистов готовят даже лучше, чем на ИВТ.
Первый опыт работы с компьютерами Ольга получила не в школе, а в университете, в библиотеку которого закупили специальные компьютеры, оборудованные для использования слепыми, с установленной программой JAWS (программа для чтения с экрана, ведущая свою историю аж с 1989 года). Там она изучала знаменитый учебник по Windows 95 от Сары Морли. Скорее всего, вы сейчас удивитесь, ибо что за такой знаменитый учебник, про который вы и не слышали ни разу? Ответ кроется в его названии: «Windows 95 для незрячих и слабовидящих». Основное отличие подобных учебников от знакомых всем нам, это акцент на описании различных объектов и вариантах управления ими. Так как незрячему человеку инструкция вида «щелкните мышкой на ниспадающий список и выберите нужный пункт меню» несколько бесполезна. Они не видят ни экран, ни курсор мышки и даже больше — не знает, как выглядит окно и ниспадающий список. Кстати, из-за этого возникает еще один неочевидный нюанс — незрячие люди могут оказаться заложниками битности используемого синтезатора. Так, лет пять назад, при переходе на Windows 8 многие столкнулись с отсутствием поддержки 64 bit приложений со стороны синтезаторов речи и перешли на RhVoice, где эта поддержка уже была реализована.
Но вернемся во времена, когда Ольга только начинала изучение новой для себя области. Синтезатором речи тогда выступала программа Digalo с голосом Nikolay. Это настолько каноничная связка, что результаты ее работы слышал абсолютно любой человек, выходивший в сеть. Его голос можно считать синонимом термина «робовойс», настолько плотно он вошел в интернет культуру и был использован в бесконечном количестве видео на ютубе. Вероятно, поэтому абсолютное большинств уверено, что Дигало это фамилия Николая.
Digalo Nikolay во всей красе
Начало работы над собственным проектом
Путешествие в мир синтезаторов началось для Ольги примерно в 2010 году с разработки драйвера NVDA (NonVisual Desktop Access) для синтезатора Festival. NVDA, это бесплатная программа экранного доступа, позволяющая слабовидящим и незрячим полноценно работать с компьютером. Подобный класс программ включает в себя синтезатор речи и возможность вывода на брайлевский дисплей.
Благодаря Festival Ольга погрузилась в мир синтезаторов речи и открыла для себя, что возможность заставить компьютер говорить есть не только у коммерческих компаний, но и у любого желающего. На тот момент уже существовало несколько открытых синтезаторов речи, которые, в основном, распространялись учеными изучавшими технологии речевого синтеза.
Поэтому первые свои эксперименты на основе трудов более опытных коллег, Ольга делала вокруг все того же Festival. Это академический синтезатор речи, созданный в 1995 году группой ученых во главе с Аланом Блэком. Они разрабатывали методы синтеза и на основе своих исследований сделали собственный синтезатор, который изначально был просто демонстрацией результатов их работы. Со временем к нему добавился не менее важный проект FestVox, позволяющие генерировать новые искусственные голоса, а сверху это было приправлено довольно неплохой документацией. В то время в Festival уже был русский голос Alexander с довольно неплохой речевой базой.
Что такое речевая база: в случае RhVoice это более тысячи специальных предложений, начитанных диктором с четким и безэмоциональным произношением. Предложения эти должны быть подобраны таким образом, чтобы в них содержались все дифоны, то есть все комбинации из двух фонем. И хорошо бы, чтобы по несколько раз каждая для большей вариативности. По воспоминаниям в первых версиях использовалось около 600 фраз. В дальнейшем, синтезатор из этих фонем может сформировать любое слово. По-английски этот метод называется unit selection, а у нас он известен как метод выбора речевых единиц. Да, не самый модный и молодежный, однако работающий надежно как утюг. Каждое предложение заносится в базу и анализируется: определяются звуки, их позиции в слогах, в словах, в предложениях. Классифицируются отдельные фонемы, их расположение относительно друг друга и так далее. Во время обратной операции, то есть синтеза речи, для каждой фонемы, полученной из транскрипции, вы просто выбираете наиболее подходящий (читай: близкий) пример из базы. Иногда удается найти строгое соответствие, иногда приходится довольствоваться максимально похожим. В мире филологов это называется теоретической и практической фонетикой и придумано было далеко не вчера. Поэтому заниматься синтезаторами речи без чтения учебников по фонетике нельзя. К слову, особенно хорошие учебники выходили в свое время у МГУ.
А где брать эти предложения? Можно написать самому, но это довольно тяжелая затея и есть два альтернативных пути. Можно взять заранее написанный кем-то текст, но это может нарушить авторские права или стоить отдельных денег. Поэтому авторы некоторых голосов используют тексты с википедии. Для больших языков вроде английского или русского, там можно легко найти необходимые примеры. Небольшим языкам в этом смысле не повезло. Например, с белорусской википедией такой трюк не прошел.
А в чем разница между языком и голосом? Ведь лет семь назад еще не было ни украинского, ни татарского диктора. Как же они появляются в синтезаторах?
Голоса в синтезаторах речи
Начинается все с анализа языка, который заключается в создании базы данных, где формально описывается фонетическая система этого языка. Такие базы могут быть уже сделаны кем-то и продаваться на рынке (за весьма хорошие деньги). В противном же случае приходится заниматься этим самостоятельно. Для анализа каждого языка разрабатывается отдельная программа и это может занимать до полутора лет работы, в зависимости от сложности языка. Например, итальянский язык очень прост, с точки зрения синтеза речи, а такие языки, как арабский и китайский крайне сложны. Но в среднем анализатор языка создается за год. После его готовности пишется уже голос. На это уходит уже около трех месяцев. Непосредственно запись самого диктора и прочая работа в студии занимает две-три недели. Это связано с тем, что качественно и красиво диктор может говорить примерно четыре часа в день. Дальше он устает и уже не звучит достаточно чисто. Если вы думаете, что это пижонство, то нет — к качеству этих записей предъявляются очень серьезные требования. Коммерческие компании проводят целые кастинги, отбирая не только по субъективной красоте голоса, но и по возможности использовать конкретный голос для конкретного языка в своем синтезаторе.
Затем запись сегментируется на фрагменты, согласно базе данных, а затем с помощью анализатора языка, эти фрагменты комбинируются вместе. То есть делается разбор, что вот это существительное, это глагол, это стоит рядом с этим, значит должно звучать вот так и подставляется максимально близкая фонема. Так что роль анализатора чрезвычайно важна: он должен учитывать не только расположение слогов в слове, но и расположение слов в предложении и знаки препинания. Все это влияет на произношение. В некоторых языках, одно и то же слово может произноситься по-разному, в зависимости от того что это — существительное или глагол.
Но это больше путь для коммерческих продуктов, у создателей которых есть ресурсы для подобных углубленных исследований. Независимые разработчики используют варианты попроще: без полной классификации по частям речи, а, например, только на уровне самостоятельное слово/предлог/союз и т.д. Ольга пошла еще более своим путем и написала свой языковой модуль на основе учебников и статей по фонетике. Благо есть достаточное количество опубликованных исследований на эту тему.
А вы не замечали, что у большинства синтезаторов сначала появляются женские голоса? Это не из-за предпочтений авторов, а из-за сложности разработки именно женского голоса. Женский голос более высокий по своей природе, а высокие частоты обрабатывать сложнее, чем низкие. И если удается создать женский голос, то мужской уж точно получится. А вот наоборот, не факт.
Мотивация к созданию своего синтезатора речи
В случае Ольги, это личная увлеченность темой и, даже, необходимость. А что в случае с коммерческими разработками? Как они решают, какой язык добавить, а какой нет? Ответ на все, деньги. Первый, очевидный, вариант, это анализ возможного рынка сбыта для новых голосов. Если по-простому: каков экономический уровень страны и есть ли у ее жителей деньги для покупки их продукта. Второй стимул уже более интересный. Это желание правительственных, или иных организаций, создать синтез речи для данного языка. Поэтому были сделаны синтезаторы речи для очень небольших языков, просто потому, что кто-то этим озаботился и выделил деньги на разработку. А, например, в скандинавских странах есть законы, что все письменные документы должны быть доступны незрячим и слабовидящим. Поэтому любая выходящая газета должна иметь свою аудиоверсию.
И для понимания порядка цен: разработка нового голоса, у частных компаний стоит примерно от десяти до сорока тысяч евро, в зависимости от сложности языка. Разработка модуля анализатора стоит в разы больше. Касательно RhVoice, тут у Ольги позиция принципиальная — ее проект будет бесплатным всегда. Тогда откуда тогда берутся деньги на дикторов? На начальных этапах находились добровольцы, предложившие помощь. У них была своя студия и они предложили оплатить диктора, так что Ольге оставалось только прислать список предложений для озвучания. Так в RhVoice появилось несколько новых языков. Потом к ней уже стали обращаться с конкретными запросами.
Но судьба дальнейшей разработки зависит от нахождения в свободном доступе необходимых ресурсов. Например, для украинского языка раньше не было открытого словаря ударений, а построить синтезатор не зная, как расставляются ударения невозможно. Сейчас он уже добавлен, но работа была проведена большая. Русскому языку в смысле доступности материалов повезло намного больше. А каноничный голос «Александр», так и вовсе был выложен в открытый доступ его создателем, благодаря чему Ольга смогла начать свои первые эксперименты по созданию синтезатора речи.
А как можно создать синтезатор, если ты совсем не знаешь язык? Условно ты знаешь русский и английский, а просят разработать арабский? Технических ограничений нет, главное, найти в интернете какие-то статьи и материалы о языке, о его структурах или даже проконсультироваться с филологом. Этого может хватить для разработки первоначального синтезатора речи. Ведь по большому счету, объем стартовой информации стандартен: список фонем, правила транскрипции от буквенного представления к произношению, детали о вспомогательных частях речи и т.д. Главная проблема будет в том, что разработчику никак не проверить результаты своей работы без участия носителя языка. А носителю языка надо дать не просто отзыв понятно/непонятно говорит, но и объяснить все тонкости и нюансы мест, где что-то пошло не по плану. В случае с RhVoice таким сложным языком стал татарский. С ним Ольге очень помогли филологи, с которыми ее связали представители Казанской библиотеки для слепых и слабовидящих, которые и инициировали эти работы. В ходе работы над синтезатором был даже составлен отдельный словарь корректного произношения заимствованных из русского языка слов. Чтобы заимствования звучали именно по правилам татарского языка, а не русского. И это хорошо, что такой словарь был составлен профессиональными филологами. Вот, например, для Киргизского такой словарь отсутствует и там очень много проблемных мест, пути разрешения которых пока не найдены просто технически.
Отдельная проблема — это расстановка ударений. В некоторых языках местоположение ударения можно предсказать, но в тех же русском и украинском без словаря никак не обойтись. Причем существуют алгоритмы предсказания ударений, на основе этих словарей. Но сделать такое, не обладая базовым словарем, невозможно.
Что в будущем? Вернее — каких новых функций, или доработки имеющихся, чаще всего просят пользователи? Безусловный лидер здесь это запрос на добавление того, или иного языка. Работа над новыми языками ведется, но как было сказано выше, это все не очень быстро и зависит от помощи внешних специалистов. А также многие просят улучшить качество звучания, чтобы еще больше приблизить его к естественному. Однако с доступным Ольге инструментарием, каких-то драматических улучшений здесь не будет. Правда от версии к версии, изменения в звук все же вносятся.
Сейчас Ольга надеется, что появятся готовые компоненты для нейронных сетей, написанные на низкоуровневых С-подобных языках, которые смогут обеспечить достаточное быстродействие на мобильных устройствах. А если заведется на мобилках, значит и на остальных платформах будет работать. Подобные проекты уже разрабатываются, и тогда она сможет переработать свой синтезатор. Другая важная проблема, которую предстоит решить — в RhVoice нет простого и понятного способа добавить свой язык и голос. Есть люди, которые готовы оплачивать эту работу, но проблема el classico: запросов много, Ольга одна, а как и в большинстве for fun проектов, кодовая база представляет собой настолько волшебный лес, что разобраться в ней кому-то, кроме создателя, задача гиблая. В большинстве подобных проектов разработчики предоставляют желающим набор инструментов и документацию, по которой, зная фонетику языка и обладая остальными знаниями, можно создавать свой модуль языка. Пока у Ольги нет ни того, ни другого. Но есть планы это сделать.
В завершении хочется сказать, что вот так, благодаря одному увлеченному человеку много лет делается очень хорошее дело. Больше вам спасибо, Ольга.
Если вам тоже хочется поблагодарить Ольгу за ее бескорыстный труд, а то и вовсе принять участие в развитии RhVoice, помочь проекту своими знаниями, наработками или спонсорством — то сделать это можно, связавшись с Ольгой через ее гитхаб.
Как работает синтез речи — Объясните, что материал
Криса Вудфорда. Последнее изменение: 8 апреля 2020 г.
Сколько времени пройдет до вашего компьютера
смотрит глубоко в твои глаза и со всеми
электронная искренность, которую он может собрать, бормочет эти три маленьких
слова, которые так много значат: «Я люблю тебя»! Теоретически это могло случиться
прямо сейчас: практически на каждом современном ПК с Windows есть речь
синтезатор (компьютеризированный голос, который превращает письменный текст в
речи), в основном, чтобы помочь людям с нарушениями зрения, которые
не может прочитать мелкий текст, напечатанный на экране.Как именно говорить
синтезаторы превращают письменную речь в устную? Рассмотрим подробнее!
Artwork: Люди не общаются, печатая слова на лбу, чтобы их могли прочитать другие люди, так почему же компьютеры? Благодаря таким агентам для смартфонов, как Siri, Cortana и «Окей, Google», люди постепенно привыкают к
идея говорить команды компьютеру и получать ответные ответы.
Что такое синтез речи?
Компьютеры выполняют свою работу в три отдельных этапа, называемых вводом (когда вы вводите
информацию, часто с помощью клавиатуры или
мышь), обработка (где
компьютер реагирует на ваш ввод, например, складывая некоторые числа
вы ввели или улучшили цвета на отсканированной фотографии), и
вывод (где вы можете увидеть, как компьютер обработал ваш
ввод, обычно на экране или распечатанный на бумаге).речь
синтез — это просто форма вывода, когда компьютер или другой
машина читает вам слова вслух реальным или искусственным голосом
проигрывается через громкоговоритель; технологию часто называют
преобразование текста в речь (TTS).
В говорящих машинах нет ничего нового — как ни странно, они восходят к
18 век, но компьютеры, которые обычно говорят со своими
операторы по-прежнему крайне редки. Правда, мы ездим на машинах с
с помощью компьютеризированных навигаторов, задействуйте компьютеризированные
коммутаторов, когда мы звоним в коммунальные службы и слушаем
компьютеризированные извинения на вокзалах, когда наши поезда
опаздываю.Но почти никто из нас не разговаривает с нашими компьютерами (с распознаванием голоса)
или сидеть и ждать, пока они ответят. Профессор Стивен Хокинг
был поистине уникальным человеком — во многих отношениях: можете ли вы думать
любого другого человека, известного тем, что он говорит компьютеризированным голосом?
Все, что может измениться в будущем, когда компьютерная речь станет
менее роботизированный и более человечный.
Как работает синтез речи?
Допустим, у вас есть параграф письменного текста, который вы хотите, чтобы ваш компьютер
говорить вслух.Как он превращает написанные слова в слова, которые вы можете
на самом деле слышишь? По сути, это три этапа, которые
Я буду называть текст для слов, слова для фонем и фонемы для звука.
1. Текст в слова
Читать слова звучит легко, но если вы когда-нибудь слушали чтение маленького ребенка
книга, которая была для них слишком сложной, вы знаете, что это не так
банально, как кажется. Основная проблема в том, что письменный текст
неоднозначно: одна и та же письменная информация часто может означать больше, чем
одно, и обычно вам нужно понять значение или сделать обоснованное предположение, чтобы правильно его прочитать.Итак, начальный этап синтеза речи, который принято называть
предварительная обработка или нормализация сводятся к уменьшению двусмысленности:
речь идет о том, чтобы сузить множество различных способов прочитать фрагмент текста
тот, который наиболее подходит.
Предварительная обработка включает
через текст и очистить его, чтобы компьютер делал меньше
ошибки, когда он действительно читает слова вслух. Такие вещи, как числа, даты, время,
сокращения, акронимы и специальные символы (символы валюты и т. д.)
нужно превратить в слова — и это сложнее, чем кажется.Число 1843 может обозначать количество предметов («одна тысяча восемьсот
и сорок три «), год или раз (» восемнадцать сорок три «), или
комбинация замков («один восемь четыре три»), каждая из которых читается
выходит немного иначе. Пока люди следят за чувством того, что
написали и вычислили произношение таким образом, компьютеры
обычно не имеют возможности сделать это, поэтому они должны использовать
методы статистической вероятности (обычно скрытые марковские модели) или нейронные сети (компьютерные программы, структурированные
как массивы клеток мозга, которые учатся распознавать закономерности), чтобы достичь
вероятное произношение вместо этого.Поэтому, если слово «год» встречается в том же предложении, что и «1843»,
Было бы разумно предположить, что это дата, и произнести «восемнадцать сорок три».
Если бы перед числами стояла десятичная точка («0,843»), их нужно было бы читать иначе, как «восемь четыре три».
Изображение: контекст имеет значение: синтезатору речи необходимо некоторое понимание того, что он читает.
Предварительная обработка также касается омографов, слов, произносимых по-разному.
в соответствии с тем, что они означают.Слово «читать» можно произносить
либо «красный», либо «тростниковый», поэтому предложение типа «Я прочитал
книга «сразу проблематична для синтезатора речи. Но если
он может понять, что предыдущий текст полностью в прошлом
время, распознавая глаголы в прошедшем времени («Я встал … Я взял
душ … позавтракал … книжку прочитал … «), это может сделать
разумное предположение, что «я прочитал [красную] книгу», вероятно, верно.
Аналогично, если предыдущий текст звучит так: «Я встаю … я принимаю душ …
Я завтракаю…«умные деньги должны быть на» Я прочитал [тростник]
книга «
2. Слова в фонемы
Разобравшись со словами, которые нужно сказать, синтезатор речи
теперь должен генерировать звуки речи, из которых состоят эти слова. В
теория, это простая проблема: все, что нужно компьютеру, — это огромная
алфавитный список слов и детали того, как произносить каждое из них
(примерно так же, как в обычном словаре, где произношение
указан до или после определения). Для каждого слова нам понадобится
список фонем, составляющих его звук.
Теоретически, если в компьютере есть словарь слов и фонем, все это
нужно сделать, чтобы прочитать слово, это найти его в списке, а затем
зачитайте соответствующие фонемы, верно? На практике это сложнее, чем кажется.
Как может продемонстрировать любой хороший актер, одно предложение можно прочитать по-разному, в зависимости от
значение текста, говорящий человек и эмоции, которые он хочет передать (в лингвистике эта идея известна как
просодия и это один
из самых сложных проблем для решения синтезаторов речи).В предложении можно прочесть даже одно слово (например, «читать»).
разными способами (как «красный» / «тростник»), потому что он имеет несколько значений. И даже в одном слове
данная фонема будет звучать по-разному в зависимости от фонем, стоящих до и после нее.
Альтернативный подход заключается в разбиении написанных слов на их графемы.
(письменные составляющие единицы, обычно состоящие из отдельных букв или слогов, составляющих слово), а затем
генерирование соответствующих им фонем с помощью набора простых правил.Это немного похоже на попытку ребенка прочитать слова, которые он никогда не слышал.
ранее встречались (метод чтения, называемый фонетическим
похож). Преимущество этого состоит в том, что компьютер может сделать разумную попытку прочитать любое слово, независимо от того,
или нет, это настоящее слово, хранящееся в словаре, иностранное слово или
необычное имя или технический термин. Недостаток в том, что языки
например, в английском есть большое количество неправильных слов, которые
произносятся совсем не так, как они написаны
(например, «полковник», что мы говорим как ядро, а не «кол-о-нелл»; и «яхта», которое произносится как «йот», а не «ях-т»)
— именно те слова, которые вызывают проблемы у детей и людей
с так называемой поверхностной дислексией (также называемой орфографической или зрительной дислексией).
3. Фонемы для звука
Хорошо, теперь мы преобразовали наш текст (нашу последовательность написанных слов) в список фонем (последовательность звуков
что нужно говорить). Но где взять основные фонемы, которые компьютер читает вслух при повороте?
текст в речь? Есть три разных подхода. Один — использовать записи людей, произносящих фонемы, другой —
компьютер для генерации фонем, генерируя базовые звуковые частоты (что-то вроде
музыкальный синтезатор), а третий подход — имитировать механизм человеческого голоса.
Конкатенативный
Синтезаторы речи, использующие записанные человеческие голоса, должны быть предварительно загружены
небольшие фрагменты человеческих звуков, которые они могут переставить. Другими словами,
программист должен записать множество примеров, когда человек говорит
разные вещи, разбейте сказанные предложения на слова и слова
в фонемы. Если имеется достаточно образцов речи, компьютер может
переставьте биты любым количеством разных способов, чтобы полностью создать
новые слова и предложения. Такой тип синтеза речи называется
конкатенативный (от латинских слов, которые просто означают связать биты
вместе в серию или цепочку).Поскольку он основан на записях людей,
конкатенация — наиболее естественный вид синтеза речи
и он широко используется машинами, которым есть что сказать
(например, корпоративные телефонные коммутаторы). Его главный недостаток заключается в том, что он ограничен одним голосом (одним
говорящий одного пола) и (как правило) одного языка.
Форманта
Если учесть, что речь — это просто звуковой паттерн с разной высотой тона
(частота) и громкость (амплитуда) — как шум, исходящий из
музыкальный инструмент — должно быть возможно сделать электронный
устройство, которое может генерировать любые звуки речи с нуля,
как музыкальный синтезатор.Этот тип синтеза речи известен
как формант, потому что форманты — это 3-5 ключевых (резонансных) частот звука, которые
голосовой аппарат человека генерирует и комбинирует звуки речи или пения. В отличие от синтезаторов речи, которые используют
конкатенация, которая ограничивается перестановкой заранее записанных звуков, формант
синтезаторы речи могут сказать абсолютно все, даже слова, которых не существует
или иностранных слов, с которыми они никогда не сталкивались. Это делает формантные синтезаторы хорошим выбором
для спутниковых (навигационных) компьютеров GPS, которые должны считывать многие тысячи
различных (и часто необычных) географических названий, которые было бы трудно запомнить.Теоретически формантные синтезаторы могут легко переключаться с мужского на женский голос (примерно удвоив частоту) или на детский голос (утроив его),
и они могут говорить на любом языке. На практике синтезаторы конкатенации теперь используют
огромные библиотеки звуков, поэтому они могут сказать почти все, что угодно.
более очевидное отличие состоит в том, что синтезаторы конкатенации
более естественны, чем формантные, которые все еще имеют тенденцию звучать относительно
искусственные и роботизированные.
Иллюстрация: Конкатенативный синтез против формантной речи.Слева: конкатенативный синтезатор строит речь из предварительно сохраненных фрагментов; слова, которые он произносит, представляют собой ограниченные перестановки этих звуков. Справа: Подобно музыкальному синтезатору, формантный синтезатор использует генераторы частоты для генерации любого звука.
Артикуляционный
Наиболее сложный подход к генерации звуков называется артикуляционным синтезом. Он означает, что компьютеры заставляют говорить путем моделирования удивительно сложного человеческого голосового аппарата. Теоретически это должно дать наиболее реалистичный и человечный голос
все три метода.Хотя многочисленные исследователи экспериментировали с имитацией человеческого голосового аппарата, артикуляционный синтез по-прежнему остается наименее изученным методом, в основном из-за его сложности. Наиболее сложной формой артикуляционного синтеза было бы создание робота с «говорящей головой» с движущимся ртом, который издает звук аналогично человеку, комбинируя
механические, электрические и электронные компоненты, если необходимо.
Для чего используются синтезаторы речи?
Фото: Будут ли люди разговаривать друг с другом в будущем? Теперь всевозможные публичные объявления делаются записанными или синтезированными голосами, управляемыми компьютером, но есть множество областей, куда даже самые умные машины боялись бы ступить.Представьте себе компьютер, пытающийся прокомментировать динамичное спортивное событие, например, родео,
например. Даже если бы он мог наблюдать и правильно интерпретировать действие, и даже если бы у него были все нужные слова, чтобы сказать,
может ли он действительно передать нужные эмоции? Фото Кэрол М. Хайсмит, любезно предоставлено Gates Frontiers Fund Wyoming Collection из архива Кэрол М. Хайсмит, Библиотека Конгресса, Отдел эстампов и фотографий.
Проработайте свой обычный день, и вы можете столкнуться со всеми видами
записанные голоса, но по мере развития технологий становится все труднее
выяснить, слушаете ли вы простую запись или
синтезатор речи.У вас может быть будильник, который будит вас, говоря время, возможно
используя грубый, формантный синтез речи. Если у вас есть говорящий GPS
система в вашем автомобиле, которая может использовать конкатенированную речь
синтез (если словарный запас относительно ограничен) или
формантный синтез (если голос настраивается и умеет читать географические названия).
Если у вас есть устройство для чтения электронных книг, возможно, у вас есть встроенный
рассказчик? Если у вас слабое зрение, вы можете использовать программу чтения с экрана.
который произносит слова вслух с экрана вашего компьютера (самый современный
На компьютерах с Windows есть программа под названием Экранный диктор, которую можно переключать
чтобы сделать именно это).Используете вы это или нет,
это скорее всего твой мобильный телефон
умеет выслушивать ваши вопросы и
ответ через интеллектуального личного помощника — Siri (iPhone), Cortana (Microsoft),
или Google Ассистент / Сейчас (Android). Если вы выходите на публику
транспорт, вы все время будете слышать записанные голоса, говорящие
объявления о безопасности или сообщении, что поезда и
следуют автобусы. Это простые записи людей … или они используют
составная, синтезированная речь? Посмотрим, сможешь ли ты понять это! Один действительно
Интересно использование синтеза речи в обучении иностранным языкам.Синтезаторы речи теперь настолько реалистичны, что их достаточно для
языковые студенты для использования на практике.
Кто изобрел синтез речи?
Говорящие компьютеры звучат как что-то из научной фантастики — и действительно,
самый известный пример синтеза речи именно такой. В
Новаторский фильм Стэнли Кубрика 2001: Космическая одиссея
(по роману Артура Кларка) компьютер под названием HAL
лихо болтает человеческим голосом и в конце
рассказ, переходит в печальное исполнение песни Daisy Bell (A
Bicycle Built for Two) как космонавт разбирает его.
Artwork: Speak & Spell — культовая электронная игрушка от Texas Instruments, которая познакомила целое поколение детей с синтезом речи в конце 1970-х годов. Он был построен вокруг TI
Микросхема TMC0281.
Вот краткий экскурс в историю синтеза речи:
- 1769: австро-венгерский изобретатель Вольфганг фон Кемпелен разрабатывает одну из первых в мире механических говорящих машин,
в котором используются сильфоны и компоненты волынки для создания грубых шумов, похожих на человеческий голос.Это рано
пример артикуляционного синтеза речи. - 1770-е: Примерно в то же время датский ученый Кристиан Кратценштейн, работая в России, создает механическую версию.
голосовой системы человека с использованием модифицированных органных труб, которые могут
произнесите пять гласных. В 1791 году он пишет книгу на эту тему под названием
Mechanismus der menschlichen Sprache nebst Beschreibung einer
sprechenden Maschine (Механизм человеческого языка с описанием говорящей машины). - 1837: английский физик и плодовитый изобретатель Чарльз Уитстон, долгое время увлекавшийся музыкальными инструментами и звуком, заново открывает
и популяризирует улучшенную версию говорящей машины фон Кемпелена. - 1928: Работает в Bell Laboratories, американский ученый.
Гомер В. Дадли
разрабатывает электронный анализатор речи под названием Vocoder
(не путать со знаменитым голосовым вокодером
использовался во многих электронных поп-записях 1970-х годов). Дадли превращает вокодер в водер, электронную речь
синтезатор управляется через клавиатуру. Писатель из The New
York Times видит устройство, продемонстрированное на Всемирной выставке 1939 года.
и заявляет: «Боже мой, это говорит!» Перейдите по ссылке на сайт Bell, чтобы услышать
образец слова Водера «Всем привет!» - 1940-е годы: другой американский ученый, Фрэнк Купер из Haskins Laboratories,
разрабатывает систему под названием Pattern Playback, которая может генерировать звуки речи из их частотного спектра. - 1953: Американский ученый Уолтер Лоуренс создает PAT (Parametric Artificial Talker), первый формантный синтезатор, который издает звуки речи, комбинируя четыре, шесть, а затем восемь формантных частот.
- 1958: Ученый из Массачусетского технологического института Джордж Розен разрабатывает новаторский артикуляционный синтезатор под названием DAVO (динамический аналог голосового тракта).
- 1960-е / 1970-е: снова в Bell Laboratories, Сесил Кокер
работает над улучшенными методами артикуляционного синтеза, в то время как Джозеф П. Олив
развивает конкатенативный синтез. - 1978: Texas Instruments выпускает свой синтезатор речи TMC0281 и запускает портативную электронную игрушку под названием
Speak & Spell, в котором в качестве учебного пособия используется грубый формантный синтез речи. - 1984: компьютер Apple Macintosh поставляется со встроенной функцией речи MacInTalk
синтезатор, широко используемый в популярных песнях, таких как Radiohead’s Fitter Happier и Paranoid Android. - 2001: AT&T представляет Natural Voices, естественный конкатентив
синтезатор речи на основе огромной базы данных звуковых образцов, записанных с реальных людей.Система широко используется в онлайн-приложениях, таких как веб-сайты, которые могут читать электронную почту вслух. - 2011: Apple добавляет Siri, «интеллектуального агента» с голосовым управлением, в свой iPhone (смартфон).
- 2014: Microsoft анонсирует Skype Translator, который может автоматически переводить разговорный разговор с одного языка на один из 40 других. В том же году Microsoft демонстрирует Cortana, собственную версию Siri.
- 2015: Amazon Echo, персональный помощник с голосовым программным обеспечением под названием Alexa, выходит в общий выпуск.
- 2016: Google присоединяется к клубу, выпустив Google Assistant, ответ на Siri и Cortana, позже включив его в Google Home.
Экспериментируйте сами!
Почему бы не испытать на себе немного синтеза речи? Вот два примера того, что первое предложение этого
статья звучит как зачитанная Microsoft Sam (синтезатор формантной речи, встроенный в Windows XP) и Microsoft Anna (более естественное звучание,
синтезатор формант в Windows Vista и Windows 7).Обратите внимание, насколько технология улучшилась всего за пять лет или около того между этими разными выступлениями.
синтезаторы выпускаются.
Сэм
Ваш браузер не поддерживает аудио элементы.
Анна
Ваш браузер не поддерживает аудио элементы.
Если у вас есть современный компьютер (Windows или Mac), в нем почти наверняка где-то скрывается синтезатор речи:
- Windows: Встроенная программа преобразования текста в речь называется Экранным диктором.
- Mac: вам понадобится VoiceOver
или на старых компьютерах Mac вы можете попробовать использовать PlainTalk. - Linux: Вы можете установить экспериментальные программы, включая eSpeak, основанный на синтезе формант.
- Web: Существуют различные веб-синтезаторы, с которыми можно играть в любой операционной системе, включая AT&T Natural Voices, FreeTTS на основе Java,
и надстройка Firefox под названием Text to Speech.
И не забывайте IBM Watson Text-to-Speech, который основан на облаке.
,
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|

.
| использование Языки документы образцы Лицензия
| eSpeak — это компактный программный синтезатор речи с открытым исходным кодом для английского и других языков, Linux и Windows. http://espeak.sourceforge.net eSpeak использует метод «формантного синтеза». Это позволяет предоставлять много языков в небольшом размере. Речь чистая и может использоваться на высоких скоростях, но она не такая естественная или плавная, как у более крупных синтезаторов, основанных на записях человеческой речи. eSpeak доступен как:
Характеристики.
Я регулярно использую eSpeak для прослушивания блогов и новостных сайтов. Я предпочитаю звук через домашнюю стереосистему, а не через небольшие компьютерные колонки, которые могут звучать довольно резко. Языки .Синтезатор речи eSpeak поддерживает несколько языков, однако во многих случаях это только начальные черновики, и для их улучшения требуется дополнительная работа. Для этих или других новых языков приветствуется помощь носителей языка. Пожалуйста, свяжитесь со мной, если хотите помочь. eSpeak выполняет синтез текста в речь для следующих языков, некоторые африкаанс, албанский, арагонский, армянский, болгарский, кантонский, Последняя разрабатываемая версия находится по адресу: espeakedit — это программа с графическим пользовательским интерфейсом, используемая для подготовки и компиляции данных фонем. Теперь он доступен для скачивания. Документация в настоящее время скудна, но если вы хотите использовать ее для добавления или улучшения языковой поддержки, дайте мне знать. История. Первоначально известная как , говорите и первоначально была написана для компьютеров Acorn / RISC_OS, начиная с 1995 года. Эта версия представляет собой усовершенствование и переписывание, включая ослабление исходной памяти и ограничений вычислительной мощности, а также с поддержкой дополнительных языков. |
.
5 лучших синтезаторов речи для роботизированных вокальных звуков
Синтез речи казался будущим в 1980-х (и до некоторой степени так и остается).
Здесь мы собрали пять наших любимых программных синтезаторов речи
(Изображение предоставлено: Future)
1. Роботизированный текст с VST Speek
VST Speek (или AU Speek) — это аккуратный инструмент, который имитирует программный автоматический Mouth (SAM) для Commodore 64. Введите то, что вы хотите, и сразу — мгновенные аркадные флюиды.Настоящее веселье начинается, когда вы меняете параметры Mouth и Throat.
(Изображение предоставлено: Future)
2. Полифоническая речь с нефом
Waldorf Nave для iPad может выполнять синтез полифонической речи. Инициализируйте новый патч и нажмите «Полный» в редакторе спектра. Нажмите кнопку «Инструменты» и введите новые слова в поле «Обсуждение». Вернитесь в раздел Wave, отрегулируйте Pitch, затем добавьте немного шума в раздел Spectrum для разборчивости.
(Изображение предоставлено в будущем)
3.Аркадная игра Speech
Plogue’s Chipspeech содержит аутентичные эмуляции речи чипа. Загрузите голос Отто Мозера, напечатайте что-нибудь в игровом стиле и используйте MIDI-клавиатуру, чтобы переходить по слогам. Избегайте желания играть мелодии для более аутентичного ощущения. Используйте более длинные ноты для более протяженных слогов.
(Изображение предоставлено: Future)
4. Пение нового уровня с Alter / Ego
Бесплатное Alter / Ego Plogue — это интересный способ добавить вокал, подобный чиптюну, к вашим произведениям.Чтобы использовать чистый голос Marie Ork для трели в стиле вокалоида, введите текст и попробуйте сыграть мелодию. Если это слишком далеко, нажмите «Модуляция» и измените настройки Humanize для большей реалистичности.
(Изображение предоставлено: Future)
5. Пение фонем с помощью Phonem
Огромный PPG Phonem Вольфганга Палма — доступный как плагин VST / AU или для iPad — представляет собой мощный вокальный синтезатор. Инициализируйте патч, а затем измените длину и переход каждого фонемы на панели слева направо.Наконец, используйте Time Envelope для изменения амплитуды и длины каждой ноты.
,